







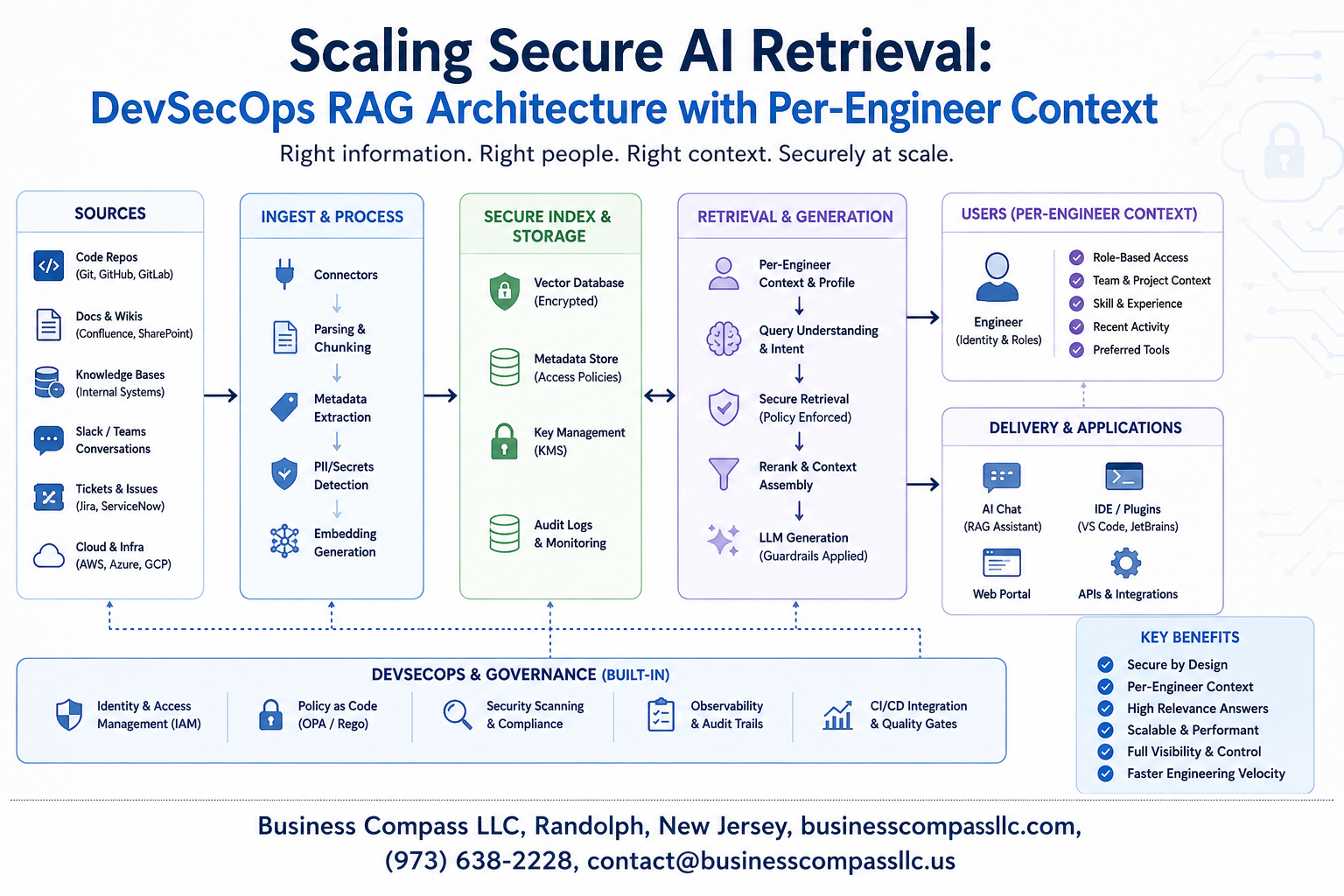
Modern enterprises face a critical challenge: how to deploy AI retrieval systems that scale securely while maintaining individual engineer productivity. This guide explores scaling secure AI retrieval through a comprehensive DevSecOps RAG architecture that delivers per-engineer context without compromising security or performance.
Who this is for: Engineering leaders, DevSecOps teams, and AI architects building production-ready retrieval systems in enterprise environments where security, compliance, and developer experience matter equally.
We’ll walk through building a DevSecOps framework implementation that integrates security from day one, designing scalable AI infrastructure patterns that grow with your team, and implementing AI security best practices that protect sensitive data while keeping engineers productive. You’ll learn practical approaches to RAG performance optimization, AI monitoring solutions, and creating robust security controls that actually work in real-world scenarios.
By the end, you’ll have a clear roadmap for deploying enterprise RAG systems that balance the competing demands of security, scale, and developer velocity.
Understanding RAG Architecture for Enterprise AI Security

Core components of Retrieval-Augmented Generation systems
RAG architecture combines large language models with external knowledge bases to deliver contextually relevant responses. The system includes four essential components: a vector database for storing embeddings, retrieval mechanisms for finding relevant documents, language models for response generation, and orchestration layers managing data flow. Knowledge bases store enterprise documentation, code repositories, and domain-specific content, while embedding models convert text into searchable vectors. The retrieval component uses semantic search to identify relevant information, and the generation component synthesizes responses using both retrieved context and model knowledge.
Security vulnerabilities in traditional RAG implementations
Traditional RAG implementations expose organizations to data leakage, prompt injection attacks, and unauthorized access to sensitive information. Vector databases often lack proper access controls, allowing engineers to retrieve confidential data outside their scope. Embedding models can inadvertently encode sensitive information, creating privacy risks during knowledge base searches. Enterprise AI security requires implementing role-based access controls, data classification systems, and secure retrieval pathways. Many deployments fail to implement proper authentication mechanisms, leading to cross-team data exposure and compliance violations in regulated industries.
Benefits of context-aware AI retrieval for development teams
Per-engineer context implementation transforms development workflows by providing personalized, secure access to relevant technical knowledge. Engineers receive responses tailored to their specific projects, permissions, and team responsibilities without accessing unauthorized information. This approach reduces information overload while maintaining strict security boundaries. Development teams experience faster problem resolution, improved code quality, and enhanced collaboration through contextually relevant AI assistance. Secure AI retrieval enables organizations to leverage collective knowledge while protecting intellectual property and maintaining regulatory compliance across distributed engineering teams.
DevSecOps Integration Strategy for AI Systems

Embedding security controls throughout the AI development lifecycle
Security controls must be woven into every stage of AI development, from initial model training through production deployment. Start by implementing secure coding practices that include threat modeling for RAG architecture components, establishing secure data pipelines with encryption at rest and in transit, and creating approval workflows for model updates. Version control systems should track not just code changes but also model artifacts, training datasets, and configuration parameters. Build automated security gates that prevent vulnerable dependencies from entering the AI pipeline, while maintaining audit trails for all data access patterns. The DevSecOps AI integration approach requires establishing clear boundaries between development, staging, and production environments, with each environment maintaining its own security posture and access controls.
Automated vulnerability scanning for AI model dependencies
Modern RAG systems depend on complex software stacks that require continuous vulnerability assessment. Deploy automated scanning tools that check Python packages, machine learning frameworks, and container images for known security issues before they reach production. Set up dependency management workflows that automatically update vulnerable packages while maintaining compatibility with existing AI models. Create custom security rules that flag suspicious package installations or unusual dependency patterns that could indicate supply chain attacks. Your scanning pipeline should integrate with CI/CD workflows to block builds containing high-severity vulnerabilities, while providing developers with clear remediation guidance. Regular scanning schedules should cover not just application dependencies but also the underlying infrastructure components supporting your AI retrieval systems.
Continuous monitoring of data retrieval patterns
Real-time monitoring of RAG data access patterns reveals both security threats and performance bottlenecks before they impact users. Implement logging mechanisms that capture query patterns, response times, and data source interactions without exposing sensitive information. Build dashboards that track unusual retrieval behaviors such as excessive data requests, unauthorized access attempts, or queries targeting sensitive document collections. Establish baseline performance metrics for normal operation, then configure alerts when patterns deviate significantly from expected behavior. The monitoring system should correlate user actions with data access patterns to identify potential insider threats or compromised accounts. Machine learning algorithms can help detect anomalous retrieval patterns that human operators might miss, providing an additional security layer for your enterprise AI security infrastructure.
Compliance frameworks for AI-powered development tools
Enterprise AI systems must align with industry regulations while supporting developer productivity and innovation. Design your RAG architecture to meet SOC 2, ISO 27001, and industry-specific requirements like HIPAA or PCI DSS depending on your data types. Create documentation templates that capture AI model governance decisions, data lineage information, and security control implementations. Establish regular compliance audits that review access logs, security configurations, and data handling procedures across your AI infrastructure. Build automated reporting capabilities that generate compliance artifacts without manual intervention, reducing the administrative burden on development teams. Your compliance framework should include clear guidelines for data retention, model explainability, and incident response procedures specific to AI-powered development tools.
Per-Engineer Context Implementation Framework

Role-based access control for AI knowledge bases
Engineering teams need granular access controls that align with organizational hierarchies and project clearances. RBAC frameworks for RAG architecture implement multi-layered permissions where senior engineers access comprehensive knowledge bases while junior developers receive filtered, role-appropriate content. Security policies enforce automatic privilege escalation workflows and temporary access grants for cross-team collaboration scenarios.
Dynamic context filtering based on project assignments
Smart filtering mechanisms automatically adjust AI retrieval scope based on active project assignments and security clearances. Engineers working on frontend development receive relevant UI frameworks and design patterns while backend specialists access database schemas and API documentation. The system tracks project lifecycle changes and updates context boundaries in real-time, preventing unauthorized exposure to sensitive codebases.
Personal workspace isolation within shared AI systems
Isolated environments protect individual engineer workflows while maintaining shared infrastructure efficiency. Each engineer operates within dedicated virtual boundaries that prevent cross-contamination of sensitive queries and responses. Workspace containers include personal conversation histories, customized retrieval preferences, and project-specific knowledge graphs that remain completely segregated from peer environments.
Audit trails for individual engineer AI interactions
Comprehensive logging captures every AI interaction with detailed attribution and context metadata. Audit systems track query patterns, response accuracy ratings, and knowledge base access attempts across all engineering activities. Compliance frameworks automatically generate reports showing data lineage, security violations, and usage analytics that support regulatory requirements and internal security assessments.
Scalable Infrastructure Design Patterns

Containerized RAG Deployment Architectures
Container orchestration platforms like Kubernetes enable elastic scaling of RAG components through microservices architecture. Deploy vector databases, embedding services, and retrieval engines as independent containers with defined resource limits and health checks. Use Helm charts for consistent deployments across development, staging, and production environments while maintaining configuration as code principles.
Load Balancing Strategies for High-Volume AI Requests
Implement intelligent load balancing using weighted round-robin algorithms that account for model complexity and processing time. Deploy API gateways with rate limiting and circuit breakers to prevent system overload during peak usage. Geographic load distribution ensures low-latency responses by routing requests to the nearest regional clusters hosting your RAG infrastructure.
Database Partitioning for Engineer-Specific Contexts
Horizontal database sharding based on engineer identifiers creates isolated data segments while maintaining query performance. Implement consistent hashing algorithms to distribute user contexts across multiple database nodes. Use read replicas for frequently accessed knowledge bases and write-through caching layers to minimize retrieval latency for per-engineer context queries in your scalable AI architecture patterns.
Security Controls and Data Protection Measures

End-to-end encryption for AI retrieval pipelines
RAG architecture demands robust encryption throughout the entire data flow. Implement TLS 1.3 for data in transit and AES-256 encryption for data at rest. Encrypt vector embeddings and metadata using field-level encryption to protect sensitive code snippets. Deploy hardware security modules (HSMs) for key management and establish secure key rotation policies. Create encrypted channels between retrieval components, ensuring AI service access points maintain cryptographic integrity across distributed infrastructure.
Zero-trust authentication for AI service access
Zero-trust models require continuous verification for every AI system interaction. Deploy multi-factor authentication (MFA) with certificate-based access controls for engineer endpoints. Implement OAuth 2.0 with PKCE for secure API access and JWT tokens with short expiration windows. Create identity-based access policies that validate user context, device compliance, and network location before granting retrieval permissions. Establish micro-segmentation boundaries around AI services and enforce least-privilege access principles.
Data classification and handling policies
Enterprise AI security depends on comprehensive data classification frameworks. Tag code repositories by sensitivity levels: public, internal, confidential, and restricted. Implement automated scanning to identify personally identifiable information (PII), intellectual property, and regulatory-protected data. Create retention policies that automatically purge sensitive embeddings based on classification tiers. Establish data lineage tracking to monitor how classified information flows through RAG pipelines and maintain compliance audit trails.
Privacy-preserving techniques for sensitive code repositories
Protect proprietary codebases using differential privacy and homomorphic encryption techniques. Deploy federated learning approaches that keep sensitive code local while sharing anonymized insights. Implement k-anonymity models for code similarity searches and use synthetic data generation for training embeddings. Create privacy budgets that limit information leakage through repeated queries. Establish secure multi-party computation protocols for collaborative development scenarios while maintaining per-engineer context isolation and preventing data reconstruction attacks.
Performance Optimization and Monitoring Solutions

Real-time metrics for RAG system responsiveness
Monitoring RAG architecture performance requires tracking query latency, vector search times, and embedding generation speeds. Key metrics include response time percentiles, token throughput rates, and concurrent user capacity. Real-time dashboards should display retrieval accuracy scores, context relevance ratings, and system resource utilization across distributed components to ensure optimal AI system performance.
Cost optimization strategies for large-scale deployments
Enterprise RAG deployment costs can be controlled through intelligent caching strategies, vector database optimization, and efficient embedding model selection. Implement tiered storage for frequently accessed documents, use compression techniques for vector indexes, and deploy smaller language models for simple queries. Auto-scaling policies based on demand patterns help reduce infrastructure expenses while maintaining scalable AI architecture performance.
Automated scaling based on engineering team demand
DevSecOps AI integration requires dynamic scaling mechanisms that respond to engineering workload patterns. Configure horizontal pod autoscaling for retrieval services, implement queue-based processing for batch operations, and use predictive scaling algorithms based on historical usage data. Per-engineer context systems benefit from dedicated resource pools that automatically expand during peak development cycles and contract during low-activity periods.
Quality assurance testing for AI-generated responses
AI monitoring solutions must include automated quality checks for response accuracy, relevance, and security compliance. Implement continuous testing pipelines that evaluate retrieval precision, answer completeness, and potential data leakage scenarios. Use A/B testing frameworks to compare model performance, establish baseline quality metrics for different query types, and maintain feedback loops that improve RAG performance optimization over time through iterative refinement processes.

Enterprise AI systems need robust security foundations to handle sensitive data while delivering personalized experiences. RAG architecture combined with DevSecOps practices creates a powerful framework where each engineer gets tailored context without compromising organizational security. The per-engineer implementation approach ensures teams can access relevant information while maintaining strict data boundaries and audit trails.
Building scalable infrastructure with proper security controls isn’t just about protecting data—it’s about creating sustainable AI systems that grow with your organization. Start by implementing the core DevSecOps pipeline, then gradually add per-engineer context layers while monitoring performance metrics. Your AI retrieval system should feel seamless to users while running on bulletproof security underneath. Take the first step by auditing your current AI architecture and identifying where these security patterns can strengthen your existing workflows.








