







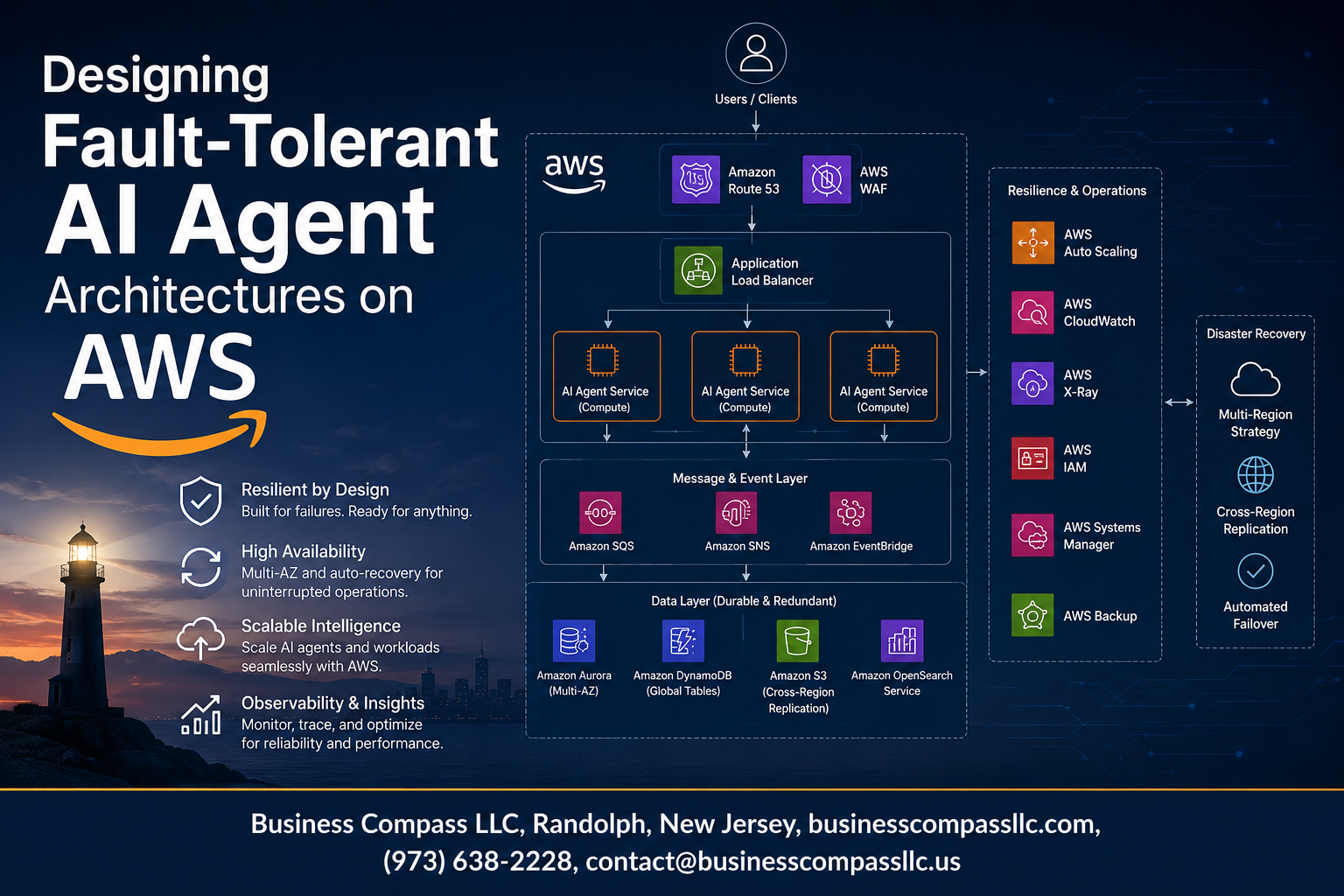
Building fault-tolerant AI architectures on AWS keeps your AI agents running when things go wrong. AI systems need to handle failures gracefully – whether it’s a server crash, network hiccup, or unexpected data spike that could break your agent’s decision-making process.
This guide targets DevOps engineers, AI/ML engineers, and cloud architects who want to design resilient AI systems AWS can support at scale. You’ll learn how to build AI agents that stay operational even when components fail.
We’ll walk through the core AWS services that make your AI systems bulletproof, including how Auto Scaling Groups and Elastic Load Balancers keep your agents responsive. You’ll also discover practical strategies for implementing redundancy and smart load distribution that prevents single points of failure from taking down your entire AI workflow.
Finally, we’ll cover monitoring systems that catch problems before they impact users, plus data consistency techniques that keep your AI agent design stable across distributed components.
Understanding Fault Tolerance Requirements for AI Agent Systems

Identifying Critical Failure Points in AI Workflows
AI agents face unique vulnerabilities that differ from traditional applications. Model inference endpoints can become overwhelmed during traffic spikes, causing cascading failures across dependent services. Training pipelines risk corruption when data sources become unavailable or when compute instances fail mid-process. State management systems storing conversation history or learned behaviors create single points of failure if not properly distributed. Vector databases holding embeddings can experience performance degradation, directly impacting agent response quality. Communication bottlenecks between microservices handling different AI functions often trigger timeout errors and service degradation.
Establishing Recovery Time and Data Loss Objectives
Fault-tolerant AI architectures require clearly defined recovery metrics that align with business requirements. Real-time conversational agents typically need sub-second recovery times to maintain user engagement, while batch processing systems can tolerate longer outages. Data loss objectives vary significantly – training datasets require comprehensive backup strategies since recreation costs are high, whereas temporary conversation states might accept limited loss. Establishing these parameters early guides architectural decisions around replication strategies, backup frequencies, and failover mechanisms. AWS services like RDS Multi-AZ deployments help meet stringent recovery objectives for critical AI system databases.
Mapping AI Agent Dependencies and Communication Patterns
Modern AI systems rely on complex interconnected services that create intricate dependency chains. Document processing agents depend on storage services, preprocessing pipelines, model endpoints, and result caching layers. Mapping these relationships reveals potential failure propagation paths and helps prioritize resilience investments. Synchronous communication patterns between services create tight coupling that amplifies failures, while asynchronous messaging through services like Amazon SQS provides natural circuit breakers. Understanding data flow patterns helps identify where redundancy is most critical and where eventual consistency models are acceptable for maintaining system availability during partial failures.
Core AWS Services for Building Resilient AI Architectures

Leveraging Amazon SageMaker for Distributed Model Training
Amazon SageMaker forms the backbone of fault-tolerant AI architectures by automatically distributing training workloads across multiple instances and availability zones. The service handles instance failures gracefully through checkpoint recovery and automatic retry mechanisms. Built-in data parallelism ensures your AI models continue training even when individual compute nodes fail, while spot instance integration reduces costs without compromising resilience. SageMaker’s managed infrastructure eliminates single points of failure by replicating training jobs across geographically distributed AWS regions, making your AI development pipeline virtually immune to localized outages.
Implementing Auto Scaling Groups for Dynamic Resource Management
Auto Scaling Groups provide the foundation for resilient AI systems AWS deployments by automatically adjusting compute capacity based on real-time demand and health checks. These groups monitor your AI agent workloads and replace unhealthy instances within minutes, ensuring continuous service availability. Target tracking policies scale resources up during peak inference loads and down during quiet periods, optimizing both performance and costs. Integration with Application Load Balancers distributes traffic across healthy instances while removing failed nodes from rotation, creating self-healing infrastructure that adapts to changing workload patterns without manual intervention.
Utilizing Amazon ECS and EKS for Container Orchestration
Container orchestration through Amazon ECS and EKS delivers robust fault tolerance for AI agent deployments by managing service discovery, load balancing, and automated failover. ECS Fargate eliminates server management overhead while providing built-in redundancy across multiple availability zones. Kubernetes on EKS offers advanced scheduling capabilities that redistribute AI workloads when nodes fail, using health checks and liveness probes to detect and replace unresponsive containers. Both services integrate seamlessly with AWS networking and security features, creating isolated environments where AI agents can fail and recover independently without affecting other system components.
Deploying Multi-AZ RDS for Database Redundancy
Multi-AZ RDS deployments protect your AI agent’s critical data by maintaining synchronous replicas across separate availability zones, providing automatic failover within 60 seconds of primary database failure. This configuration ensures your AI systems maintain access to training data, model parameters, and session state even during infrastructure outages. Read replicas can be distributed globally to serve inference requests with low latency while reducing load on the primary database. Automated backups and point-in-time recovery features protect against data corruption, while encryption at rest and in transit secures sensitive AI model artifacts and user data across all database instances.
Implementing Redundancy and Load Distribution Strategies

Creating Multi-Region AI Agent Deployments
Distributing fault-tolerant AI architectures across multiple AWS regions provides robust protection against regional outages and natural disasters. Deploy identical AI agent instances in at least two geographically separated regions using AWS Auto Scaling Groups and Application Load Balancers. Configure cross-region VPC peering to enable seamless communication between deployments while maintaining data sovereignty requirements. Use Route 53 health checks with weighted routing policies to automatically redirect traffic when primary regions experience failures.
Designing Circuit Breaker Patterns for Service Protection
Circuit breaker patterns prevent cascading failures by monitoring service health and temporarily blocking requests to failing components. Implement these patterns using AWS Lambda functions with exponential backoff algorithms, setting thresholds for error rates and response times. Configure three states: closed (normal operation), open (blocking requests), and half-open (testing recovery). AWS API Gateway provides built-in throttling capabilities that complement custom circuit breaker logic, protecting downstream AI services from overload scenarios.
Establishing Health Checks and Automated Failover Mechanisms
Comprehensive health monitoring requires multi-layered checks spanning infrastructure, application, and AI model performance metrics. Deploy CloudWatch custom metrics to track model inference accuracy, response latency, and processing queue depths. Configure Application Load Balancer health checks with custom endpoints that validate both service availability and AI model responsiveness. Set up automated failover triggers using CloudWatch alarms connected to Lambda functions that can restart containers, scale resources, or reroute traffic to backup instances within predefined recovery time objectives.
Optimizing Load Balancing Across AI Processing Nodes
Effective load distribution for resilient AI systems AWS requires sophisticated algorithms that account for varying computational demands across different AI workloads. Implement weighted round-robin algorithms through Application Load Balancers, adjusting weights based on node capacity and current GPU utilization. Use target group health checks with custom metrics that consider model warm-up times and memory consumption. Configure session affinity for stateful AI agents while enabling seamless failover through shared state storage in Amazon ElastiCache or DynamoDB for maintaining conversation context and processing history.
Data Consistency and State Management Techniques

Implementing Event Sourcing for AI Agent State Tracking
Event sourcing provides an immutable log of all state changes in your AI agent system, making it easier to track decision-making processes and recover from failures. Instead of storing current state, you capture every event that led to state changes, allowing you to rebuild agent state by replaying events. AWS EventBridge works perfectly for this pattern, capturing agent decisions, user interactions, and system events in sequence. When combined with Amazon S3 for long-term event storage, you create a complete audit trail that supports debugging and compliance requirements.
Utilizing Amazon DynamoDB for Distributed Session Management
DynamoDB’s global tables feature enables seamless session replication across multiple AWS regions, ensuring your AI agents maintain consistent state even during regional outages. Configure session data with appropriate TTL settings to automatically clean up expired sessions while maintaining active ones across availability zones. The service’s single-digit millisecond latency keeps agent responses fast, while its automatic scaling handles traffic spikes without manual intervention. DynamoDB Streams can trigger Lambda functions to sync session updates in real-time, creating a robust foundation for fault-tolerant AI architectures.
Establishing Data Synchronization Across Availability Zones
Cross-AZ data synchronization requires careful orchestration between DynamoDB global secondary indexes, ElastiCache clusters, and S3 cross-region replication. Set up multi-AZ DynamoDB tables with consistent read preferences to ensure your AI agents access the same data regardless of which zone they’re running in. ElastiCache Redis clusters with cluster mode enabled provide fast access to frequently used model parameters and cached predictions. Amazon Aurora Global Database offers read replicas across zones for training data access, while maintaining ACID compliance for critical agent state updates that must remain consistent across all locations.
Monitoring and Alerting Systems for Proactive Fault Detection

Setting Up CloudWatch Metrics for AI Performance Tracking
CloudWatch serves as the backbone for monitoring fault-tolerant AI architectures on AWS. Custom metrics track inference latency, model accuracy drift, and resource consumption patterns. Configure metrics for each AI agent component including API gateways, Lambda functions, and SageMaker endpoints. Set up dimensional metrics that capture both system-level performance and business-specific KPIs like prediction confidence scores and error rates across different model versions.
Creating Custom Dashboards for Real-Time System Visibility
Custom CloudWatch dashboards provide centralized visibility into your resilient AI systems AWS infrastructure. Build role-based dashboards for different stakeholders – technical teams need detailed performance graphs while business users require high-level health indicators. Include widgets showing real-time throughput, error rates, and dependency health checks. Organize dashboards by service boundaries, creating separate views for data ingestion, model inference, and downstream systems to enable quick problem isolation.
Implementing Automated Alert Triggers for Anomaly Detection
Automated alerting prevents small issues from becoming system failures in AWS AI agent design. Configure CloudWatch Alarms with dynamic thresholds that adapt to normal traffic patterns rather than static values. Implement composite alarms that correlate multiple signals – high latency combined with increased error rates often indicates impending failures. Use Amazon SNS to route alerts through appropriate escalation paths, ensuring critical issues reach the right team members immediately while filtering noise from non-critical events.
Establishing Log Aggregation with AWS CloudTrail
CloudTrail provides comprehensive audit logging for your AI agent infrastructure, capturing API calls, configuration changes, and access patterns. Centralize logs from multiple services using CloudWatch Logs Groups with structured JSON formatting for easier parsing. Implement log retention policies that balance compliance requirements with storage costs. Create custom log metrics that extract meaningful patterns from unstructured log data, enabling proactive detection of security anomalies and performance degradation before they impact user experience.
Disaster Recovery and Business Continuity Planning

Designing Automated Backup Strategies for AI Models and Data
Implementing comprehensive backup strategies for fault-tolerant AI architectures requires automated systems that capture both model states and training data at regular intervals. AWS S3 Cross-Region Replication automatically synchronizes critical AI models and datasets across multiple regions, while Amazon EBS snapshots preserve instance-level data for quick recovery. Lambda functions can orchestrate scheduled backups of model checkpoints, configuration files, and inference logs. DynamoDB Point-in-Time Recovery ensures agent state data remains recoverable up to 35 days, while AWS DataSync maintains synchronized copies of large training datasets across availability zones.
Creating Recovery Procedures for Different Failure Scenarios
Recovery procedures must address various failure modes specific to resilient AI systems AWS environments. Single instance failures trigger Auto Scaling Groups to launch replacement agents within minutes, while Lambda functions automatically redirect traffic through Application Load Balancers. Multi-zone outages activate cross-region failover protocols using Route 53 health checks and weighted routing policies. Database failures invoke automated RDS failover to standby instances in alternate zones. Model corruption scenarios require rollback procedures to previous stable checkpoints stored in S3 versioned buckets. Each recovery pathway includes predefined runbooks with specific AWS CLI commands and CloudFormation templates for rapid deployment.
Testing Disaster Recovery Plans with Chaos Engineering
Chaos engineering validates disaster recovery capabilities by intentionally introducing failures into production-like environments. AWS Fault Injection Simulator creates controlled experiments that simulate EC2 instance terminations, network partitions, and CPU throttling scenarios. Regular chaos testing reveals weaknesses in failover mechanisms before real disasters strike. GameDays exercises involve deliberately triggering regional outages while monitoring recovery time objectives and agent performance metrics. Automated testing pipelines use AWS Systems Manager to execute predefined failure scenarios weekly, measuring recovery speeds and data consistency. Results feed back into architecture improvements, ensuring fault-tolerant AI architectures evolve with changing requirements.
Establishing Cross-Region Replication for Critical Components
Cross-region replication protects against regional disasters while maintaining low-latency access to AI services. Amazon S3 Cross-Region Replication automatically copies model artifacts and training data to geographically separated regions. RDS Global Database provides read replicas across regions for real-time agent state synchronization. ElastiCache Global Datastore replicates session caching layers with sub-second replication lag. AWS AI agent design patterns incorporate regional load balancers that automatically route requests to healthy regions based on latency and availability metrics. DynamoDB Global Tables enable multi-region writes for agent configuration data, ensuring consistency across all deployment zones.

Building fault-tolerant AI agent systems on AWS requires careful planning across multiple layers of your architecture. From understanding your specific resilience requirements to implementing smart redundancy strategies, each component plays a crucial role in keeping your AI agents running smoothly. AWS provides the tools you need – whether it’s load balancers for traffic distribution, monitoring services for early problem detection, or backup systems for disaster recovery. The key is combining these services thoughtfully while maintaining data consistency and proper state management across your distributed systems.
The investment in fault tolerance pays off when your AI agents can handle unexpected failures without missing a beat. Start by mapping out your critical failure points, then build your monitoring and alerting systems to catch issues early. Don’t forget to regularly test your disaster recovery procedures – the best backup plan is worthless if it doesn’t work when you need it most. Your users depend on reliable AI services, and with the right AWS architecture, you can deliver that reliability while scaling confidently for the future.









