







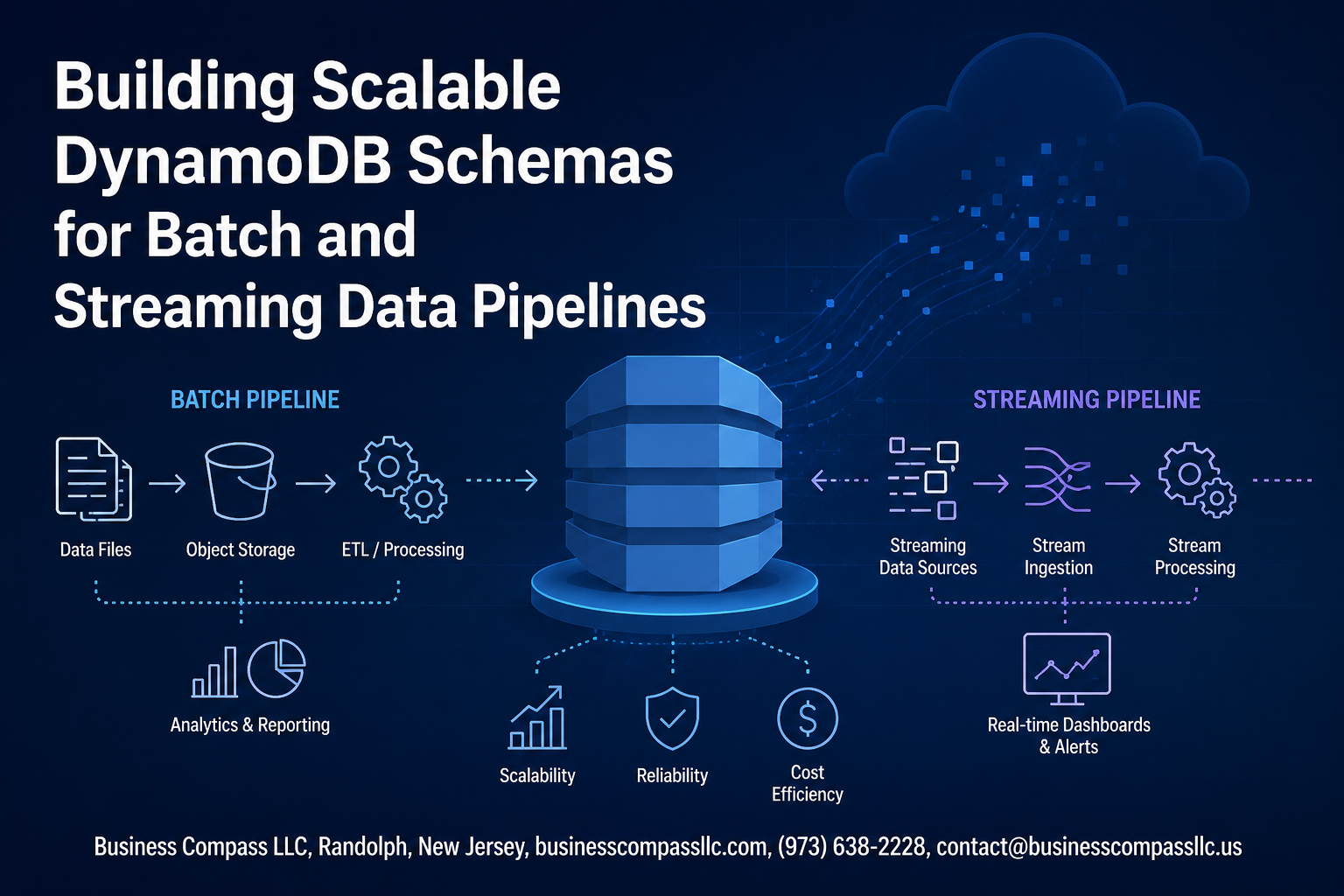
DynamoDB powers some of the world’s largest data pipelines, but designing schemas that handle both batch and streaming workloads can make or break your application’s performance. Getting your DynamoDB schema design right from the start saves you from expensive migrations and performance bottlenecks down the road.
This guide is for data engineers, backend developers, and architects who need to build scalable DynamoDB architecture that handles massive data volumes without breaking a sweat. If you’re dealing with high-throughput applications, real-time analytics, or complex ETL processes, you’ll find practical strategies to optimize your NoSQL database design.
We’ll dive deep into DynamoDB schema design fundamentals and show you how different access patterns shape your table structure. You’ll learn proven scalability patterns for handling millions of records in batch jobs while maintaining fast query performance. We’ll also explore real-time data ingestion DynamoDB techniques that keep your streaming pipelines running smoothly, plus performance optimization strategies that squeeze every bit of speed from your database.
Understanding DynamoDB Schema Design Fundamentals for Data Pipelines

Key differences between relational and NoSQL schema approaches
DynamoDB schema design flips traditional database thinking upside down. Instead of normalizing data across multiple tables, you denormalize everything into a single table structure. Relational databases enforce rigid schemas with foreign keys and joins, while DynamoDB embraces flexible item structures where each record can have different attributes. This fundamental shift means you design around your access patterns first, not your data relationships.
Single-table design principles for maximum performance
Single-table design maximizes DynamoDB performance by eliminating expensive cross-table queries and leveraging efficient item-level operations. Store related entities together using composite keys that enable retrieval in single requests. Use generic attribute names like PK (partition key) and SK (sort key) to accommodate multiple entity types within the same table structure. This approach reduces latency, simplifies queries, and scales seamlessly across distributed workloads without complex join operations.
Access pattern identification and query optimization strategies
Map out every query your application needs before designing your DynamoDB schema. Document read and write patterns, frequency requirements, and data relationships to inform key design decisions. Group related access patterns that can share the same partition key, enabling efficient batch operations. Create Global Secondary Indexes (GSI) for alternative query patterns, but limit them to essential use cases to control costs and maintain write performance across your data pipeline architecture.
Partition key and sort key selection for distributed workloads
Choose partition keys that distribute data evenly across DynamoDB partitions to avoid hot partitioning issues in high-volume scenarios. Combine timestamp prefixes with entity identifiers for time-series data, or use calculated hash values for uniform distribution. Design sort keys to enable range queries and support multiple access patterns through strategic prefixing. For streaming data ingestion, consider using random suffixes or rotating partition strategies to handle burst traffic while maintaining query efficiency.
Designing Schemas for High-Volume Batch Processing

Optimizing Write Capacity and Throughput for Bulk Operations
When handling massive data volumes, your DynamoDB schema design directly impacts batch processing performance. Use composite partition keys that distribute writes across multiple partitions – combining timestamp prefixes with random suffixes works exceptionally well. Configure on-demand billing for unpredictable workloads, but provisioned capacity gives better cost control for consistent batch jobs. Batch write operations using BatchWriteItem API can process up to 25 items per request, reducing API calls significantly. Pre-calculate your required write capacity units based on item size and target throughput. For time-series data, implement write sharding by appending random numbers to partition keys, spreading load across multiple logical partitions.
Implementing Effective Data Partitioning Strategies
Smart partitioning prevents bottlenecks in your DynamoDB batch processing pipeline. Create partition keys using high-cardinality attributes like user IDs combined with timestamps or random suffixes. Avoid sequential patterns in partition keys – they create hot spots that throttle your entire workflow. Use hierarchical partitioning for nested data structures, where parent-child relationships need efficient querying. Consider using GSIs (Global Secondary Indexes) with different partition keys to support various access patterns without duplicating data. Time-based partitioning works well for log data and analytics workloads, but add randomization to prevent all writes hitting the same partition during peak hours.
Managing Hot Partitions and Write Throttling Issues
Hot partitions kill batch processing performance faster than anything else in DynamoDB. Monitor CloudWatch metrics for SuccessfulRequestLatency and ThrottledRequests to identify problematic partitions early. Implement exponential backoff with jitter in your batch processing code to handle temporary throttling gracefully. Use write sharding techniques like adding random suffixes to partition keys or distributing writes across multiple tables. Consider adaptive capacity settings, which automatically redistributure throughput to handle short-term spikes. For persistent hot partitions, redesign your schema using compound keys or create additional GSIs with better distribution patterns. Deploy your batch jobs during off-peak hours and use DynamoDB’s burst capacity wisely for handling occasional traffic spikes.
Building Schemas for Real-Time Streaming Data Ingestion

Designing for consistent low-latency writes
Real-time streaming data ingestion demands DynamoDB schema patterns that minimize write latency and avoid throttling. Design your partition key to distribute writes evenly across multiple partitions – consider using composite keys combining timestamp segments with entity identifiers. Enable DynamoDB auto-scaling and provision sufficient write capacity units during peak streaming periods. Use batch write operations when possible, but implement exponential backoff for retry logic to handle temporary throttling gracefully.
Handling time-series data with efficient sort key patterns
Time-series data in streaming pipelines requires careful sort key design to support both writes and queries efficiently. Use inverted timestamp patterns (MAX_TIMESTAMP – current_timestamp) for accessing recent data first, or implement hierarchical time-based keys like “YYYY-MM-DD#HH-MM-SS#sequence_id” for granular time-based queries. Consider creating separate tables for different time granularities (hourly, daily aggregates) and implement data aging strategies using TTL attributes to automatically expire old records.
Managing concurrent writes from multiple streaming sources
Multiple streaming sources writing concurrently to DynamoDB require robust conflict resolution and coordination strategies. Implement conditional writes using condition expressions to prevent race conditions when updating existing items. Use atomic counters for aggregation scenarios and leverage DynamoDB Streams for downstream processing coordination. Design your schema to support upsert operations naturally – structure items so that overwrites don’t lose critical data. Consider implementing application-level coordination using DynamoDB’s transactional capabilities for complex multi-item operations.
Implementing data deduplication and idempotency controls
Streaming data pipelines must handle duplicate messages and ensure idempotent operations to maintain data integrity. Design your partition and sort keys to naturally support upsert operations – use unique identifiers like message IDs or event timestamps as part of your key structure. Implement client-side request tokens for conditional writes, and store processing state within items using version numbers or checksums. Create separate deduplication tables with short TTL periods to track recently processed events, enabling efficient duplicate detection without impacting your main data schema performance.
Scalability Patterns and Anti-Patterns

Avoiding common schema design mistakes that limit growth
Creating DynamoDB schema design patterns that grow with your data starts with avoiding the hotkey trap. Many developers spread their partition key values unevenly, causing some partitions to handle most traffic while others sit idle. This creates bottlenecks that throttle performance as data volumes increase. Smart schema design distributes data uniformly across partitions using composite keys that combine high-cardinality attributes. Skip time-based partition keys unless you’re archiving old data regularly. Design your access patterns first, then build your schema around them rather than forcing SQL-style normalized structures into NoSQL schema patterns.
Implementing horizontal scaling through strategic data distribution
Scalable DynamoDB architecture depends on intelligent data distribution that spreads workload evenly across multiple partitions. Use high-cardinality partition keys like user IDs, device IDs, or UUID prefixes to ensure random distribution. For time-series data in DynamoDB streaming data scenarios, prefix timestamps with randomized values or rotate through multiple table shards. Implement write sharding by appending random suffixes to partition keys when dealing with DynamoDB batch processing workloads. Pre-split your keyspace by designing partition keys that naturally distribute across the full range of possible values from day one.
Using Global Secondary Indexes effectively for query flexibility
Global Secondary Indexes transform rigid single-access patterns into flexible query systems without sacrificing DynamoDB performance tuning. Design GSIs with different partition and sort key combinations to support diverse access patterns your applications need. Project only essential attributes to minimize storage costs and improve query speed. Create sparse indexes by projecting attributes that exist in only some items, reducing unnecessary data replication. For real-time data ingestion DynamoDB use cases, design GSIs that support both point lookups and range queries on different dimensions of your data model while maintaining efficient write patterns.
Performance Optimization Techniques

Implementing read and write capacity planning strategies
Effective capacity planning for DynamoDB requires monitoring your workload patterns and implementing auto-scaling policies that respond to traffic spikes. Set up CloudWatch alarms to track consumed read and write units, with auto-scaling configured at 70% utilization to prevent throttling during unexpected loads. Consider using on-demand pricing for unpredictable workloads, while provisioned capacity works better for steady, predictable traffic patterns in your data pipeline optimization strategy.
Leveraging DynamoDB Streams for real-time processing
DynamoDB Streams capture data modification events in near real-time, making them perfect for triggering downstream processing in your scalable DynamoDB architecture. Configure streams with view types that match your processing needs – KEYS_ONLY for simple notifications, NEW_AND_OLD_IMAGES for complete change tracking. Integrate streams with Lambda functions, Kinesis Data Streams, or custom consumers to build reactive data pipelines that automatically process updates as they occur in your tables.
Optimizing item size and attribute structure for cost efficiency
Keep item sizes under 4KB whenever possible to minimize read capacity consumption and reduce costs in your DynamoDB performance tuning strategy. Flatten nested JSON structures into top-level attributes, use shorter attribute names, and store large text fields in S3 with references in DynamoDB. Implement sparse indexes by only including attributes when they contain meaningful values, and consider using binary data types for numeric values to reduce storage overhead in high-volume scenarios.
Using compression and encoding strategies for large datasets
Compress large text attributes using GZIP or LZ4 before storing them as binary data in DynamoDB, especially for JSON documents or log entries in your data pipeline. Use base64 encoding for binary data that needs to remain searchable, and implement client-side compression for items approaching the 400KB limit. Store compressed data in dedicated attributes with metadata indicating the compression method, allowing your application to decompress data seamlessly while maintaining query performance across your NoSQL schema patterns.
Monitoring and Maintenance Best Practices

Setting up CloudWatch metrics for schema performance tracking
Track DynamoDB performance with CloudWatch metrics to catch bottlenecks before they impact your data pipelines. Monitor read/write capacity utilization, throttled requests, and item sizes across tables. Set up custom dashboards showing partition key distribution and access patterns. Create alerts for unusual spikes in consumed capacity or error rates that could signal schema design issues requiring immediate attention.
Implementing automated scaling policies for varying workloads
Configure auto scaling policies to handle fluctuating data loads without manual intervention. Set target utilization between 70-80% for consistent performance while avoiding unnecessary costs. Use Application Auto Scaling to adjust read/write capacity based on CloudWatch metrics. For batch processing workloads, implement scheduled scaling to pre-provision capacity before known high-traffic periods and scale down during quiet hours.
Planning for schema evolution and migration strategies
Design schemas with future growth in mind by using flexible attribute naming and avoiding hard-coded indexes. Plan migration strategies using Global Secondary Indexes to support new access patterns without downtime. Version your schema changes and maintain backward compatibility during transitions. Use DynamoDB Streams to replicate data to new table structures while keeping existing applications running. Test migrations thoroughly in staging environments that mirror production workload patterns.

Smart DynamoDB schema design can make or break your data pipeline performance. From choosing the right partition keys for batch processing to optimizing item structures for streaming workloads, every design decision impacts how well your system handles growing data volumes. The patterns we’ve covered – like avoiding hot partitions, using composite sort keys effectively, and implementing proper indexing strategies – will help you build pipelines that scale smoothly as your business grows.
Don’t wait until performance issues force your hand. Start applying these monitoring practices now to catch problems early, and always test your schema designs with realistic data volumes before going live. Remember that good schema design isn’t just about handling today’s data – it’s about creating a foundation that can adapt as your requirements evolve. Take the time to plan your partition strategy carefully, and your future self will thank you when those data volumes inevitably multiply.








