








Looking to build faster, more scalable cloud applications? AWS serverless architecture helps developers create high-performance systems without managing infrastructure. This guide is for cloud architects, DevOps engineers, and backend developers who need to optimize their serverless applications.
We’ll explore practical latency optimization strategies that reduce response times and improve user experience. You’ll also learn throughput maximization techniques to handle more concurrent requests without performance degradation. Throughout, we’ll examine real-world architectures that successfully balance these performance factors in production environments.
Understanding Serverless Architecture in AWS
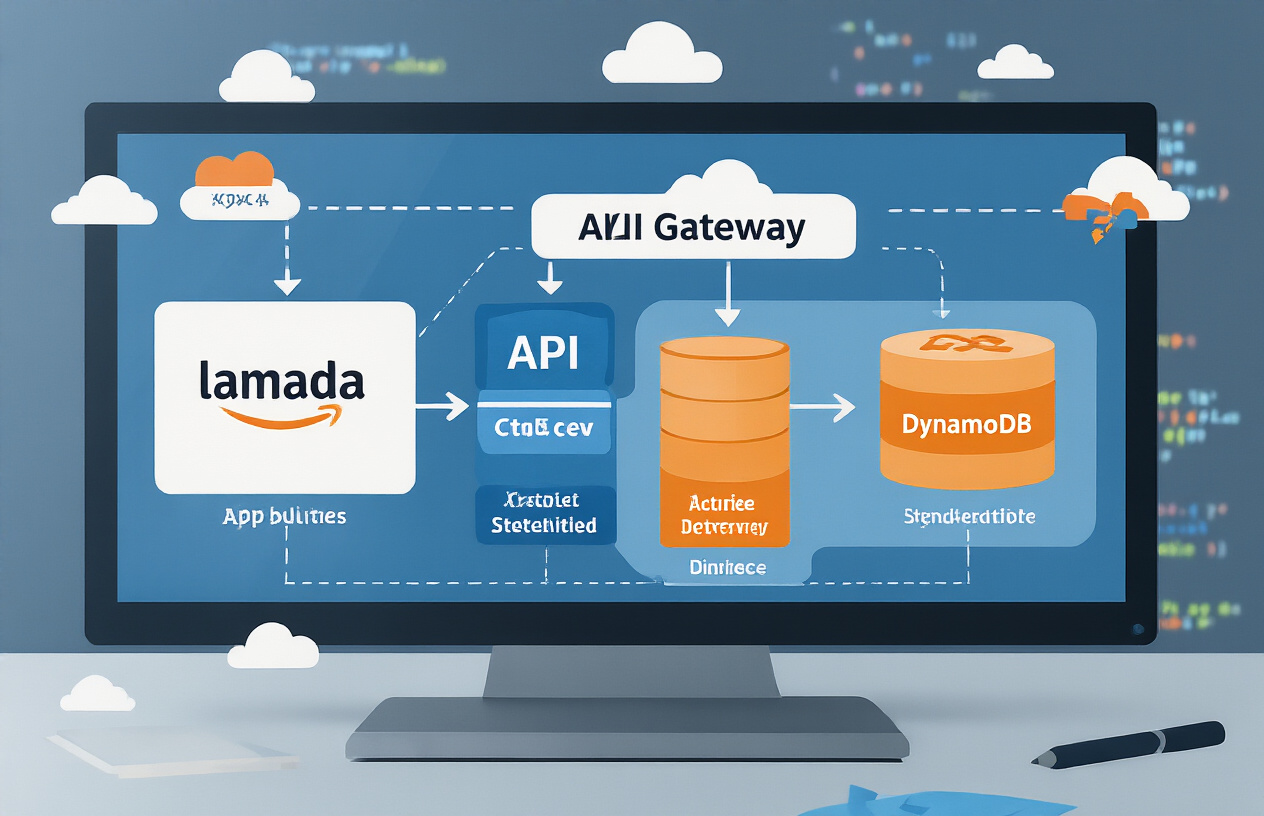
Key Components of AWS Serverless Stack
AWS serverless architecture isn’t just a buzzword—it’s a powerful approach that eliminates infrastructure management headaches. At its core, you’ll find these essential components:
- AWS Lambda – The compute powerhouse that runs your code without servers. Just upload your function, and Lambda handles everything else.
- Amazon API Gateway – Creates HTTP endpoints that trigger your Lambda functions. It’s your front door to serverless APIs.
- DynamoDB – A lightning-fast NoSQL database that scales automatically with your workload.
- S3 – Object storage that can trigger Lambda functions when files are added or modified.
- EventBridge – The event bus that connects your serverless components together.
Benefits for Latency and Throughput Optimization
The serverless approach isn’t just convenient—it’s a performance game-changer:
- Automatic scaling – Your functions scale instantly from zero to thousands of concurrent executions. No capacity planning needed.
- Edge deployment – With Lambda@Edge and CloudFront, your code runs closer to users, slashing latency dramatically.
- Parallel execution – Each request gets its own isolated environment, enabling true horizontal scaling without the overhead.
- Pay-per-use pricing – You’re only charged for actual compute time, making it cost-effective to over-provision for performance.
Common Misconceptions About Serverless Performance
Many developers get serverless performance wrong. Here’s the truth:
Myth: “Cold starts make serverless too slow for production.”
Reality: Cold starts are manageable with provisioned concurrency, keeping functions warm, and code optimization.
Myth: “Serverless can’t handle high-throughput workloads.”
Reality: With proper design patterns (like chunking, batching, and asynchronous processing), serverless architectures can handle massive throughput.
Myth: “Traditional databases work fine with serverless.”
Reality: Connection-based databases struggle with serverless. Purpose-built solutions like DynamoDB or Aurora Serverless provide better performance.
Myth: “Serverless is only good for simple applications.”
Reality: Even complex, high-performance systems can thrive on serverless—companies like Netflix, Coca-Cola, and Capital One run critical workloads this way.
Measuring Performance in Serverless Applications

Essential Metrics for Latency Monitoring
Tracking the right metrics is half the battle when optimizing serverless performance. Focus on these key latency indicators:
- Duration – The time your function takes to execute code
- Initialization time – How long cold starts take to initialize your container
- Service integration latency – Delays when connecting to DynamoDB, S3, etc.
- End-to-end latency – Total time from API Gateway request to response
Don’t just look at averages! The p95 and p99 percentiles tell you what your worst-case scenarios look like. That’s what your users remember.
Throughput Benchmarking Techniques
Want to know your serverless app’s limits? Here’s how to benchmark properly:
- Gradual load increases – Start with 10 requests/sec and double until you see degradation
- Concurrent execution testing – Push beyond your account limits to see what breaks
- Synthetic workloads – Create realistic test patterns that mimic your production traffic
Tools like Artillery and Locust make this way easier than building your own testing harness.
Setting Up CloudWatch for Performance Insights
CloudWatch is your best friend for serverless monitoring, but the default metrics won’t cut it:
# Create a custom CloudWatch dashboard with:
- Lambda Execution Duration (p50, p90, p99)
- Throttled invocations
- Error rates
- Concurrent executions
Set up custom metrics for business-specific insights. Don’t forget to create alarms for latency thresholds – you want to know when things go south before your customers do.
Using X-Ray for Distributed Tracing
CloudWatch tells you something’s wrong. X-Ray tells you exactly where.
X-Ray’s distributed tracing gives you a visual map of your entire request flow. You’ll spot bottlenecks in seconds that might take hours to find otherwise.
Enable it with just three steps:
- Add the X-Ray SDK to your Lambda functions
- Set the
Active Tracingoption in your Lambda config - Add the necessary IAM permissions
The service map view is gold – it shows you exactly which connections between services are causing delays. The trace timeline breaks down execution times for each component, so you can see if it’s your code or an AWS service causing the holdup.
Latency Optimization Strategies

A. Cold Start Mitigation Techniques
Cold starts are the bane of serverless functions. They happen when your function hasn’t been used recently and AWS needs to provision a new container.
Want to slash those pesky cold start times? Try these approaches:
- Keep functions warm with scheduled CloudWatch Events that ping your functions every few minutes
- Code smartly by moving initialization code outside the handler function
- Use languages with faster startup times like Node.js or Python instead of Java or .NET
- Minimize dependencies – each extra package adds startup overhead
One developer I know reduced cold start times from 3 seconds to 200ms just by moving database connection code outside the handler. That’s a 15x improvement with a simple code reorganization!
B. Provisioned Concurrency Implementation
Provisioned Concurrency is AWS’s official answer to cold starts. It keeps functions initialized and ready to respond instantly.
Setting it up is straightforward:
aws lambda put-provisioned-concurrency-config \
--function-name my-function \
--qualifier my-version \
--provisioned-concurrent-executions 10
The real challenge is finding the right number. Too many pre-warmed instances wastes money; too few means some users still hit cold starts.
Start by analyzing your traffic patterns. If you get consistent traffic with predictable spikes, you can use Application Auto Scaling to adjust provisioned concurrency automatically based on utilization metrics.
Remember – you’re paying for every millisecond of provisioned concurrency, so use it wisely!
C. Function Size and Memory Configuration Impact
Your Lambda function size and memory allocation dramatically affect performance.
Memory and CPU power are linked in Lambda – more memory means more CPU. This has a direct impact on execution time:
| Memory (MB) | Typical Processing Time | Relative Cost |
|---|---|---|
| 128 | 10 seconds | 1x |
| 512 | 3 seconds | 1.2x |
| 1024 | 1.5 seconds | 1.5x |
| 3008 | 0.5 seconds | 3x |
The sweet spot? Often it’s around 1024MB, where you get significant speed improvements without breaking the bank.
Package size matters too. Keep your deployment packages small by:
- Using layer for dependencies
- Excluding unnecessary files with .lambdaignore
- Compressing images and other assets
I’ve seen functions drop from 5-second execution times to under 500ms just by right-sizing memory and trimming package bloat.
D. Regional Deployment Considerations
Where you deploy matters – a lot.
Deploying your serverless stack in the same region as your users can cut latency by 50-200ms simply by reducing physical distance.
For global applications, consider multi-region deployments with Route 53 latency-based routing. This directs users to the closest region automatically.
Edge functions take this further. Lambda@Edge and CloudFront Functions run your code at AWS edge locations, even closer to users. Perfect for tasks like:
- Authentication
- Request manipulation
- Simple transformations
- A/B testing
Don’t forget about data locality. When your function needs to access data, having that data in the same region eliminates cross-region latency penalties. Cross-region database calls can add 100ms+ to response times.
E. API Gateway Optimization
API Gateway sits between users and your Lambda functions, so optimizing it is critical for end-to-end performance.
First, choose the right flavor:
- HTTP API: Fastest and cheapest, but fewer features
- REST API: More features, higher latency
- WebSocket API: For real-time, bidirectional communication
Enable caching to serve repeated requests instantly. A properly configured cache can reduce load and improve response times by an order of magnitude.
{
"cachingEnabled": true,
"cacheTtlInSeconds": 300,
"cacheKeyParameters": ["method.request.path.param"]
}
Response compression is another easy win. Enable it with:
{
"minimumCompressionSize": 1024
}
For complex APIs, consider request validation and response mapping templates. They add minimal overhead but can eliminate unnecessary Lambda invocations for invalid requests.
Maximizing Throughput in Serverless Applications

Parallel Processing Patterns
Serverless architectures shine when you leverage parallel processing. Want massive throughput? Break workloads into smaller chunks and process them simultaneously.
Fan-out patterns work wonders here. Trigger a Lambda function that spawns multiple child functions, each handling a slice of your workload. This approach can scale to handle thousands of simultaneous executions with minimal code.
Lambda (coordinator) → SQS/SNS → Multiple Lambda workers
Map-reduce patterns fit perfectly in serverless too. Map your data across distributed workers, then aggregate results. AWS Step Functions makes this dead simple with its Map state.
One trick most developers miss: tune your Lambda concurrency limits. The default account limit is 1,000 concurrent executions, but you can request increases or reserve concurrency for critical functions.
Asynchronous Communication Models
Sync processing is the throughput killer. You’re basically standing in line at the DMV when you could be dropping things in mailboxes.
Event-driven architectures absolutely crush it for throughput. Instead of waiting for responses, your functions publish events and move on to the next task.
AWS gives you several messaging options:
| Service | Best For | Throughput Capability |
|---|---|---|
| SNS | Fanout notifications | Millions/second |
| SQS | Work queues, buffering | Virtually unlimited |
| EventBridge | Complex event routing | 10,000+ events/second |
| Kinesis | High-volume streaming | MB to GB/second |
The big win? Decoupled systems that can scale independently. When your order service is getting hammered, your inventory service keeps humming along.
Efficient Data Transfer Techniques
Data transfer bottlenecks will murder your throughput faster than anything else.
First rule: minimize payload sizes. JSON is readable but bloated. Consider binary formats like Protocol Buffers or Avro for high-volume data. They’re typically 30-60% smaller than JSON.
Second rule: move your data less. Use services that sit close to your data:
- Lambda@Edge for content near users
- DynamoDB Accelerator (DAX) for caching
- S3 Transfer Acceleration for large file uploads
Compression is your friend but comes with CPU cost. For Lambdas, the tradeoff usually favors compression since network is often the bottleneck, not compute.
Batch Processing Implementation
Individual request processing is for amateurs. Real throughput comes from batching.
Lambda batch processing is built right in for many event sources:
- SQS can trigger Lambda with batches up to 10,000 messages
- Kinesis can process thousands of records per invocation
- DynamoDB Streams supports multi-record processing
The magic formula:
Optimal batch size = f(processing time, tolerable latency)
Too small? You waste invocations. Too large? You risk timeouts and slow processing.
Dynamic batching takes this to the next level. Instead of fixed batch sizes, implement adaptive algorithms that adjust based on current load and processing times.
Remember to implement partial batch failures correctly. When 9 records succeed and 1 fails, don’t reprocess everything – just the failure.
Data Storage Considerations for Performance

A. Choosing Between DynamoDB, RDS, and Aurora Serverless
When building serverless apps, your database choice can make or break your performance. Let’s break down the options:
DynamoDB shines for raw speed and scale. It delivers single-digit millisecond responses consistently, even at massive scale. Perfect for high-throughput applications that need predictable performance.
RDS gives you traditional relational database power when you need complex queries and transactions. The tradeoff? Higher latency than DynamoDB and more complex scaling.
Aurora Serverless sits in the sweet spot for many applications. You get relational capabilities with auto-scaling that spins up/down based on demand. No capacity planning needed.
Here’s a quick comparison:
| Database | Latency | Scaling | Best For |
|---|---|---|---|
| DynamoDB | Lowest | Automatic, immediate | Simple access patterns, high throughput |
| RDS | Moderate | Manual, requires planning | Complex queries, ACID compliance |
| Aurora Serverless | Moderate | Automatic, with brief pause | Variable workloads, relational needs |
The winner? There isn’t one. DynamoDB crushes it for simple, high-speed access patterns. Aurora Serverless works better when you need SQL without the operational overhead.
B. Caching Strategies with ElastiCache and DAX
Caching transforms serverless performance. Two AWS services dominate this space:
DynamoDB Accelerator (DAX) is purpose-built for DynamoDB. It slashes response times from milliseconds to microseconds – we’re talking 10x improvement on read operations. Setup takes minutes and requires minimal code changes.
ElastiCache gives you Redis or Memcached as a service. More flexible than DAX but requires more configuration. Redis works brilliantly for complex data types and advanced operations.
Implement these winning patterns:
- Use DAX for read-heavy DynamoDB workloads
- Set up ElastiCache Redis for session storage or leaderboards
- Implement a write-through strategy to keep cache and database in sync
- Consider TTL settings carefully – too short defeats the purpose, too long risks stale data
Smart caching reduces database load and cuts costs. Plus, your users get that snappy experience they expect.
C. S3 Performance Optimization Techniques
S3 seems simple but has hidden performance levers you can pull:
Request rate optimization matters. S3 can handle thousands of requests per second per prefix. Spread your workload across multiple prefixes to avoid throttling. Instead of /logs/2023/, try adding random prefixes: /logs/a123/2023/.
Transfer Acceleration leverages AWS’s edge network to speed up uploads and downloads. Enable it with a single checkbox and watch cross-region transfers fly.
S3 Select lets you retrieve only the data you need instead of entire objects. When working with large CSV or JSON files, this cuts both transfer costs and latency dramatically.
Partition strategy is crucial for high-performance applications:
# Instead of this (can bottleneck)
s3://bucket/logs/YYYY-MM-DD/
# Do this (better distribution)
s3://bucket/logs/YYYY/MM/DD/random-prefix/
Finally, consider S3’s storage classes carefully. If you need the lowest latency, stick with S3 Standard. Infrequent Access or Glacier tiers save money but add retrieval delays that kill performance.
Real-world Serverless Architectures for High Performance

A. Event-Driven Processing Pipelines
Building event-driven pipelines on AWS serverless is like creating a domino chain that actually works every time. When one service completes its task, it automatically triggers the next.
Take a financial services company I worked with. They switched from batch processing transactions every hour to real-time processing using:
- Amazon SQS for message buffering
- Lambda functions for transaction validation
- EventBridge for orchestration
- DynamoDB for state management
The results? Transaction processing latency dropped from minutes to milliseconds. And the best part? Their architecture automatically scaled during peak trading hours without a single engineer getting paged.
The secret sauce was decoupling each step. When a payment came in, SQS buffered it, Lambda processed it, and DynamoDB recorded the state—all happening independently. This pattern eliminated bottlenecks since no component had to wait for another.
B. High-Volume API Implementations
APIs handling millions of requests need special attention. A gaming company I advised built their leaderboard API using:
API Gateway → Lambda → DynamoDB (with DAX) → CloudFront
They shaved response times from 300ms to under 50ms by:
- Using API Gateway caching for repeated requests
- Implementing DynamoDB DAX for read-heavy operations
- Adding CloudFront to cache responses at edge locations
The game-changer? Provisioned concurrency for their Lambda functions. By warming 50 instances during peak gaming hours, they eliminated cold starts completely.
C. Real-Time Analytics Solutions
Real-time analytics on serverless isn’t just possible—it’s preferable. A retail client built a solution that tracks shopping behavior as it happens:
- Kinesis Data Streams captured clickstream data
- Lambda functions transformed and enriched events
- ElastiCache provided temporary storage for aggregations
- DynamoDB stored the final analytics results
They could see shopping trends develop in seconds rather than waiting for overnight batch processing. This let them adjust promotions in real-time when products started trending.
The performance trick was sizing the Kinesis shards correctly. Too few shards created bottlenecks; too many wasted money.
D. Hybrid Architectures for Complex Workloads
Sometimes the best serverless architecture includes… servers. A media company I consulted with used:
- EC2 instances for video transcoding (compute-intensive)
- Lambda functions for metadata extraction and notifications
- Step Functions for workflow orchestration
- S3 for content storage
This hybrid approach gave them the best of both worlds: predictable performance for heavy processing and cost-efficiency for everything else.
They reduced their infrastructure costs by 62% while improving throughput by setting intelligent boundaries between serverless and traditional resources.
Testing and Validation for Performance

Load Testing Serverless Applications
You think your serverless app is ready for prime time? Think again until you’ve properly load tested it.
Unlike traditional architectures, serverless applications behave differently under load. That Lambda function that performs perfectly with a few requests might fall apart when hit with thousands of concurrent executions.
Start with defining clear testing goals:
- Response time thresholds
- Maximum acceptable error rates
- Throughput requirements
- Concurrency targets
The real magic happens when you test different scenarios:
- Steady state load (consistent traffic)
- Spike testing (sudden traffic surges)
- Endurance testing (sustained high load)
Don’t forget to simulate real-world conditions! A perfectly sequential test won’t reveal how your architecture handles chaotic real-world patterns.
Performance Testing Tools and Frameworks
The right tools make all the difference when testing serverless performance:
AWS-specific tools:
- AWS X-Ray: Tracks requests as they travel through your application
- CloudWatch Synthetics: Creates canaries that monitor endpoints and APIs
- Amazon CodeGuru: Identifies performance bottlenecks in your code
Open-source options:
- Artillery: Perfect for Lambda function load testing
- Serverless Framework Pro: Includes monitoring and debugging capabilities
- Locust: Python-based tool for distributed load testing
Pick your tool based on what you’re testing. Need to simulate 10,000 users hitting an API Gateway? Artillery’s your friend. Want to check Lambda execution times? X-Ray’s got you covered.
Interpreting and Acting on Test Results
Raw test data is useless if you don’t know what to do with it.
First, look for patterns:
- Are failures random or systematic?
- Do performance issues appear at specific concurrency thresholds?
- Which components show increasing latency under load?
Then pinpoint your bottlenecks:
Common Bottlenecks | Potential Solutions
-------------------|--------------------
Cold starts | Provisioned concurrency, code optimization
Database throttling| DAX for DynamoDB, connection pooling
API rate limits | Request batching, exponential backoff
Memory constraints | Increase Lambda memory allocation
When you find issues, don’t just throw resources at the problem. The serverless world rewards smart architecture over brute force scaling.
Remember that performance optimization is never “done.” As your application evolves, keep testing regularly to catch issues before your users do.
Optimizing serverless applications on AWS requires a balanced approach to both latency and throughput. By implementing proper monitoring tools, selecting appropriate memory configurations, and optimizing code execution, you can significantly reduce latency in your applications. For throughput improvements, consider leveraging concurrency controls, batch processing, and asynchronous patterns while carefully selecting the right data storage solutions that align with your application’s access patterns.
As you embark on building high-performance serverless architectures, remember that testing and validation are crucial components of your optimization journey. Use AWS performance testing tools to continuously measure and refine your implementation. Whether you’re handling high-traffic web applications or data-intensive processing tasks, AWS serverless technology offers the flexibility and scalability to meet your performance requirements while maintaining cost efficiency.









