








Building Stable Bedrock Agents: Error Handling and Retry Strategies
Building production-ready AWS Bedrock agents means dealing with failures before they happen. This guide is for developers and DevOps engineers who need their AI agents to handle errors gracefully and keep running when things go wrong.
Real-world Bedrock agents face everything from API timeouts to model throttling, and a single unhandled error can bring your entire workflow to a halt. Smart bedrock agents error handling and proven AWS bedrock retry strategies make the difference between agents that crash under pressure and those that recover automatically.
We’ll walk through agent failure detection techniques that catch problems early, then dive into retry mechanisms AWS developers actually use in production. You’ll also learn advanced error handling patterns that separate amateur implementations from robust AI agent development practices that scale.
By the end, you’ll know how to build bedrock agent resilience into every component, test your error recovery systems properly, and create agents that your users can actually depend on.
Understanding Common Bedrock Agent Failures
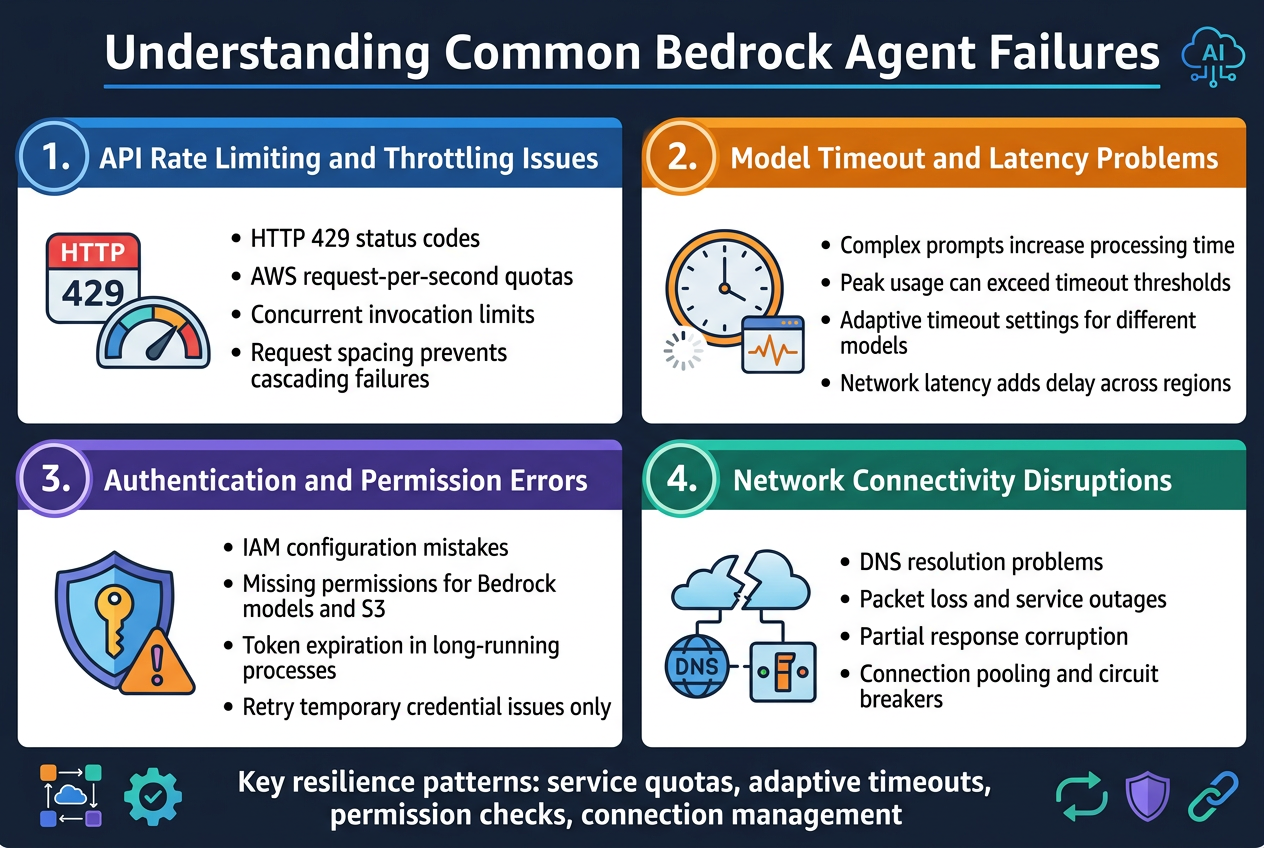
API Rate Limiting and Throttling Issues
Rate limiting represents the most frequent challenge when working with bedrock agents error handling. AWS imposes strict quotas on requests per second and concurrent invocations to prevent system overload. When these limits are exceeded, agents receive HTTP 429 status codes, causing immediate workflow interruptions. Understanding your service quotas and implementing proper request spacing prevents cascading failures across your agent infrastructure.
Model Timeout and Latency Problems
Model processing times vary significantly based on prompt complexity and current system load. Complex reasoning tasks can exceed default timeout thresholds, particularly during peak usage periods. Bedrock agent resilience requires adaptive timeout configurations that account for different model types and task complexity. Network latency compounds these issues, especially when agents operate across multiple regions or handle large data payloads.
Authentication and Permission Errors
IAM configuration mistakes create immediate agent failures that can be difficult to diagnose. Missing permissions for specific Bedrock models or associated services like S3 buckets generate cryptic error messages. Token expiration in long-running processes represents another common authentication failure point. Proper error handling patterns must distinguish between temporary credential issues and permanent permission problems to enable appropriate retry mechanisms AWS.
Network Connectivity Disruptions
Intermittent network issues cause unpredictable agent behavior, from partial response corruption to complete request failures. DNS resolution problems, packet loss, and temporary service outages create scenarios where robust AI agent development practices become critical. Connection pooling and circuit breaker patterns help maintain stability when underlying network conditions fluctuate. Implementing proper connection management prevents resource exhaustion during network instability periods.
Implementing Robust Error Detection Mechanisms

Setting Up Comprehensive Logging Systems
Effective bedrock agents error handling starts with capturing every interaction and failure point. CloudWatch logs provide the foundation, but structured logging with correlation IDs tracks requests across multiple services. Set up different log levels – DEBUG for development, ERROR for production failures, and custom levels for business logic issues. JSON formatting makes logs machine-readable for automated analysis.
Configure log retention policies based on compliance needs and cost considerations. Enable X-Ray tracing to visualize request flows and identify bottlenecks in your bedrock agent resilience pipeline.
Creating Custom Error Classification Categories
Categorize errors into transient failures (network timeouts, rate limits) and permanent failures (authentication errors, malformed requests). Create specific error codes for bedrock agent stability issues – model unavailability, token exhaustion, and content policy violations. This classification drives different retry strategies and escalation paths.
Build error hierarchies that map to business impact levels. Critical errors affecting user experience need immediate alerts, while routine API throttling can follow standard retry mechanisms AWS provides.
Building Real-Time Monitoring Dashboards
CloudWatch dashboards visualize error rates, response times, and retry attempt patterns for robust AI agent development. Set up alarms for error thresholds that trigger automated responses or team notifications. Track key metrics like success rates, average retry counts, and error distribution across different agent failure detection categories.
Integrate with tools like Grafana or custom dashboards that display real-time health scores. Include business metrics alongside technical ones – failed user requests matter more than internal service retries.
Designing Effective Retry Strategies
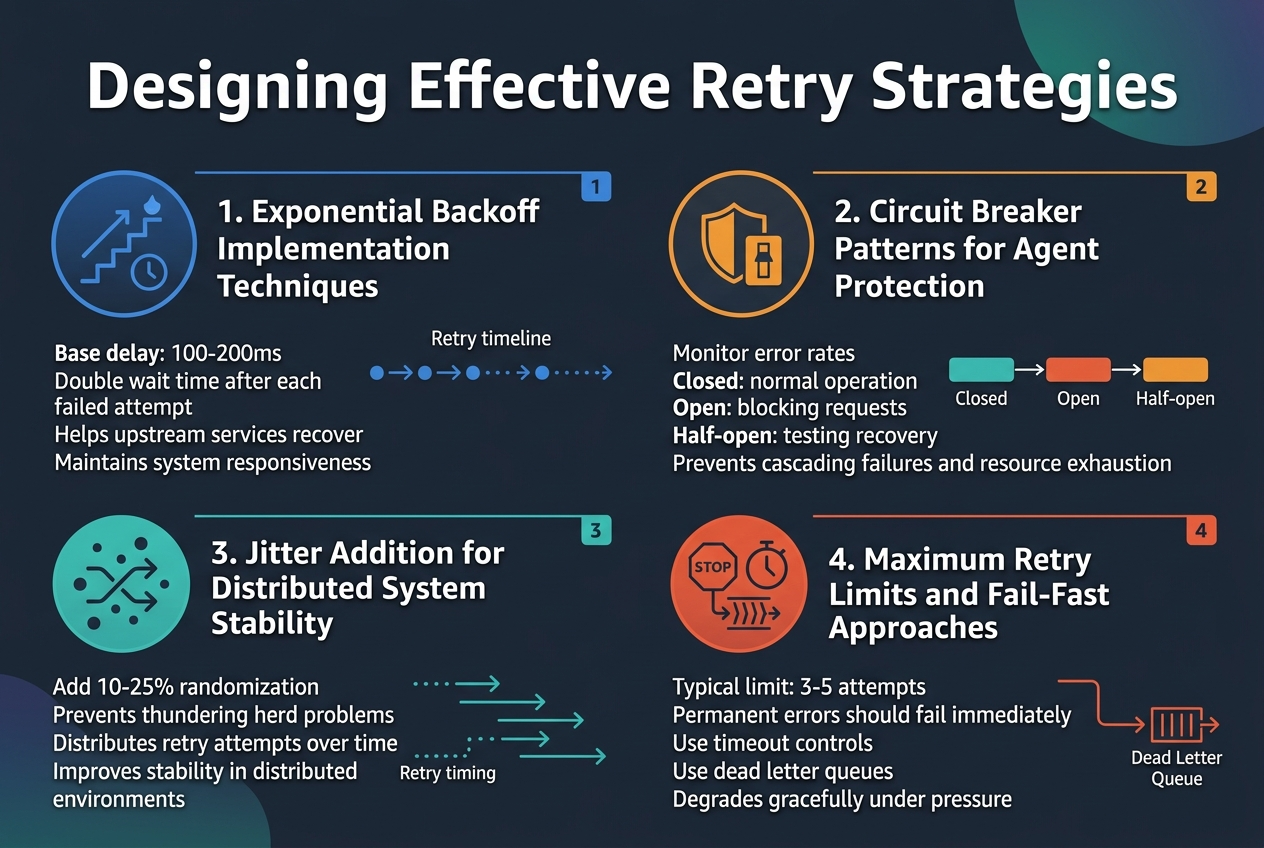
Exponential Backoff Implementation Techniques
Exponential backoff prevents overwhelming bedrock agents during temporary failures by progressively increasing wait times between retry attempts. Start with a base delay of 100-200ms, then double the interval after each failed attempt. This AWS bedrock retry strategy gives upstream services time to recover while maintaining system responsiveness.
Circuit Breaker Patterns for Agent Protection
Circuit breakers protect bedrock agents from cascading failures by monitoring error rates and automatically stopping requests when thresholds are exceeded. Implement three states: closed (normal operation), open (blocking requests), and half-open (testing recovery). This bedrock agent resilience pattern prevents resource exhaustion during prolonged outages.
Jitter Addition for Distributed System Stability
Random jitter prevents thundering herd problems when multiple agents retry simultaneously. Add 10-25% randomization to your backoff intervals to distribute retry attempts across time. This simple technique dramatically improves bedrock agent stability in distributed environments where synchronized retries can overwhelm recovering services.
Maximum Retry Limits and Fail-Fast Approaches
Set reasonable retry limits to balance persistence with responsiveness in your error handling patterns. Typically 3-5 attempts work well for transient issues, while permanent errors should fail immediately. Implement timeout controls and dead letter queues for robust AI agent development, ensuring your system degrades gracefully under pressure.
Advanced Error Handling Patterns

Graceful Degradation Strategies
Building resilient bedrock agents requires implementing graceful degradation when primary functions fail. Smart agents detect capability limitations early and automatically scale down to simpler operations rather than complete failure. This approach maintains user experience by providing partial functionality through reduced feature sets or alternative processing paths.
Fallback Response Mechanisms
Effective bedrock agent resilience depends on multi-layered fallback systems that activate when primary responses fail. These mechanisms include cached responses, simplified answer templates, and alternative model endpoints that ensure continuous service delivery. Well-designed fallback strategies preserve conversation flow while transparently handling underlying system failures.
Error Context Preservation Methods
Robust AI agent development requires capturing and maintaining error context throughout the failure recovery process. This involves logging request parameters, conversation history, and failure states to enable intelligent retry decisions. Context preservation allows agents to resume interactions seamlessly while providing developers with actionable debugging information for improving bedrock agent stability.
Testing and Validating Agent Resilience

Chaos Engineering for Bedrock Agents
Chaos engineering involves deliberately injecting failures into your bedrock agent systems to identify weaknesses before they impact production. Start by simulating network timeouts, API throttling, and resource exhaustion scenarios. Create automated scripts that randomly trigger different failure modes during normal operations.
Monitor how your agents handle unexpected token limits, model unavailability, and service degradation. Document recovery patterns and adjust your error handling patterns based on observed behavior. This proactive approach strengthens bedrock agent resilience against real-world failures.
Load Testing Under Error Conditions
Stress testing your bedrock agents under simulated error conditions reveals performance bottlenecks that standard testing misses. Configure load generators to inject various failure scenarios while maintaining realistic traffic patterns. Test concurrent user loads when retry mechanisms activate simultaneously.
Measure response times during different error rates and validate that your AWS bedrock retry strategies don’t overwhelm downstream services. Focus on breaking points where agent failure detection mechanisms trigger cascading failures across your system architecture.
Recovery Time Measurement Techniques
Accurate recovery time measurement requires tracking multiple metrics beyond simple uptime monitoring. Implement distributed tracing to measure end-to-end recovery workflows from initial failure detection through complete service restoration. Track mean time to detection (MTTD) and mean time to recovery (MTTR) separately.
Use synthetic transactions that continuously probe agent functionality during recovery phases. Establish baseline performance metrics for healthy operations, then measure deviation periods during failure scenarios. This data helps optimize your retry mechanisms AWS configurations for faster recovery.
Performance Benchmarking During Failures
Performance benchmarking during failures provides crucial insights into system degradation patterns that affect user experience. Establish performance baselines for normal operations, then measure throughput, latency, and resource utilization during various failure modes. Track how partial failures impact overall agent stability.
Create automated benchmarking suites that run during scheduled chaos experiments and real incidents. Compare performance metrics across different error handling patterns to identify optimal configurations. This ongoing bedrock agent testing validation ensures your resilience strategies maintain acceptable performance levels under stress.
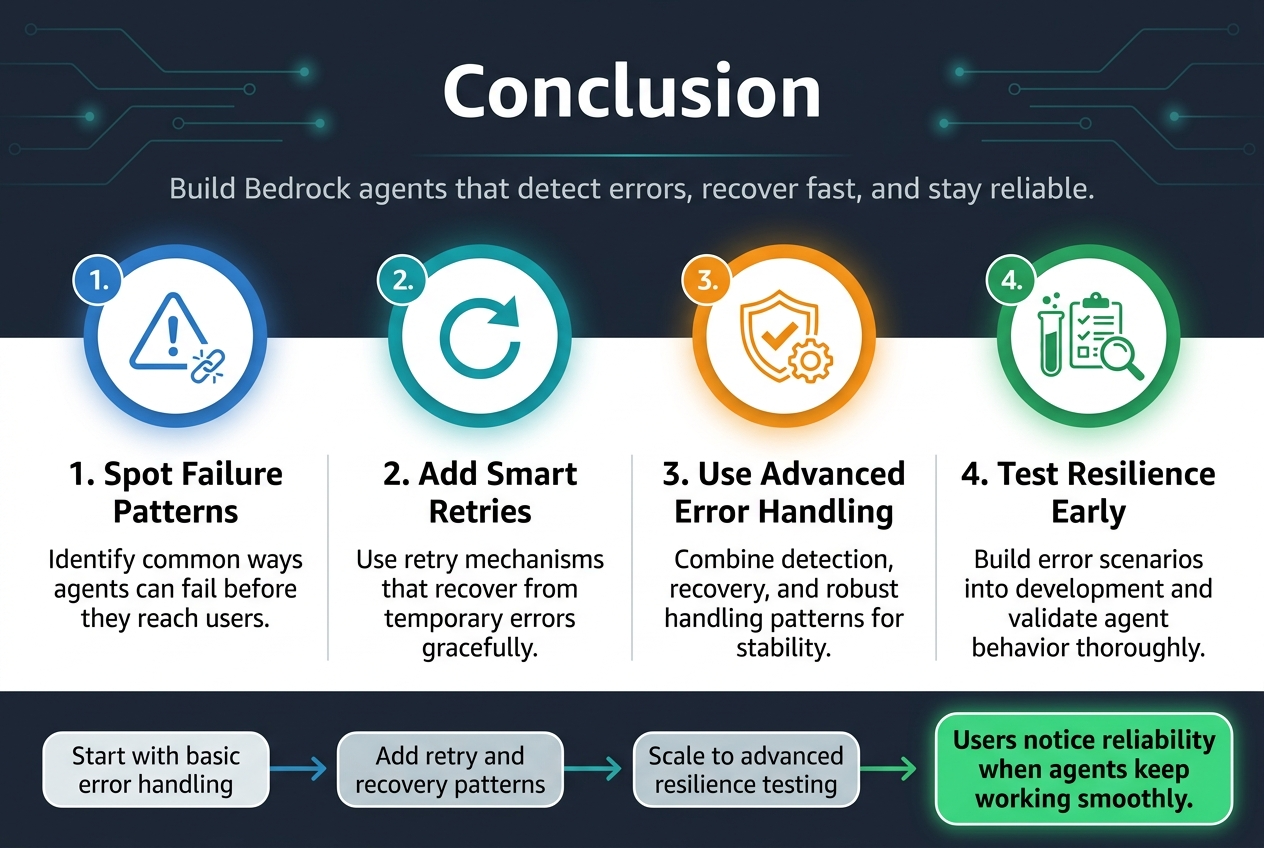
Creating reliable Bedrock agents requires a solid understanding of where things can go wrong and how to bounce back when they do. From spotting common failure patterns to building smart retry mechanisms, the foundation of any stable agent lies in its ability to handle errors gracefully. When you combine effective error detection with well-designed retry strategies and advanced handling patterns, your agents become much more dependable and user-friendly.
The real game-changer comes from thorough testing and validation of your agent’s resilience. Don’t wait for production issues to surface – build comprehensive error scenarios into your development process and make sure your agents can handle whatever gets thrown at them. Start by implementing basic error handling for your current agents, then gradually work your way up to more sophisticated patterns. Your users will thank you when your agents keep working smoothly, even when the unexpected happens.









