







Enterprise teams are rapidly adopting AI agent systems to automate complex workflows, but scaling these systems for high-volume workloads presents unique challenges. Traditional single-agent approaches often break down when faced with enterprise-level demands for reliability, security, and performance optimization.
This guide is for enterprise architects, AI engineers, and technical leaders who need to build robust AI agent systems that can handle thousands of concurrent operations while maintaining strict governance standards.
We’ll explore MCP architecture fundamentals and how this framework enables seamless multi-agent coordination across distributed enterprise environments. You’ll learn practical implementation strategies for building scalable AI infrastructure that grows with your organization’s needs. Finally, we’ll cover enterprise AI governance best practices that ensure your AI agent orchestration meets security requirements while delivering consistent performance at scale.
The shift from prototype to production-ready AI systems requires careful planning around scalable AI infrastructure design. Let’s examine how MCP implementation can transform your enterprise AI workloads from concept to reliable, high-performing reality.
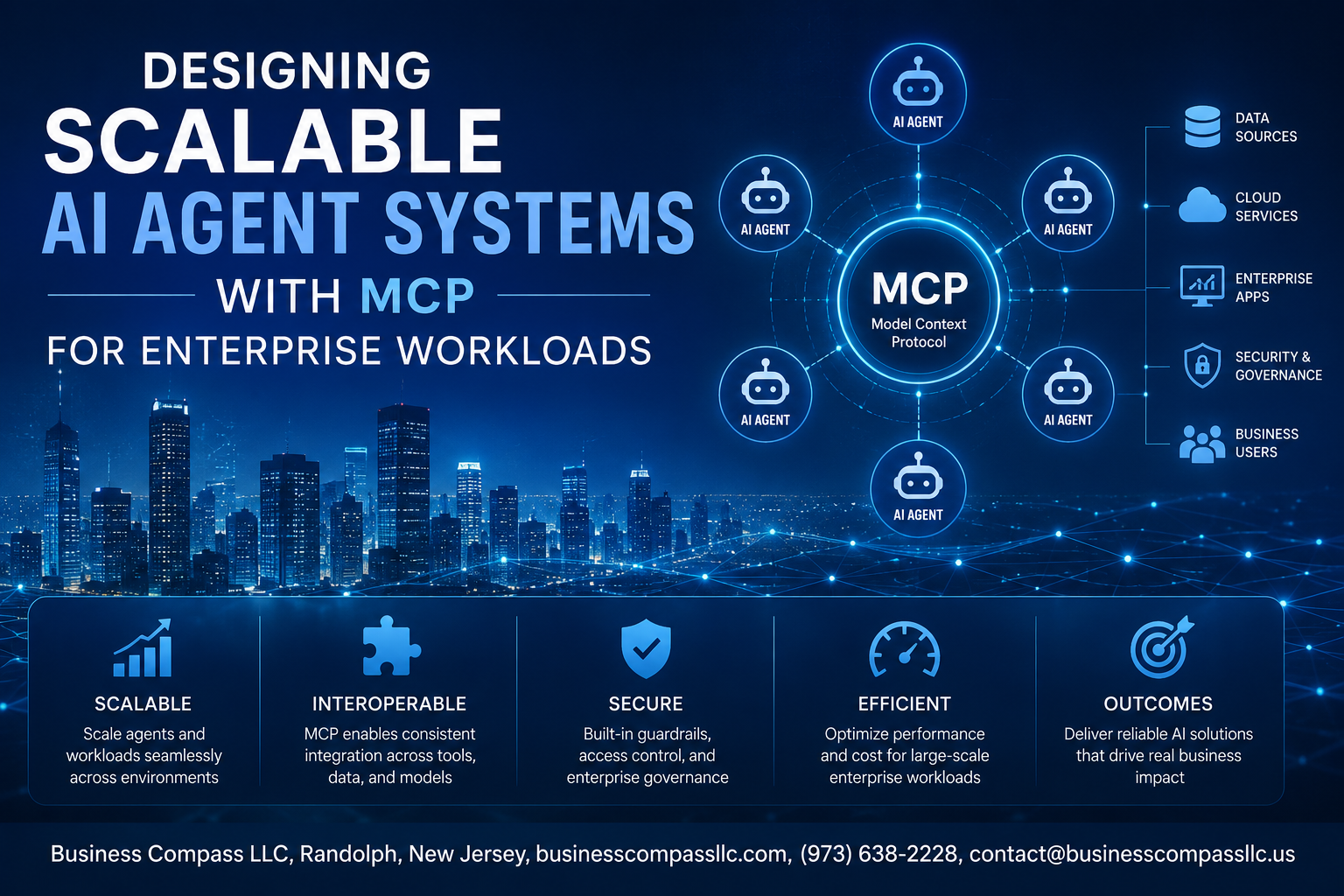
Understanding MCP Architecture for Enterprise AI Agent Systems

Core Components of Model Context Protocol Framework
MCP architecture centers around three fundamental building blocks that work together to create robust AI agent systems. The protocol layer establishes standardized communication channels between AI agents and external resources, enabling seamless data exchange across distributed environments. Resource providers act as bridges connecting agents to databases, APIs, and enterprise tools, while client applications orchestrate agent interactions and manage workflow execution. This modular design separates concerns effectively, allowing teams to scale individual components independently without disrupting the entire system.
Scalability Advantages Over Traditional AI Architectures
Traditional AI architectures often struggle with bottlenecks when multiple agents compete for shared resources or when workloads spike unexpectedly. MCP’s distributed approach changes this game completely by enabling horizontal scaling across multiple nodes and cloud regions. Each agent operates independently while maintaining context through the protocol layer, which means you can spin up additional agents during peak demand without complex reconfiguration. The stateless design ensures that failed agents can be replaced instantly without losing critical workflow state, making the entire system more resilient under enterprise AI workloads.
Enterprise-Grade Security and Compliance Features
Security isn’t an afterthought in MCP architecture – it’s built into every layer of the framework. The protocol includes end-to-end encryption for all agent communications, with support for enterprise identity providers like Active Directory and SAML. Access control mechanisms operate at the resource level, ensuring agents only interact with authorized data sources and APIs. Audit logging captures every agent action and decision path, creating the compliance trails that enterprise governance teams require. Role-based permissions integrate seamlessly with existing enterprise security policies, while data residency controls keep sensitive information within specified geographic boundaries.
Integration Capabilities with Existing Enterprise Infrastructure
MCP shines when connecting with the complex web of enterprise systems that organizations depend on daily. The framework includes pre-built connectors for major enterprise platforms like Salesforce, SAP, Microsoft 365, and ServiceNow, reducing integration time from months to weeks. API gateway compatibility ensures smooth communication with legacy systems that weren’t designed for AI integration. The protocol supports both synchronous and asynchronous communication patterns, allowing agents to work with real-time data streams or batch processing systems. Container orchestration platforms like Kubernetes can deploy and manage MCP components alongside existing microservices, creating a unified infrastructure approach that leverages current investments.
Planning Your AI Agent System Architecture

Assessing Enterprise Workload Requirements and Constraints
Enterprise AI agent systems must handle diverse workloads with varying computational demands, latency requirements, and data processing volumes. Start by mapping your organization’s specific use cases – customer service automation, document processing, predictive analytics, or real-time decision making. Each workload type carries unique performance expectations and resource constraints that directly impact your MCP architecture design decisions.
Analyze peak traffic patterns, concurrent user loads, and data throughput requirements across different business units. Consider regulatory compliance needs, data residency requirements, and integration points with existing enterprise systems. Document technical constraints like network bandwidth limitations, security protocols, and budget allocations for compute resources. This assessment creates the foundation for sizing your AI agent infrastructure appropriately.
Designing Modular Agent Components for Maximum Reusability
Build your AI agents using a microservices approach where each component handles specific functions like natural language processing, data retrieval, or task execution. Create standardized interfaces that allow agents to share common capabilities while maintaining specialized roles. This modular design enables rapid deployment of new agent types without rebuilding core functionality.
Design agent templates that can be customized for different departments while sharing underlying infrastructure. Implement configuration-driven behavior modifications so agents can adapt to various business contexts without code changes. Establish clear separation between agent logic, data processing, and communication layers to maximize component reusability across your enterprise AI ecosystem.
Establishing Communication Protocols Between Distributed Agents
Define standardized message formats and communication patterns that enable seamless interaction between agents deployed across different systems and locations. Implement asynchronous messaging queues to handle high-volume inter-agent communications without blocking operations. Choose protocols that support both real-time coordination and batch processing scenarios based on your enterprise AI scalability requirements.
Set up discovery mechanisms so agents can locate and connect with relevant services dynamically. Implement circuit breakers and retry logic to handle network failures gracefully in distributed environments. Create monitoring systems that track message flows and identify communication bottlenecks before they impact multi-agent coordination performance across your enterprise workloads.
Implementing Scalable MCP Infrastructure

Setting up distributed computing environments for agent deployment
Deploying enterprise AI agent systems requires a robust distributed computing foundation that can handle massive workloads across multiple nodes. Container orchestration platforms like Kubernetes provide the backbone for MCP architecture, enabling seamless agent distribution across cluster environments. Docker containerization ensures consistent deployment packages while maintaining isolation between different agent instances. Cloud-native solutions such as AWS EKS, Google GKE, or Azure AKS offer managed Kubernetes services that simplify cluster management and provide built-in security features. Multi-zone deployments protect against regional failures while geographic distribution reduces latency for global enterprise operations. Service mesh technologies like Istio enable secure communication between agents and provide observability into inter-service interactions. Resource allocation strategies must account for varying computational demands, with CPU-intensive reasoning tasks separated from memory-heavy data processing operations. Container registries store versioned agent images, enabling rapid rollbacks and A/B testing of new agent capabilities.
Configuring load balancing and auto-scaling mechanisms
Dynamic load balancing ensures optimal resource utilization across your MCP infrastructure while maintaining consistent response times during peak enterprise workloads. Application Load Balancers distribute incoming requests intelligently based on agent availability and current processing loads. Health checks continuously monitor agent responsiveness, automatically removing unhealthy instances from the rotation. Horizontal Pod Autoscaler (HPA) scales agent pods based on CPU, memory, or custom metrics like request queue depth. Vertical Pod Autoscaler optimizes resource allocation by adjusting CPU and memory limits based on historical usage patterns. Custom metrics from your MCP framework trigger scaling events when agent response times exceed defined thresholds. Predictive scaling analyzes historical patterns to proactively scale resources before demand spikes occur. Circuit breaker patterns prevent cascading failures by temporarily isolating overloaded agents. Rate limiting protects against traffic surges while ensuring fair resource allocation across different enterprise departments or use cases.
Establishing robust data pipelines for real-time processing
Enterprise AI agent systems demand high-throughput data pipelines capable of processing millions of events per second with minimal latency. Apache Kafka serves as the central nervous system for real-time data streaming, providing durable message queues that connect various enterprise systems to your MCP infrastructure. Stream processing frameworks like Apache Flink or Kafka Streams enable complex event processing and data transformations before agents consume the information. Data serialization formats such as Apache Avro or Protocol Buffers ensure efficient network transmission while maintaining schema evolution capabilities. Redis clusters provide ultra-fast caching layers that reduce database load and improve agent response times. Change Data Capture (CDC) systems automatically sync database updates to your streaming infrastructure, ensuring agents always work with fresh data. Data validation pipelines check incoming information for quality and completeness before routing to appropriate agent pools. Exactly-once processing guarantees prevent duplicate operations while maintaining data consistency across distributed agent clusters. Schema registries manage data format evolution without breaking existing agent implementations.
Creating fault-tolerant systems with automated recovery protocols
Building resilient MCP infrastructure requires comprehensive fault tolerance mechanisms that automatically detect and recover from various failure scenarios. Circuit breaker patterns isolate failing components while allowing healthy parts of the system to continue operating normally. Retry logic with exponential backoff prevents cascading failures when temporary network issues occur between agents and external services. Health check endpoints monitor agent status at multiple levels, from basic liveness probes to sophisticated business logic validation. Dead letter queues capture failed messages for later analysis and reprocessing, preventing data loss during system outages. Graceful degradation strategies maintain core functionality even when non-critical components fail, ensuring business continuity during partial system failures. Chaos engineering practices deliberately introduce failures to test recovery mechanisms and identify weak points before they impact production workloads. Automated backup and restore procedures protect against data corruption while enabling rapid recovery from catastrophic failures. Rolling updates minimize downtime by gradually replacing agent instances while maintaining service availability throughout deployment cycles.
Optimizing Performance for High-Volume Enterprise Operations

Implementing efficient resource allocation strategies
Dynamic resource scaling becomes critical when your AI agent systems handle thousands of concurrent requests during peak enterprise operations. Smart load balancing distributes workloads across available compute nodes while auto-scaling mechanisms spin up additional instances based on real-time demand metrics. Container orchestration platforms like Kubernetes automatically manage resource allocation, ensuring optimal CPU and memory usage across your MCP infrastructure. Resource pooling strategies allow multiple agents to share computational resources efficiently, reducing overall infrastructure costs while maintaining performance standards.
Reducing latency through intelligent caching and preprocessing
Response times directly impact user experience in enterprise AI applications, making intelligent caching strategies essential for high-performance operations. Multi-tier caching systems store frequently accessed data at various levels, from in-memory caches to distributed cache clusters, dramatically reducing database queries and API calls. Preprocessing pipelines prepare common data transformations and model predictions ahead of time, enabling near-instantaneous responses for routine agent tasks. Edge computing deployment brings processing closer to end users, while content delivery networks cache static assets and model artifacts across geographic locations for faster global access.
Monitoring system performance with real-time analytics dashboards
Real-time visibility into your AI agent system performance enables proactive optimization and prevents bottlenecks before they impact users. Comprehensive monitoring dashboards track key metrics including request throughput, response latency, error rates, and resource utilization across all system components. Advanced analytics identify performance patterns and predict scaling requirements based on historical usage data and business cycles. Custom alerting systems notify operations teams when performance thresholds are exceeded, while automated remediation scripts can restart failed services or trigger emergency scaling procedures to maintain service availability during unexpected load spikes.
Managing Multi-Agent Coordination and Workflow Orchestration

Designing Agent Communication Patterns for Complex Workflows
Effective multi-agent coordination starts with establishing clear communication protocols that prevent bottlenecks in enterprise environments. Design asynchronous message passing systems using event-driven architectures where agents subscribe to relevant channels based on their capabilities and current workload. Implement standardized message formats with metadata that includes priority levels, deadlines, and resource requirements. Create communication hubs that route messages intelligently between agents while maintaining audit trails for compliance. Use circuit breaker patterns to handle agent failures gracefully and prevent cascading system disruptions.
Implementing Conflict Resolution Mechanisms for Competing Agents
Build robust arbitration systems that handle resource contention when multiple agents compete for the same enterprise resources. Design voting mechanisms where agents can negotiate task ownership based on their current capacity, expertise level, and historical performance metrics. Implement timeout protocols that automatically reassign tasks if agents become unresponsive during critical operations. Create escalation pathways that involve human oversight for high-stakes decisions requiring business judgment. Use consensus algorithms like Raft or PBFT for distributed decision-making across AI agent systems operating in different geographical locations.
Creating Dynamic Task Distribution Algorithms
Deploy intelligent load balancing that considers real-time agent performance, specialization areas, and current workload distribution across your scalable AI infrastructure. Implement machine learning models that predict task completion times based on historical data and agent characteristics. Use weighted round-robin algorithms that factor in agent capabilities, response times, and success rates for similar tasks. Create adaptive algorithms that learn from past assignments and optimize future distributions automatically. Build failover mechanisms that redistribute tasks seamlessly when agents experience performance degradation or become unavailable.
Establishing Priority Queues for Critical Enterprise Processes
Structure hierarchical queue systems that ensure mission-critical enterprise AI workloads receive immediate attention while maintaining efficient processing of routine tasks. Implement dynamic priority adjustment based on business rules, SLA requirements, and real-time market conditions. Use time-based escalation where task priorities increase automatically as deadlines approach. Create dedicated fast lanes for emergency requests that bypass normal queue processing. Build monitoring dashboards that provide visibility into queue depths, processing times, and potential bottlenecks across your AI agent orchestration platform.
Ensuring Enterprise Security and Governance

Implementing role-based access controls for agent operations
Enterprise AI agent systems need granular permission structures that define what each agent can access and execute. Role-based access controls (RBAC) create security boundaries by assigning specific permissions to agent roles rather than individual instances. Start by categorizing agents into functional groups – data processors, decision makers, and interface handlers – then map each group to appropriate resource access levels. Configure authentication tokens with time-based expiration and implement dynamic permission escalation for complex workflows. MCP architecture supports fine-grained access controls through its protocol layer, allowing administrators to restrict agent communication channels and server connections based on operational requirements.
Establishing audit trails for compliance and monitoring
Comprehensive logging captures every agent action, decision pathway, and data interaction across your enterprise AI governance framework. Implement centralized audit logging that records agent-to-agent communications, resource access attempts, and workflow execution details with timestamp precision. Store logs in immutable formats with cryptographic integrity verification to meet regulatory compliance standards. Create real-time monitoring dashboards that alert administrators to unusual agent behaviors or access pattern anomalies. Structure audit trails to support forensic analysis and compliance reporting, ensuring your MCP implementation meets industry regulations like SOX, HIPAA, or GDPR requirements.
Creating data encryption protocols for sensitive information
Protect enterprise data through multi-layered encryption strategies that secure information both in transit and at rest. Implement end-to-end encryption for agent communications using TLS 1.3 protocols and rotate encryption keys regularly through automated key management systems. Encrypt sensitive data stores with AES-256 encryption and maintain separate encryption domains for different security classifications. Design agent protocols that never expose plaintext sensitive data during processing, using encrypted computation techniques where possible. Configure MCP servers with certificate-based authentication and establish secure channels for high-value data exchanges between agent systems and enterprise databases.
Designing backup and disaster recovery procedures
Build resilient backup strategies that protect both agent configurations and operational data from system failures or security incidents. Create automated backup schedules for agent state information, workflow definitions, and training data with geographic distribution across multiple data centers. Implement hot-standby systems that can immediately take over agent operations during primary system failures. Test disaster recovery procedures regularly through controlled failover exercises that validate recovery time objectives and data integrity. Design backup systems that maintain agent operational continuity while preserving security controls and access permissions during recovery scenarios.

Building successful AI agent systems for enterprise workloads requires a solid foundation in MCP architecture and careful planning from the start. The key is understanding how to design your system to handle growing demands while maintaining security and governance standards. Getting your infrastructure right means thinking about scalability, performance optimization, and how multiple agents will work together seamlessly.
The real challenge comes down to balancing performance with control. Your AI agents need to operate efficiently at scale while staying within your company’s security boundaries. Focus on setting up proper workflow orchestration and monitoring systems early on. This approach will save you headaches later when you’re dealing with hundreds or thousands of agent interactions. Start small, test thoroughly, and build your way up to enterprise-level deployments with confidence.








