








Building scalable system design architecture that can handle millions of users requires more than just writing good code. You need to think like an architect, plan like a strategist, and execute like a seasoned engineer.
This guide is for software engineers, technical leads, and architects who want to master the art of creating production ready systems that don’t crumble under pressure. You’ll learn how to move beyond basic CRUD applications and build systems that scale gracefully, perform consistently, and stay reliable when things get messy.
We’ll start by exploring core system architecture patterns that form the backbone of any scalable platform. You’ll discover how companies like Netflix and Amazon structure their systems to handle massive traffic spikes without breaking a sweat.
Next, we’ll dive deep into database performance optimization and microservices best practices. You’ll see how to design data layers that stay fast even with terabytes of information and learn the real-world strategies for microservices deployment that actually work in production.
Finally, we’ll cover system monitoring and observability along with DevOps system integration. Because building a great system is only half the battle – you need to know when something’s wrong and fix it fast.
Core Architecture Principles for Scalable Systems
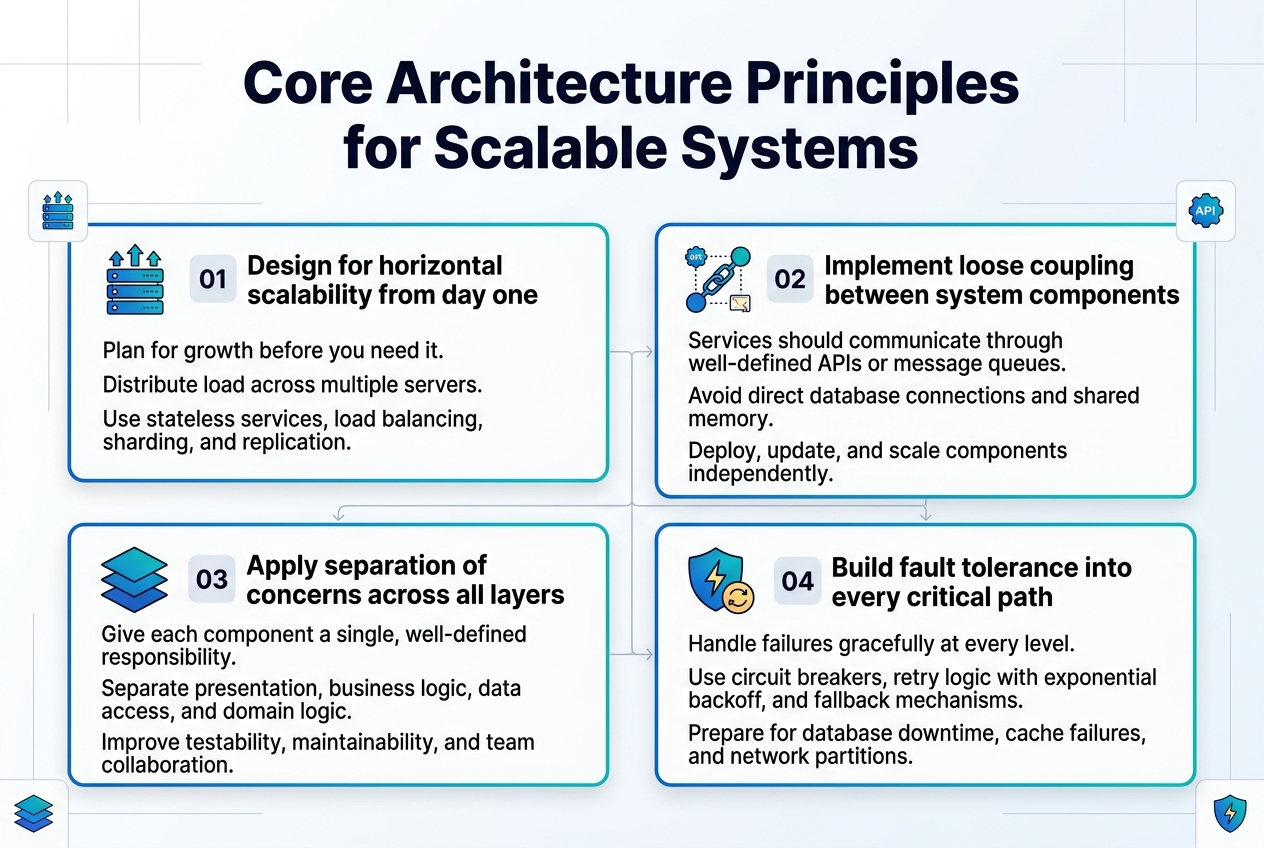
Design for horizontal scalability from day one
Building scalable system design architecture requires planning for growth before you need it. Design your application to distribute load across multiple servers rather than relying on vertical scaling alone. This means creating stateless services, implementing proper load balancing strategies, and choosing database solutions that support sharding or replication patterns.
Implement loose coupling between system components
Loose coupling forms the backbone of maintainable system architecture patterns. Services should communicate through well-defined APIs or message queues rather than direct database connections or shared memory. This approach enables teams to deploy, update, and scale components independently while reducing the blast radius of failures.
Apply separation of concerns across all layers
Each component in your system should have a single, well-defined responsibility. Separate your presentation layer from business logic, keep data access isolated from domain logic, and maintain clear boundaries between different functional areas. This principle makes your codebase more testable, maintainable, and allows different teams to work on separate concerns without stepping on each other.
Build fault tolerance into every critical path
Production ready systems must gracefully handle failures at every level. Implement circuit breakers to prevent cascading failures, add retry logic with exponential backoff, and design fallback mechanisms for when dependencies are unavailable. Consider what happens when your database goes down, your cache fails, or network partitions occur, and build appropriate safeguards into your architecture.
Database Design Strategies for High Performance
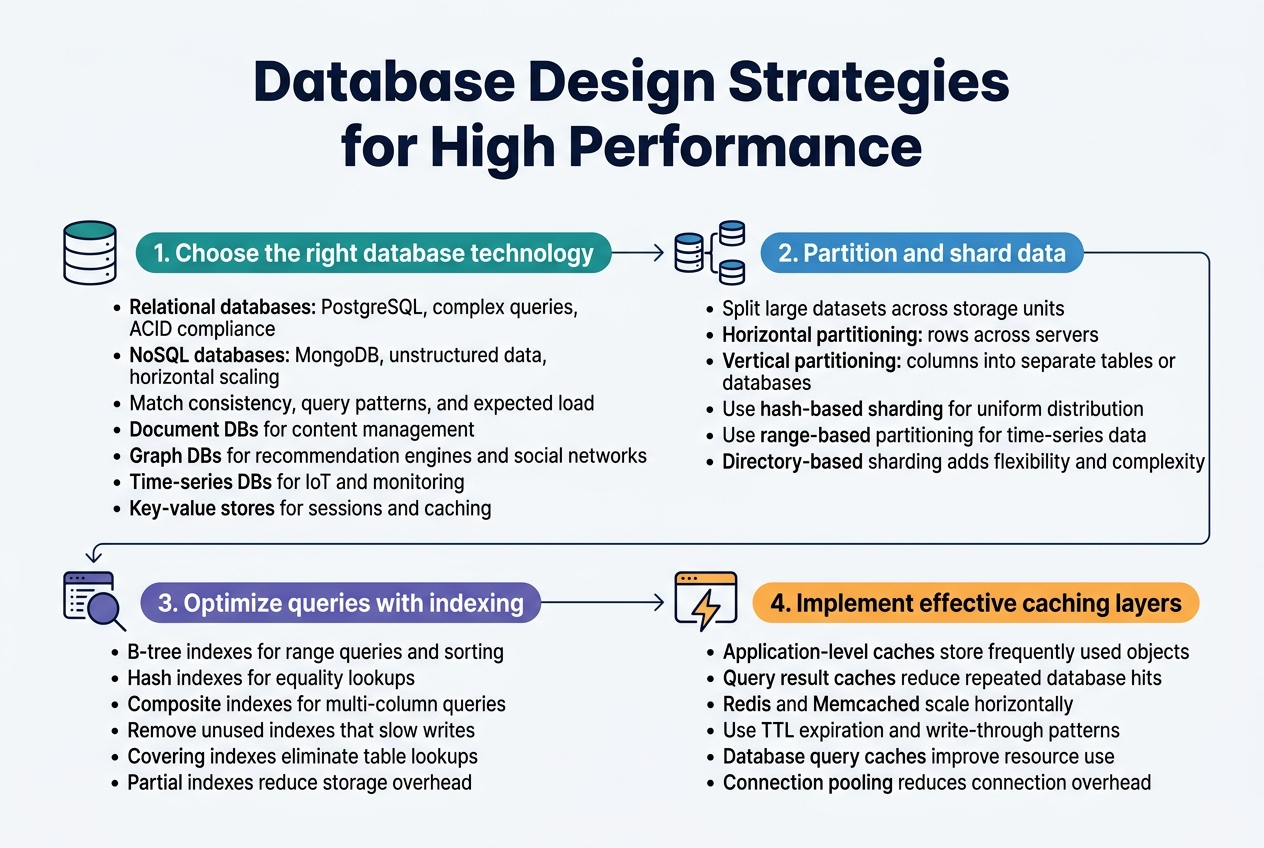
Choose the right database technology for your use case
Selecting the appropriate database technology forms the foundation of high performance database design. Relational databases like PostgreSQL excel for complex queries and ACID compliance, while NoSQL solutions like MongoDB handle unstructured data and horizontal scaling better. Consider your data consistency requirements, query patterns, and expected load when making this decision.
Document databases work well for content management systems, while graph databases shine in recommendation engines and social networks. Time-series databases optimize for IoT and monitoring data, whereas key-value stores provide lightning-fast lookups for session management and caching scenarios.
Master data partitioning and sharding techniques
Data partitioning splits large datasets across multiple storage units to improve query performance and enable parallel processing. Horizontal partitioning (sharding) distributes rows across different servers based on partition keys, while vertical partitioning separates columns into different tables or databases.
Smart sharding strategies prevent hotspots by evenly distributing data and queries. Hash-based sharding works for uniform distribution, while range-based partitioning suits time-series data. Directory-based sharding offers flexibility but adds complexity through lookup services.
Optimize query performance through proper indexing
Strategic indexing dramatically improves query execution times by creating efficient data access paths. B-tree indexes excel for range queries and sorting operations, while hash indexes optimize equality lookups. Composite indexes support multi-column queries but require careful column ordering based on query selectivity.
Monitor index usage patterns and remove unused indexes that slow down write operations. Covering indexes include all required columns in the index itself, eliminating table lookups. Partial indexes reduce storage overhead by indexing only specific rows that match defined conditions.
Implement effective caching layers for faster access
Multi-level caching strategies reduce database load and improve response times across your scalable system design. Application-level caches store frequently accessed objects in memory, while query result caches eliminate repeated database hits for identical requests.
Redis and Memcached provide distributed caching solutions that scale horizontally with your application. Implement cache invalidation strategies like TTL expiration and write-through patterns to maintain data consistency. Database query caches and connection pooling optimize resource utilization and reduce connection overhead.
Microservices Architecture Best Practices
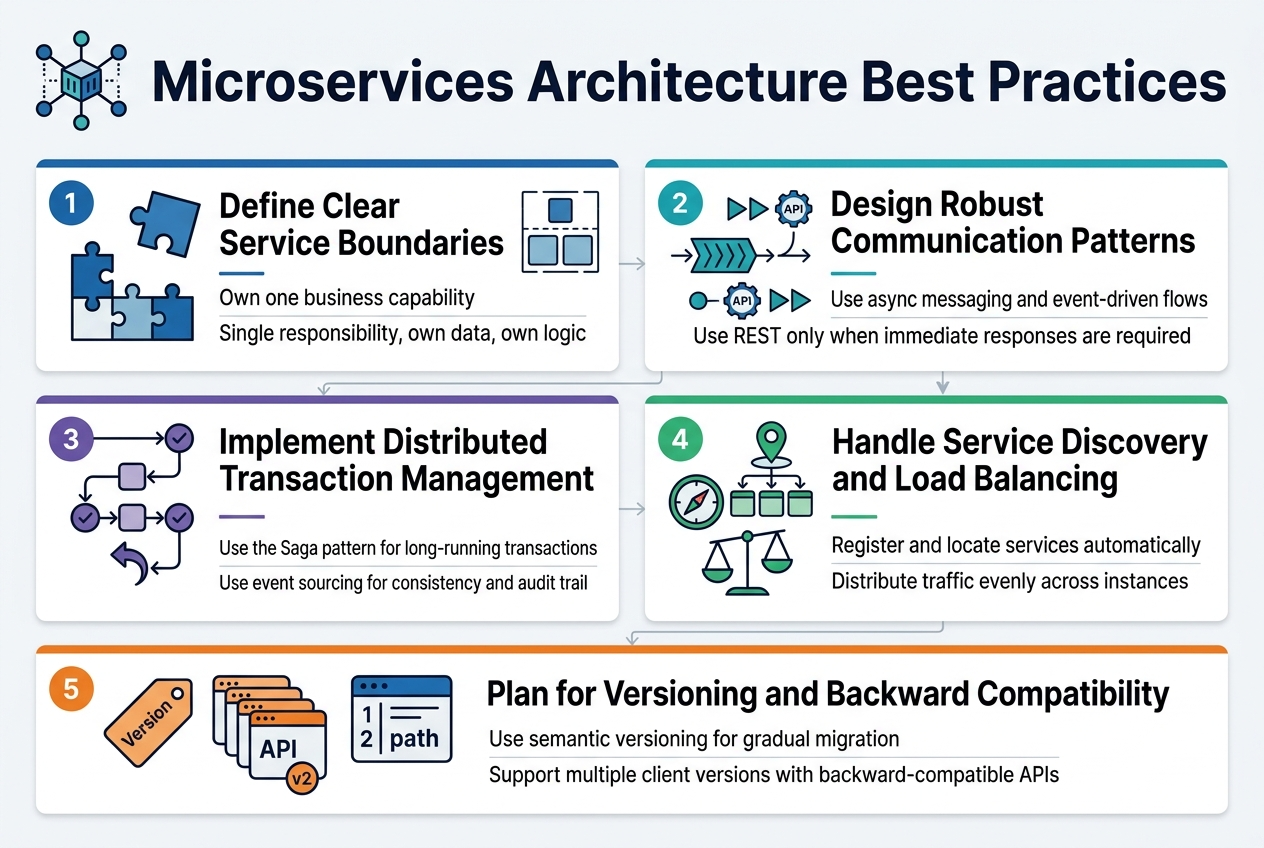
Define clear service boundaries and responsibilities
Establishing precise service boundaries requires identifying business capabilities and ensuring each microservice owns a specific domain. Each service should have a single responsibility, managing its own data and business logic without overlapping with other services. This approach prevents tight coupling and enables teams to develop, deploy, and scale services independently while maintaining clear ownership.
Design robust inter-service communication patterns
Effective microservices best practices demand thoughtful communication strategies between services. Implement asynchronous messaging patterns using message queues or event-driven architectures to reduce direct dependencies. Choose REST APIs for synchronous calls when immediate responses are required, but avoid chatty interfaces that create performance bottlenecks.
Implement distributed transaction management
Managing transactions across multiple services presents unique challenges in scalable system design. Adopt the Saga pattern to handle long-running transactions by breaking them into smaller, compensatable steps. Event sourcing can also provide transaction consistency while maintaining an audit trail of all changes across your distributed system.
Handle service discovery and load balancing efficiently
Service discovery mechanisms automatically register and locate services within your microservices deployment strategies. Use tools like Consul or Kubernetes native discovery to eliminate hardcoded service endpoints. Implement client-side or server-side load balancing to distribute traffic evenly and improve fault tolerance across service instances.
Plan for service versioning and backward compatibility
Version management becomes critical as services evolve independently. Implement semantic versioning strategies that allow gradual migration between service versions. Design APIs with backward compatibility in mind, using techniques like API versioning through headers or URL paths to support multiple client versions simultaneously.
Performance Optimization Techniques
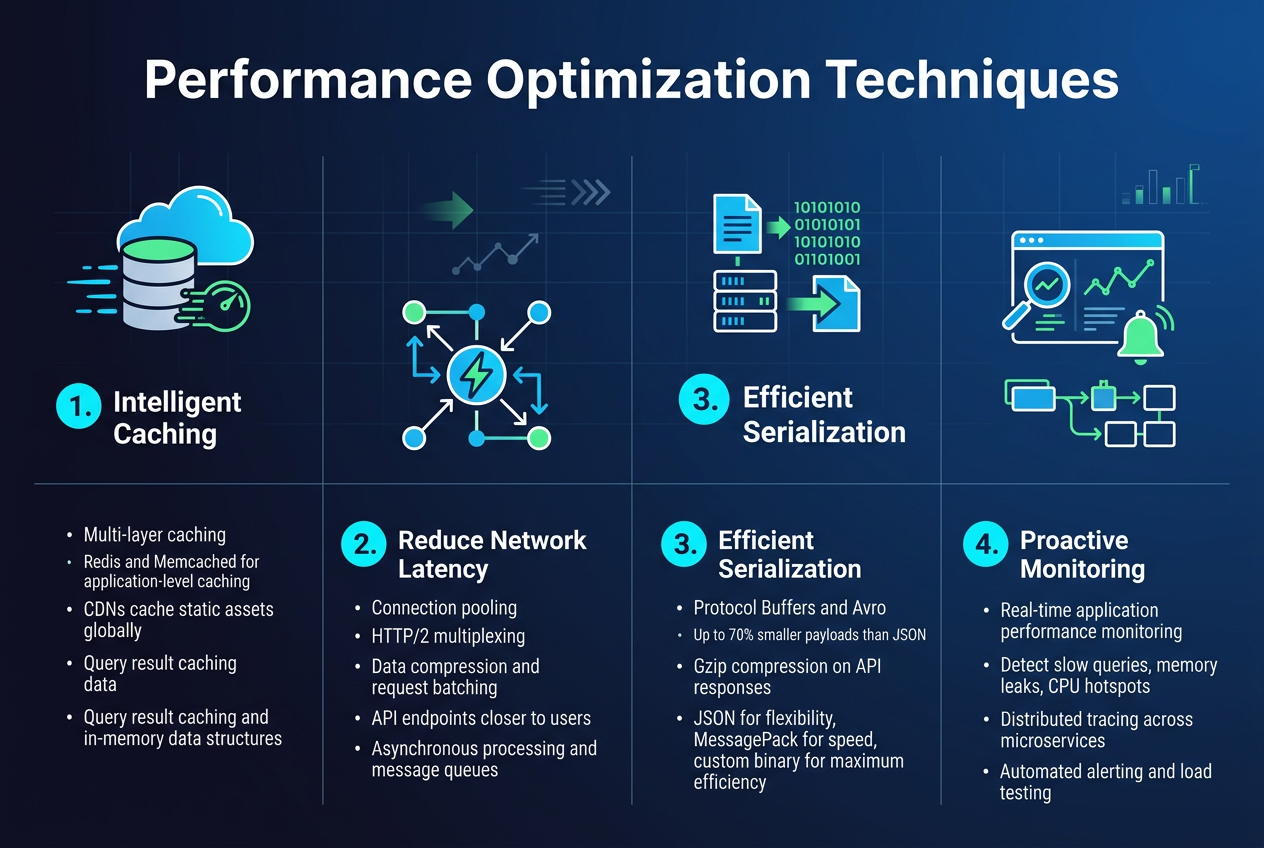
Implement intelligent caching strategies across all tiers
Multi-layer caching transforms system performance by storing frequently accessed data closer to users. Redis and Memcached handle application-level caching, while CDNs cache static assets globally. Database query result caching and in-memory data structures reduce expensive computations, creating dramatic speed improvements across your scalable system design.
Optimize network communication and reduce latency
Connection pooling and HTTP/2 multiplexing eliminate redundant network overhead. Implementing data compression, request batching, and strategic API endpoint placement near users cuts response times significantly. Asynchronous processing and message queues decouple services, allowing systems to handle traffic spikes without blocking critical operations.
Design efficient data serialization and compression
Protocol buffers and Avro outperform JSON for high-throughput scenarios by reducing payload sizes up to 70%. Gzip compression on API responses and smart binary encoding minimize bandwidth usage. Choose serialization formats based on your specific use case – JSON for flexibility, MessagePack for speed, or custom binary protocols for maximum efficiency.
Monitor and eliminate performance bottlenecks proactively
Real-time application performance monitoring reveals slow database queries, memory leaks, and CPU hotspots before they impact users. Distributed tracing across microservices pinpoints exactly where delays occur. Automated alerting systems catch performance degradation early, while load testing simulates production traffic to identify scaling limits and optimization opportunities.
Security Considerations for Production Systems
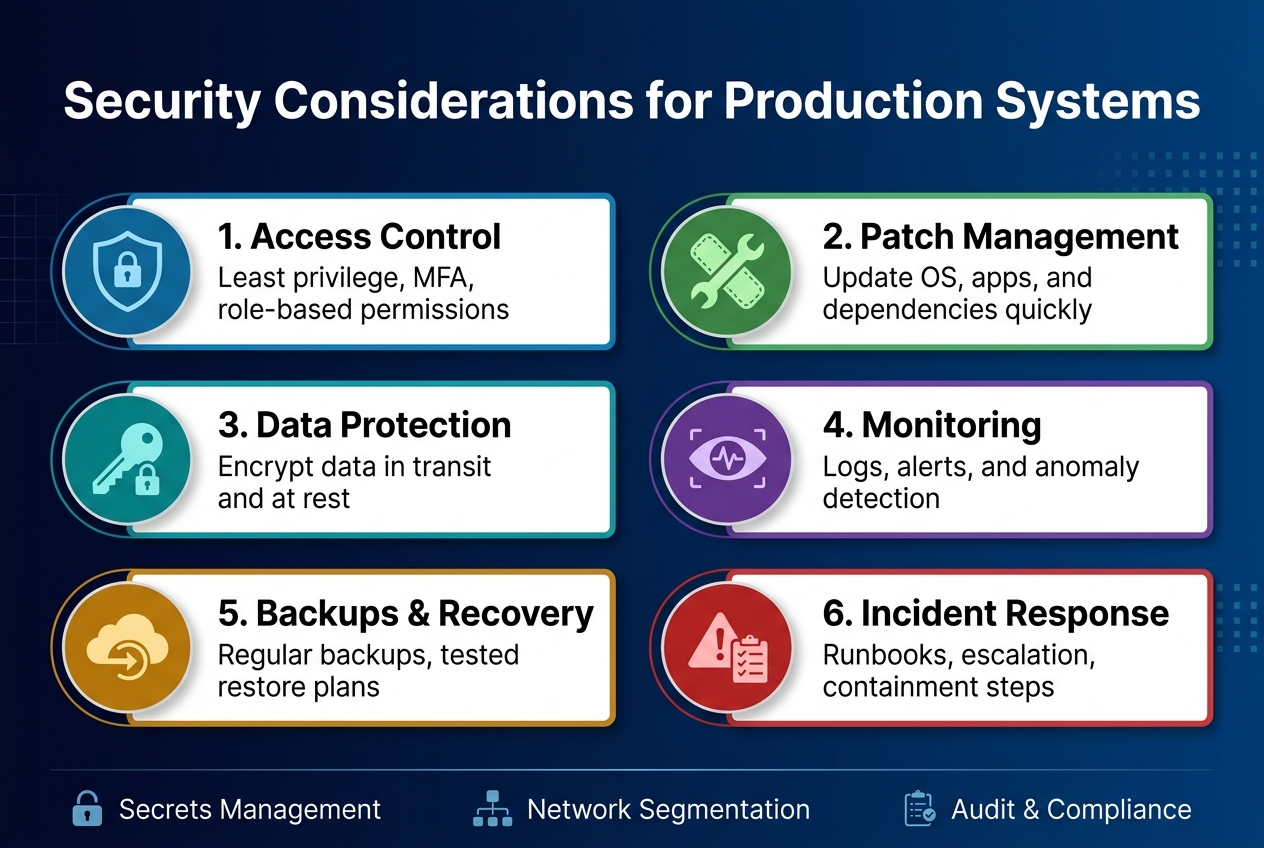
Implement defense-in-depth security architecture
Production-ready systems need multiple security layers that protect against different attack vectors. This approach combines network segmentation, application-level controls, and infrastructure hardening to create redundant protection mechanisms. Each layer should operate independently, so if one fails, others continue protecting your system architecture patterns.
Design secure authentication and authorization flows
Strong authentication requires multi-factor verification and proper session management across your scalable system design. OAuth 2.0 with PKCE provides secure token exchange, while role-based access control ensures users access only authorized resources. JWT tokens should include proper expiration and refresh mechanisms to maintain security without compromising user experience in production ready systems.
Protect against common security vulnerabilities
- Input validation: Sanitize all user inputs to prevent SQL injection and XSS attacks
- HTTPS enforcement: Use TLS 1.3 for all communications between services
- Dependency scanning: Regular updates and vulnerability assessments for third-party libraries
- Rate limiting: Implement throttling to prevent brute force and DDoS attacks
Establish comprehensive audit logging and monitoring
Security monitoring captures user actions, system changes, and potential threats in real-time. Centralized logging systems should track authentication attempts, data access patterns, and configuration changes across your entire infrastructure. Alert mechanisms must trigger immediately when suspicious activities occur, enabling rapid incident response.
Monitoring and Observability Implementation
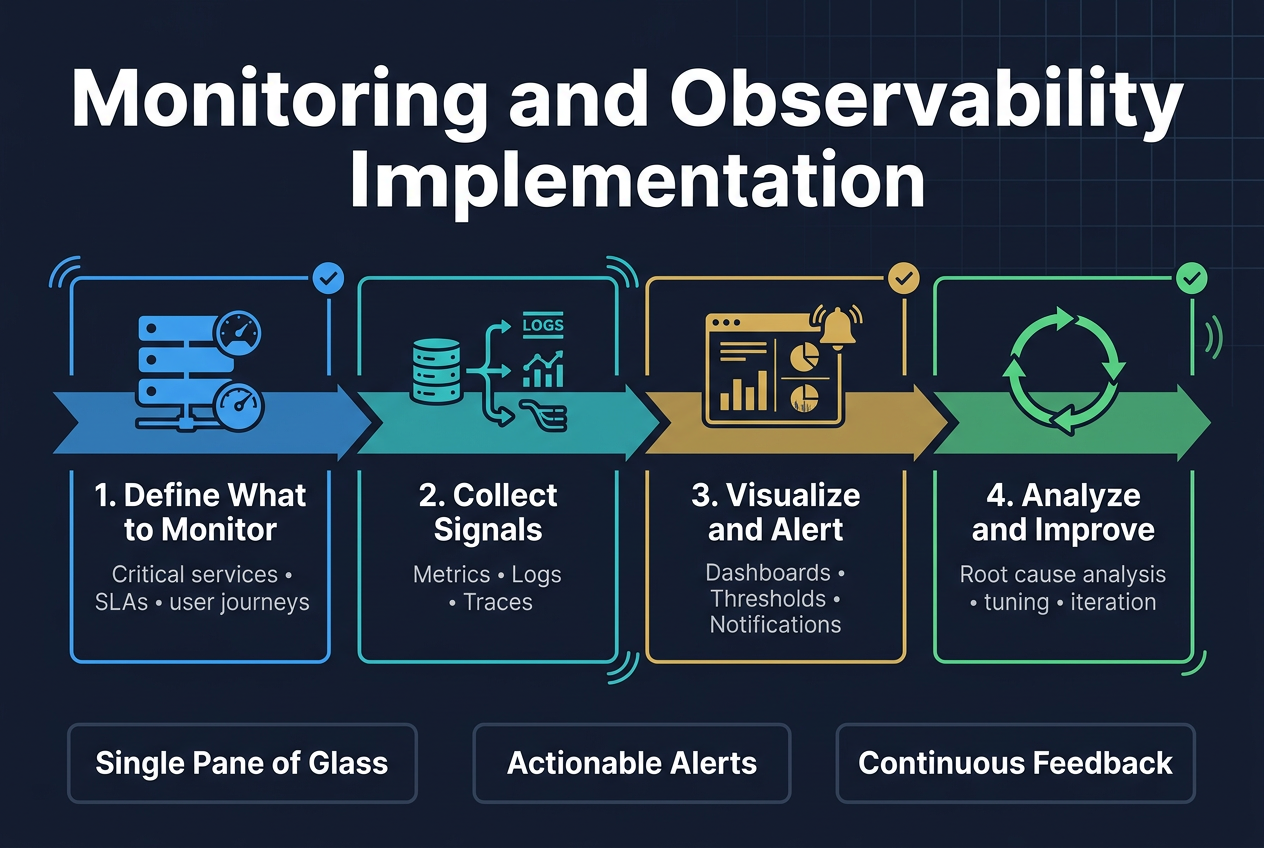
Set up comprehensive application and infrastructure monitoring
Effective system monitoring and observability requires a multi-layered approach that covers both application performance metrics and underlying infrastructure health. Modern production ready systems demand real-time visibility into CPU usage, memory consumption, network latency, and application-specific metrics like request throughput and error rates. Tools like Prometheus, Grafana, and New Relic provide the foundation for collecting, storing, and visualizing these critical data points across your entire technology stack.
Design effective alerting systems for rapid response
Smart alerting systems prevent alert fatigue while ensuring critical issues get immediate attention. Configure alerts based on meaningful thresholds that indicate actual business impact rather than arbitrary technical metrics. Use escalation policies that route alerts to the right team members based on severity levels and time of day. Integrate with communication platforms like Slack or PagerDuty to streamline incident response workflows.
Implement distributed tracing for complex workflows
Distributed tracing becomes essential when dealing with microservices best practices and complex request flows across multiple services. Tools like Jaeger and Zipkin help track requests as they traverse your system architecture patterns, identifying bottlenecks and failure points in real-time. This visibility proves invaluable for debugging performance issues and understanding system dependencies in production environments.
Create actionable dashboards for operational visibility
Well-designed dashboards transform raw monitoring data into actionable insights for development and operations teams. Focus on displaying key business metrics alongside technical performance indicators, using clear visualizations that highlight trends and anomalies. Group related metrics logically and provide drill-down capabilities that allow teams to investigate issues quickly without switching between multiple tools or interfaces.
Deployment and DevOps Integration
Design Automated CI/CD Pipelines for Reliable Releases
Building robust CI/CD pipelines forms the backbone of modern DevOps system integration. Automated pipelines should include comprehensive testing stages, from unit tests to integration testing, ensuring code quality before production deployment. Configure automated triggers for code commits, implement parallel testing environments, and establish clear approval gates for production releases.
Integrate security scanning, dependency checks, and performance benchmarks directly into your pipeline workflow. Use tools like Jenkins, GitLab CI, or GitHub Actions to orchestrate these processes seamlessly, creating a reliable path from development to production that minimizes human error and accelerates delivery cycles.
Implement Blue-Green and Canary Deployment Strategies
Blue-green deployments eliminate downtime by maintaining two identical production environments, switching traffic instantly between versions. This approach provides immediate rollback capabilities and ensures zero-downtime releases for production ready systems. Canary deployments offer gradual risk mitigation by routing small percentages of traffic to new versions before full rollout.
Implement feature flags and traffic splitting mechanisms to control user exposure during deployments. Monitor key metrics during canary releases, automatically rolling back when error rates or performance metrics exceed predefined thresholds, ensuring system reliability throughout the deployment process.
Configure Infrastructure as Code for Consistency
Infrastructure as Code (IaC) eliminates configuration drift and ensures reproducible environments across development, staging, and production. Tools like Terraform, Ansible, or AWS CloudFormation enable version-controlled infrastructure management, treating infrastructure changes with the same rigor as application code changes.
Define infrastructure templates that capture networking, security groups, load balancers, and compute resources. This approach enables rapid environment provisioning, simplifies disaster recovery, and ensures consistent configurations across all deployment stages while supporting scalable system design principles.
Establish Effective Rollback and Disaster Recovery Procedures
Prepare automated rollback mechanisms that activate within minutes of detecting critical issues. Document clear escalation procedures, define rollback triggers based on specific metrics, and maintain database migration rollback scripts. Test rollback procedures regularly to ensure they work when needed most.
Implement comprehensive backup strategies including database snapshots, configuration backups, and application state preservation. Create runbooks for common failure scenarios, establish communication protocols for incident response, and maintain updated contact lists for emergency situations to minimize system downtime.

Building robust systems that can handle real-world demands requires mastering several interconnected disciplines. You need solid architectural foundations that can scale, smart database choices that keep performance high, and microservices that actually make your life easier instead of more complicated. The technical pieces matter, but so does getting the operational side right with proper monitoring, security, and deployment practices.
The difference between a system that works in development and one that thrives in production comes down to the details. Start with these fundamentals, but remember that system design is an ongoing process. Your monitoring will tell you where the bottlenecks really are, your security practices will evolve with new threats, and your architecture will need adjustments as your product grows. Focus on building something that works today while keeping tomorrow’s challenges in mind.








