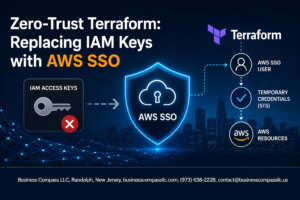
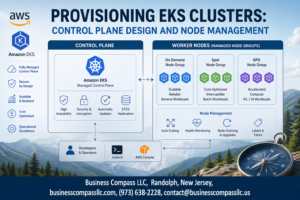
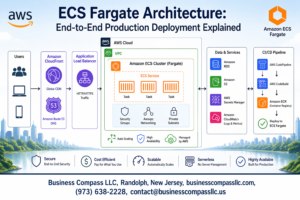
🚀 Are you ready to unlock the full potential of AWS storage services? Whether you’re a seasoned cloud architect or just starting your journey, mastering the art of deploying and managing data storage in AWS is crucial for building robust, scalable applications. But with so many options available, where do you begin?
Fear not! This comprehensive guide will walk you through the ins and outs of AWS storage solutions, from the versatile Amazon S3 to the long-term archival capabilities of Amazon Glacier. We’ll demystify the process of setting up and optimizing each service, ensuring you have the knowledge to make informed decisions for your unique storage needs. By the end of this post, you’ll be equipped with the skills to confidently deploy and manage your data across AWS’s powerful storage ecosystem.
In this step-by-step guide, we’ll cover everything from understanding the fundamentals of AWS storage services to implementing best practices for efficient management. We’ll explore how to set up Amazon S3 for object storage, deploy Amazon EBS for block-level storage, implement Amazon EFS for scalable file systems, leverage Amazon FSx for specialized workloads, and utilize Amazon Glacier for cost-effective archiving. Let’s dive in and transform your AWS storage game! 💪💾
Understanding AWS Storage Services
A. Overview of S3, EBS, EFS, FSx, and Glacier
AWS offers a diverse range of storage solutions to cater to various business needs. Let’s take a quick look at the main storage services:
- Amazon S3 (Simple Storage Service): Object storage for scalable and durable data storage
- Amazon EBS (Elastic Block Store): Block-level storage volumes for EC2 instances
- Amazon EFS (Elastic File System): Fully managed file storage for EC2 instances
- Amazon FSx: Fully managed file systems for popular file storage technologies
- Amazon Glacier: Low-cost storage for data archiving and long-term backup
B. Key features and use cases
| Storage Service | Key Features | Use Cases |
|---|---|---|
| S3 | Scalability, durability, versioning | Static website hosting, data lakes, backup and restore |
| EBS | Low-latency, customizable | Boot volumes, databases, dev/test environments |
| EFS | Shared access, elastic capacity | Big data analytics, content management systems |
| FSx | High-performance, Windows compatibility | Enterprise applications, home directories |
| Glacier | Low-cost, long-term retention | Compliance archives, digital preservation |
C. Comparing storage options
- Performance: EBS and FSx offer the highest performance for low-latency access, while S3 and Glacier prioritize durability over speed.
- Scalability: S3 and EFS provide virtually unlimited scalability, whereas EBS volumes have fixed capacities.
- Cost: Glacier is the most cost-effective for long-term storage, while S3 offers tiered pricing based on access frequency.
- Access patterns: EBS is ideal for frequent, random access, while Glacier is designed for infrequent, sequential access.
Now that we have an overview of AWS storage services, let’s dive into setting up Amazon S3, one of the most versatile and widely used storage solutions.
Setting Up Amazon S3 (Simple Storage Service)
Creating and configuring S3 buckets
To begin setting up Amazon S3, you’ll need to create and configure your S3 buckets. Follow these steps:
- Log in to the AWS Management Console
- Navigate to the S3 service
- Click “Create bucket”
- Choose a globally unique bucket name
- Select the appropriate AWS Region
- Configure bucket settings (e.g., versioning, encryption)
| Setting | Description | Recommendation |
|---|---|---|
| Versioning | Keeps multiple versions of objects | Enable for data protection |
| Encryption | Secures data at rest | Use SSE-S3 for most cases |
| Public access | Controls bucket accessibility | Block all public access by default |
Implementing bucket policies and access control
Secure your S3 buckets by implementing proper access controls:
- Use IAM policies for user and role-based access
- Apply bucket policies for resource-based permissions
- Utilize Access Control Lists (ACLs) for fine-grained control
Enabling versioning and lifecycle management
Versioning helps protect against accidental deletions and overwrites. To enable:
- Select your bucket in the S3 console
- Go to the “Properties” tab
- Find the “Versioning” section and click “Edit”
- Choose “Enable” and save changes
Implement lifecycle rules to manage object transitions and expirations:
- Transition objects to cheaper storage classes (e.g., S3 Standard-IA)
- Automatically delete old versions or expired objects
- Set up rules based on object tags or prefixes
Optimizing S3 performance and cost
To optimize your S3 usage:
- Choose the appropriate storage class for your data
- Use S3 Transfer Acceleration for faster uploads
- Implement S3 Intelligent-Tiering for automatic cost savings
- Monitor usage with S3 Analytics and adjust accordingly
Now that we’ve covered setting up Amazon S3, let’s move on to deploying Amazon EBS for block-level storage needs.
Deploying Amazon EBS (Elastic Block Store)
Choosing the right EBS volume type
When deploying Amazon EBS, selecting the appropriate volume type is crucial for optimal performance and cost-efficiency. Amazon offers several EBS volume types, each designed for specific use cases:
| Volume Type | Use Case | IOPS | Throughput |
|---|---|---|---|
| General Purpose SSD (gp2/gp3) | Balanced price and performance | Up to 16,000 | Up to 1,000 MiB/s |
| Provisioned IOPS SSD (io1/io2) | High-performance, low-latency | Up to 64,000 | Up to 1,000 MiB/s |
| Throughput Optimized HDD (st1) | Frequently accessed, throughput-intensive workloads | N/A | Up to 500 MiB/s |
| Cold HDD (sc1) | Infrequently accessed data | N/A | Up to 250 MiB/s |
Consider your application’s requirements, such as:
- I/O operations per second (IOPS)
- Throughput
- Cost
- Data access frequency
Attaching EBS volumes to EC2 instances
Once you’ve chosen the appropriate EBS volume type, follow these steps to attach it to an EC2 instance:
- Navigate to the EC2 dashboard in the AWS Management Console
- Select “Volumes” under “Elastic Block Store”
- Click “Create Volume” and specify the volume type, size, and availability zone
- Once created, select the volume and click “Actions” > “Attach Volume”
- Choose the target EC2 instance and specify the device name (e.g., /dev/sdf)
Implementing EBS snapshots for backup
EBS snapshots are crucial for data protection and disaster recovery. To create and manage snapshots:
- Select the volume in the EC2 dashboard
- Click “Actions” > “Create Snapshot”
- Provide a description and add tags if needed
- Set up automated snapshots using Amazon Data Lifecycle Manager for regular backups
Managing EBS encryption
Encryption is essential for data security. To manage EBS encryption:
- Enable encryption by default for new EBS volumes in the account settings
- For existing volumes, create an encrypted snapshot and restore it as a new encrypted volume
- Use AWS Key Management Service (KMS) to manage encryption keys
By following these steps, you’ll effectively deploy and manage Amazon EBS volumes, ensuring optimal performance, data protection, and security for your EC2 instances.
Implementing Amazon EFS (Elastic File System)
Creating and mounting EFS file systems
To create and mount an Amazon EFS file system, follow these steps:
- Create the EFS file system in the AWS Management Console
- Configure network access and security groups
- Mount the file system on your EC2 instances
Here’s a comparison of mounting options:
| Mounting Method | Pros | Cons |
|---|---|---|
| NFS client | Simple, widely supported | Requires manual configuration |
| EFS mount helper | Automatic mounting, handles reconnections | Requires installation |
| AWS DataSync | Efficient data transfer, automated | Additional cost |
Configuring EFS performance modes
EFS offers two performance modes:
- General Purpose: Suitable for most workloads
- Max I/O: Optimized for highly parallel applications
Choose the appropriate mode based on your application’s requirements and expected concurrent access patterns.
Implementing EFS access points
Access points provide application-specific entry points to your EFS file system. To implement:
- Create an access point in the EFS console
- Define the directory path and permissions
- Use the access point ID when mounting the file system
Optimizing EFS for cost and performance
To optimize your EFS implementation:
- Use lifecycle management to move infrequently accessed files to lower-cost storage classes
- Enable EFS Intelligent-Tiering for automatic cost optimization
- Implement proper IAM policies and encryption for enhanced security
- Monitor performance using CloudWatch metrics and adjust as needed
Remember to regularly review your EFS usage and configurations to ensure optimal performance and cost-efficiency. Next, we’ll explore Amazon FSx, another powerful storage solution in the AWS ecosystem.
Leveraging Amazon FSx
Choosing between FSx for Windows File Server and FSx for Lustre
When leveraging Amazon FSx, it’s crucial to choose the right file system for your needs. Let’s compare FSx for Windows File Server and FSx for Lustre:
| Feature | FSx for Windows File Server | FSx for Lustre |
|---|---|---|
| Use Case | Enterprise applications, home directories | High-performance computing, machine learning |
| Protocol | SMB | Lustre |
| Performance | Up to 2 GB/s throughput | Up to 100 GB/s throughput |
| Compatibility | Windows-based applications | Linux-based applications |
| Storage Capacity | Up to 65,536 GB | Up to 3,600 TB |
Choose FSx for Windows File Server for Windows-centric environments or FSx for Lustre for high-performance computing needs.
Deploying and configuring FSx file systems
To deploy an FSx file system:
- Open the Amazon FSx console
- Click “Create file system”
- Choose your file system type
- Configure storage capacity and throughput
- Set up network access and security groups
- Review and create the file system
Implementing data protection and backup strategies
Protect your FSx data with these strategies:
- Enable automatic daily backups
- Set custom backup schedules for critical data
- Use AWS Backup for centralized management
- Implement cross-region replication for disaster recovery
Integrating FSx with other AWS services
FSx integrates seamlessly with various AWS services:
- Use with Amazon EC2 for scalable compute resources
- Pair with Amazon WorkSpaces for virtual desktop infrastructure
- Integrate with AWS Directory Service for user authentication
- Combine with AWS DataSync for efficient data transfer
By leveraging these integrations, you can create powerful, scalable storage solutions tailored to your specific needs.
Utilizing Amazon Glacier for Long-Term Archival
Understanding Glacier storage classes
Amazon Glacier offers three storage classes for long-term data archival, each with unique characteristics:
- Glacier Instant Retrieval
- Glacier Flexible Retrieval
- Glacier Deep Archive
| Storage Class | Retrieval Time | Minimum Storage Duration | Use Case |
|---|---|---|---|
| Instant Retrieval | Milliseconds | 90 days | Frequently accessed archives |
| Flexible Retrieval | Minutes to hours | 90 days | Less frequently accessed data |
| Deep Archive | 12 hours | 180 days | Rarely accessed data |
Implementing Glacier vaults and archives
To set up Glacier for long-term archival:
- Create a Glacier vault
- Configure vault access policies
- Upload archives to the vault
- Generate and store archive metadata
Configuring Glacier retrieval options
Glacier offers various retrieval options to balance cost and speed:
- Expedited: Fastest retrieval (1-5 minutes)
- Standard: Default option (3-5 hours)
- Bulk: Most cost-effective (5-12 hours)
Optimizing Glacier for cost-effective data archiving
To maximize cost savings with Glacier:
- Choose the appropriate storage class based on access patterns
- Implement lifecycle policies to automate data transitions
- Use batch operations for large-scale data management
- Monitor and analyze usage to optimize storage costs
Now that we’ve covered Glacier for long-term archival, let’s explore some best practices for overall AWS storage management.
Best Practices for AWS Storage Management
Implementing data lifecycle policies
Implementing effective data lifecycle policies is crucial for efficient AWS storage management. These policies help automate data movement between storage tiers, reducing costs and improving performance.
| Lifecycle Stage | Storage Class | Use Case |
|---|---|---|
| Hot Data | S3 Standard | Frequent access, low latency |
| Warm Data | S3 Intelligent-Tiering | Unpredictable access patterns |
| Cool Data | S3 Glacier Instant Retrieval | Infrequent access, millisecond retrieval |
| Cold Data | S3 Glacier Flexible Retrieval | Archival, longer retrieval times |
To implement lifecycle policies:
- Define object tagging strategy
- Create lifecycle rules in S3
- Configure transition periods between tiers
- Set up expiration rules for data deletion
Monitoring and optimizing storage performance
Regularly monitoring and optimizing storage performance ensures your AWS storage solutions operate efficiently. Key metrics to track include:
- IOPS (Input/Output Operations Per Second)
- Throughput
- Latency
- Error rates
Use AWS CloudWatch to set up alarms for these metrics and receive notifications when thresholds are exceeded.
Ensuring data security and compliance
Data security is paramount in AWS storage management. Implement these best practices:
- Enable encryption at rest and in transit
- Use AWS Key Management Service (KMS) for key management
- Implement strong IAM policies and roles
- Regularly audit access logs
- Comply with relevant regulations (e.g., GDPR, HIPAA)
Implementing disaster recovery strategies
A robust disaster recovery strategy is essential for protecting your data. Consider the following approaches:
- Cross-region replication for S3 buckets
- Snapshots for EBS volumes
- Multi-AZ deployment for EFS
- Backup and restore plans using AWS Backup
Cost optimization techniques for AWS storage services
To optimize costs while maintaining performance, consider these techniques:
- Use S3 Intelligent-Tiering for unpredictable access patterns
- Implement S3 Lifecycle policies to move data to cheaper storage tiers
- Right-size EBS volumes and use gp3 volumes for better price-performance
- Leverage EFS Infrequent Access storage class for less frequently accessed files
- Use AWS Cost Explorer to identify cost-saving opportunities
By implementing these best practices, you can ensure efficient, secure, and cost-effective AWS storage management.
AWS offers a comprehensive suite of storage solutions to meet diverse business needs. From the versatile Amazon S3 for object storage to the high-performance EBS for block-level storage, and the scalable EFS for file storage, each service caters to specific use cases. Amazon FSx provides fully managed file systems, while Glacier offers cost-effective archival storage. By understanding and implementing these services effectively, organizations can optimize their data management strategies and enhance overall operational efficiency.
To make the most of AWS storage services, remember to align your choices with your specific requirements, implement proper security measures, and regularly review and optimize your storage configurations. By following the best practices outlined in this guide, you’ll be well-equipped to leverage AWS storage solutions to their full potential, ensuring robust, scalable, and cost-effective data management for your applications and workloads.