







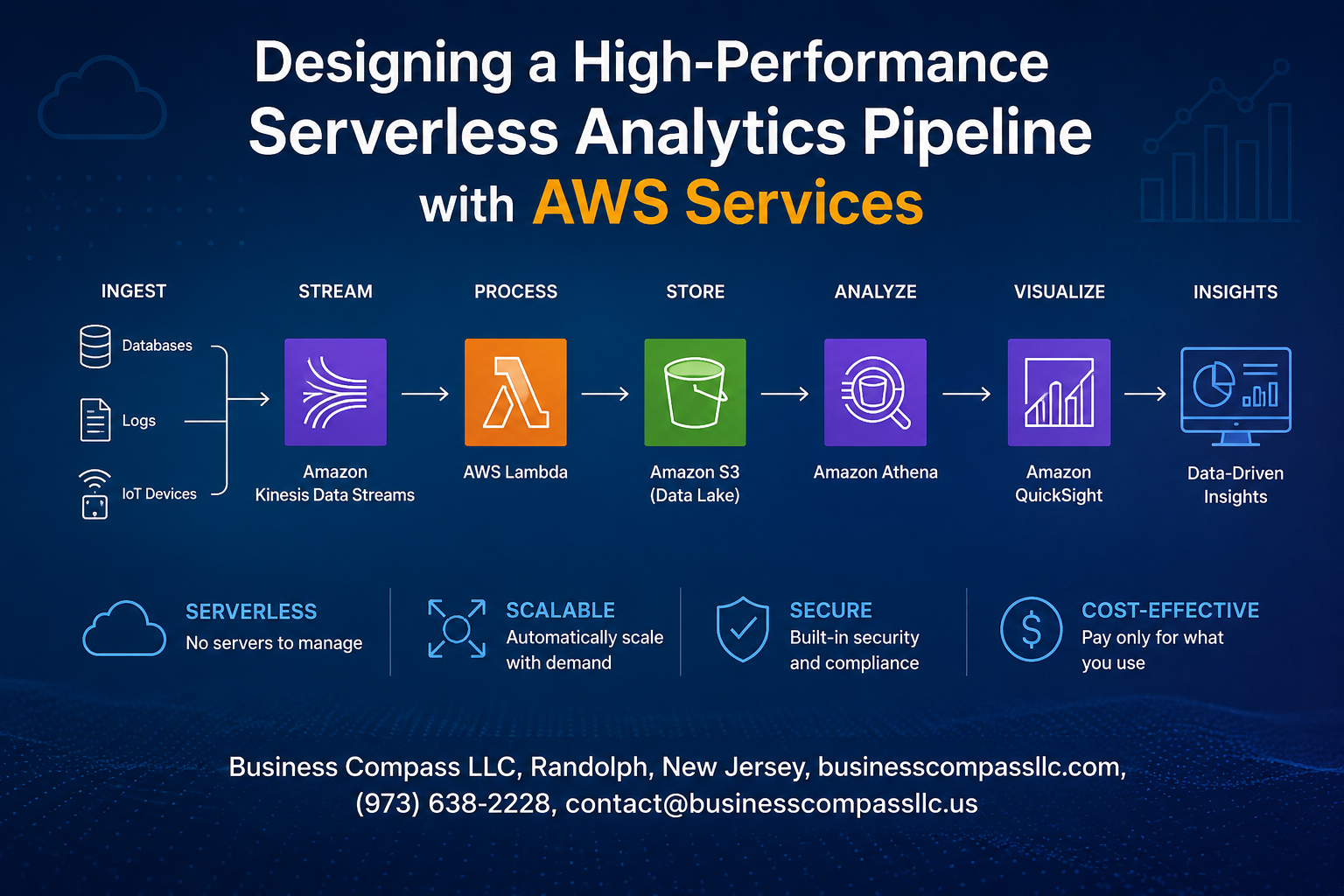
Building a serverless analytics pipeline on AWS can transform how your organization processes and analyzes data without managing infrastructure overhead. This guide targets data engineers, cloud architects, and analytics teams who want to create scalable, cost-effective data processing solutions using AWS serverless analytics services.
AWS serverless analytics eliminates the complexity of server management while delivering powerful data processing capabilities. You’ll learn how AWS Lambda analytics and AWS Kinesis analytics pipeline work together to handle everything from batch processing to real-time data processing AWS scenarios.
We’ll walk through the core components of a serverless data architecture, including how to set up robust serverless data ingestion AWS workflows that automatically scale with your data volume. You’ll discover practical strategies for building a serverless ETL pipeline using AWS Glue serverless and other managed services that reduce operational overhead.
The guide also covers optimization techniques for your serverless data pipeline AWS setup, including storage strategies and query performance tuning. By the end, you’ll have a clear roadmap for implementing a production-ready analytics pipeline that handles your data processing needs efficiently and cost-effectively.
Understanding Serverless Analytics Architecture Fundamentals
Benefits of Serverless Computing for Data Processing Workloads
Serverless computing transforms data processing by eliminating server management overhead and enabling automatic scaling based on demand. Your serverless analytics pipeline only runs when processing data, dramatically reducing idle time costs while handling massive workloads without infrastructure planning. AWS Lambda analytics functions execute in milliseconds, processing data streams with zero cold start impact on performance. Event-driven architecture means your pipeline responds instantly to new data arrivals, making real-time data processing AWS solutions incredibly efficient. Teams can focus on business logic rather than maintaining servers, accelerating development cycles and reducing operational complexity significantly.
Key Components of a Modern Analytics Pipeline
Modern serverless data architecture consists of four essential layers working seamlessly together. Data ingestion captures streaming and batch data through services like AWS Kinesis and S3, forming the foundation of your AWS serverless analytics system. Processing engines like AWS Lambda and Glue handle transformation logic, while storage solutions including data lakes and warehouses organize processed information. Query engines enable real-time analytics and reporting, completing the serverless data pipeline AWS workflow. Each component operates independently, allowing teams to optimize individual services without affecting the entire system’s performance or reliability.
Cost Optimization Advantages Over Traditional Infrastructure
Traditional infrastructure requires paying for peak capacity even during low usage periods, wasting significant resources. Serverless ETL pipeline architectures charge only for actual compute time and data processed, reducing costs by up to 70% compared to always-on servers. No upfront hardware investments or maintenance contracts are needed, converting capital expenses into operational costs. Auto-scaling eliminates over-provisioning concerns while pay-per-request pricing models align costs directly with business value. Small startups can access enterprise-grade analytics capabilities without massive infrastructure investments, democratizing advanced data processing across organizations of all sizes.
Scalability and Performance Considerations
AWS Kinesis analytics pipeline solutions automatically scale from handling dozens to millions of events per second without manual intervention. Serverless functions execute concurrently across multiple availability zones, ensuring high availability and fault tolerance. Memory and timeout configurations can be adjusted per function, optimizing performance for specific data processing requirements. Serverless data ingestion AWS patterns handle traffic spikes gracefully, maintaining consistent processing speeds regardless of data volume fluctuations. Cold start latencies have minimal impact on batch processing workflows, while streaming applications benefit from provisioned concurrency options for predictable performance requirements.
Essential AWS Services for Serverless Analytics

AWS Lambda for event-driven data processing
AWS Lambda serves as the backbone of serverless analytics pipelines, processing data automatically when events trigger functions. This pay-per-execution model eliminates server management while scaling instantly from zero to thousands of concurrent executions. Lambda integrates seamlessly with other AWS services, making it perfect for real-time data transformations, log processing, and triggering downstream analytics workflows without infrastructure overhead.
Amazon Kinesis for real-time data streaming
Amazon Kinesis handles massive streams of real-time data with millisecond latency, making it essential for serverless analytics pipelines. Kinesis Data Streams captures and processes thousands of records per second, while Kinesis Analytics runs SQL queries on streaming data. The service automatically scales based on throughput needs and integrates with Lambda for immediate data processing, enabling businesses to react to data insights as events happen.
AWS Glue for ETL operations and data cataloging
AWS Glue transforms raw data into analytics-ready formats through fully managed ETL operations. Its serverless nature means no infrastructure provisioning while automatically discovering data schemas and creating a centralized catalog. Glue jobs scale dynamically based on data volume, and the built-in scheduler handles complex workflows. The Data Catalog becomes your single source of truth, making datasets discoverable across your entire serverless analytics pipeline.
Amazon S3 for scalable data storage
Amazon S3 forms the foundation of serverless data architecture by providing virtually unlimited storage that scales automatically. Its integration with analytics services like Athena enables direct querying without moving data, while lifecycle policies optimize costs by transitioning data between storage classes. S3’s event notifications trigger Lambda functions for immediate processing, and partitioning strategies dramatically improve query performance for large datasets in your analytics pipeline.
Data Ingestion and Real-Time Processing Strategies

Setting up multiple data source connections
Your serverless analytics pipeline needs robust connections to various data sources like databases, APIs, file systems, and third-party services. AWS provides multiple ingestion methods including API Gateway for REST endpoints, AWS DMS for database replication, and S3 Transfer Family for secure file transfers. Lambda functions can trigger automatically when new data arrives, while EventBridge handles event-driven architectures. Configure IAM roles carefully to ensure secure access across different source systems. Use AWS Secrets Manager to store connection credentials and rotate them automatically.
Implementing stream processing with Kinesis Data Streams
Kinesis Data Streams forms the backbone of real-time data processing in your serverless analytics pipeline. Configure multiple shards based on expected throughput – each shard handles 1,000 records per second or 1MB per second. Connect Lambda functions directly to streams for immediate processing, enabling sub-second latency for critical analytics. Use Kinesis Data Firehose to automatically deliver streaming data to S3, Redshift, or OpenSearch without writing custom code. Implement proper error handling with dead letter queues and set up CloudWatch metrics to monitor stream health and performance.
Batch processing optimization techniques
Optimize batch processing by scheduling Lambda functions with EventBridge rules or using Step Functions for complex workflows. Process large datasets efficiently by breaking them into smaller chunks and using parallel execution. S3 event notifications can trigger processing automatically when new files arrive. Configure appropriate memory and timeout settings for Lambda functions handling large batches. Use AWS Glue for heavy ETL workloads that exceed Lambda’s 15-minute limit. Implement checkpointing mechanisms to handle failures gracefully and avoid reprocessing entire datasets when errors occur.
Building Efficient ETL Workflows

Designing transformation logic with AWS Glue jobs
AWS Glue jobs serve as the backbone of your serverless ETL pipeline, transforming raw data into structured formats for analytics. These fully managed Spark environments automatically scale based on workload demands, eliminating infrastructure management overhead. Create custom transformation scripts using Python or Scala, leveraging built-in connectors for popular data sources. Glue’s visual ETL editor simplifies complex transformations through drag-and-drop interfaces, while advanced users can craft custom logic for specific business requirements.
Implementing data quality checks and validation
Data quality validation ensures your serverless analytics pipeline produces reliable insights. Implement automated checks using AWS Glue DataBrew for profiling and AWS Lambda functions for custom validation rules. Set up row-level and column-level validations to catch anomalies, missing values, and schema violations early in the pipeline. Create quality scorecards that track data freshness, completeness, and accuracy metrics. Configure automated alerts through CloudWatch when quality thresholds fall below acceptable levels, preventing downstream analytical errors.
Managing schema evolution and data lineage
Schema evolution poses significant challenges in dynamic data environments. AWS Glue Schema Registry automatically detects and manages schema changes across your serverless data pipeline, ensuring backward compatibility. Track data lineage using AWS Glue’s built-in cataloging features, documenting how data flows through transformation stages. Implement versioning strategies for schema changes, allowing gradual migration without breaking existing analytics workflows. Use Lake Formation for fine-grained access control and governance across evolving data structures.
Automating workflow orchestration with Step Functions
AWS Step Functions orchestrate complex ETL workflows across multiple AWS services, creating resilient serverless analytics pipelines. Design state machines that coordinate Glue jobs, Lambda functions, and data validation steps with built-in error handling and retry logic. Implement parallel processing for independent transformation tasks, reducing overall pipeline execution time. Configure event-driven triggers through EventBridge to automatically initiate workflows when new data arrives. Monitor workflow execution through Step Functions’ visual interface, quickly identifying bottlenecks and failures in your serverless ETL pipeline.
Data Storage and Query Optimization

Partitioning strategies for Amazon S3 data lakes
Smart partitioning transforms your serverless analytics pipeline performance by organizing data into logical folders based on frequently queried dimensions. Implement date-based partitioning (year/month/day) for time-series data, geographic partitioning for location-based analytics, or custom business logic partitioning. This approach reduces query scan times dramatically, as Amazon Athena only reads relevant partitions instead of the entire dataset. Consider partition size between 128MB-1GB for optimal performance. Avoid creating too many small partitions, which can slow down query planning. Use AWS Glue crawlers to automatically detect and register new partitions in your data catalog.
Implementing columnar storage with Parquet format
Parquet format delivers exceptional compression ratios and query performance for your serverless data architecture. This columnar storage format stores data by column rather than row, enabling efficient compression and allowing analytical queries to read only required columns. Convert your JSON or CSV data to Parquet using AWS Glue ETL jobs or Amazon Kinesis Data Firehose. The format integrates seamlessly with Amazon Athena, reducing query costs by up to 90% compared to text formats. Implement schema evolution capabilities to handle changing data structures without breaking existing queries. Store frequently accessed columns together and apply appropriate encoding schemes.
Setting up Amazon Athena for serverless querying
Amazon Athena provides serverless SQL queries directly against your S3 data lake without managing infrastructure. Configure your data catalog using AWS Glue to define table schemas and partition information. Set up result locations in S3 for query outputs and enable query result encryption for sensitive data. Create workgroups to manage user access, query limits, and cost controls across different teams. Use MSCK REPAIR TABLE commands to update partition information after new data arrives. Optimize query performance by creating views for commonly used joins and aggregations. Enable CloudTrail logging to monitor query patterns and identify optimization opportunities.
Performance tuning for large-scale analytics
Query optimization starts with proper data organization and continues with smart SQL practices. Use columnar projection to select only required fields, implement appropriate WHERE clause filters, and leverage partition pruning. Create materialized views for frequently accessed aggregations and consider bucketing for large tables with common join keys. Monitor query execution plans through Athena’s query history and identify bottlenecks. Implement result caching for repetitive queries and use approximate functions (APPROX_COUNT_DISTINCT) when exact precision isn’t required. Scale concurrent queries by adjusting workgroup settings and consider Amazon Redshift Spectrum for complex analytical workloads requiring faster response times.
Monitoring and Troubleshooting Your Pipeline

Setting up CloudWatch metrics and alarms
CloudWatch serves as your primary monitoring hub for AWS serverless analytics pipelines, providing essential visibility into Lambda function performance, Kinesis stream throughput, and Glue job execution times. Create custom metrics to track business-specific KPIs like data processing latency and record failure rates. Set up alarms for critical thresholds such as Lambda error rates exceeding 1% or DLQ message accumulation. Configure composite alarms to trigger automated responses when multiple services show degraded performance simultaneously.
Implementing distributed tracing with X-Ray
X-Ray delivers end-to-end visibility across your serverless data architecture by tracing requests through multiple AWS services. Enable X-Ray tracing on Lambda functions to visualize data flow from ingestion through processing and storage. Use service maps to identify bottlenecks in your ETL pipeline and analyze cold start impacts on performance. Implement custom subsegments to track specific operations within your functions, making it easier to pinpoint performance issues in complex data transformations.
Error handling and retry mechanisms
Robust error handling prevents data loss and maintains pipeline reliability in serverless analytics workflows. Implement exponential backoff with jitter for Lambda retry logic when processing fails temporarily. Configure Dead Letter Queues (DLQs) for both SQS and Lambda to capture failed records for later reprocessing. Use Step Functions for orchestrating complex ETL workflows with built-in retry policies and error handling states. Design idempotent functions to safely retry operations without duplicating data or corrupting downstream processes.
Cost monitoring and optimization strategies
Proactive cost monitoring keeps your AWS serverless analytics pipeline budget-friendly while maintaining performance. Use Cost Explorer to track spending patterns across Lambda executions, Kinesis shard hours, and Glue DPU consumption. Set up billing alerts when costs exceed expected thresholds for individual services. Optimize Lambda memory allocation based on CloudWatch metrics to balance performance and cost. Right-size Kinesis streams by monitoring shard utilization and implementing auto-scaling policies to handle variable workloads efficiently.

Building a serverless analytics pipeline on AWS gives you the power to handle massive amounts of data without worrying about managing servers or infrastructure. The combination of services like Lambda, Kinesis, Glue, and S3 creates a robust foundation that scales automatically with your data demands. When you design your pipeline with proper data ingestion strategies, efficient ETL workflows, and optimized storage solutions, you’re setting yourself up for both current success and future growth.
The real magic happens when you put monitoring and troubleshooting practices in place from day one. Your pipeline will only be as strong as your ability to catch issues early and optimize performance over time. Start with a simple design, test each component thoroughly, and gradually add complexity as your analytics needs grow. The serverless approach means you can focus on extracting valuable insights from your data rather than spending time on infrastructure maintenance.








