







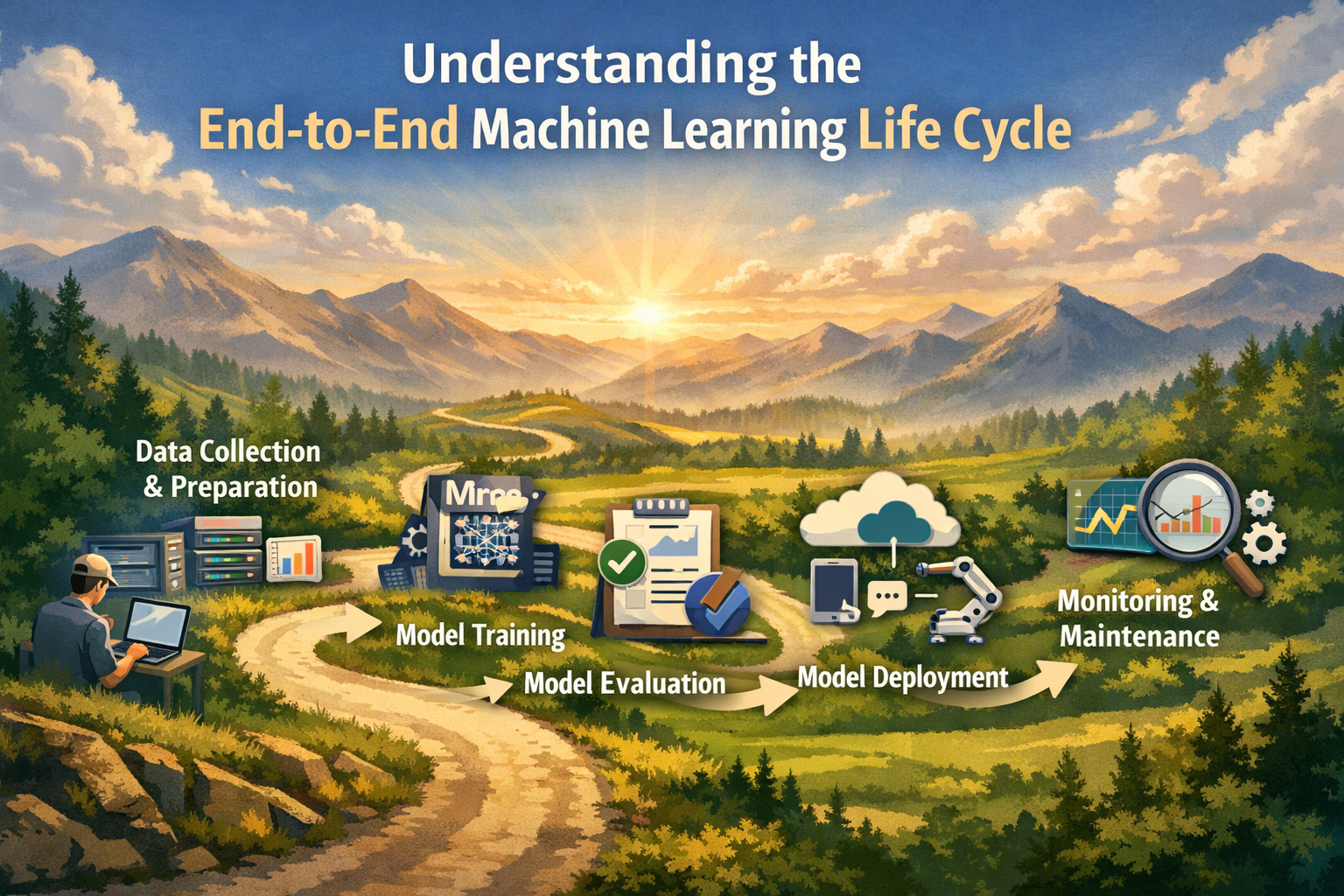
The machine learning lifecycle can feel overwhelming when you’re staring at raw data and wondering how it becomes a working ML model that actually solves business problems. Many data scientists, ML engineers, and product managers jump straight into model training without understanding the complete end-to-end ML pipeline – a mistake that leads to failed projects and models that never see production.
This guide breaks down the machine learning process steps for anyone building production ML systems, from junior data scientists to experienced ML practitioners managing their first ML project management initiative. You’ll learn the essential data science workflow that transforms business challenges into deployed solutions.
We’ll walk through how to properly define business problems and success metrics that align with stakeholder expectations, explore the critical data preparation for machine learning phase that determines model quality, and master ML model deployment strategies that actually work in real-world environments. You’ll also discover proven approaches for model training and validation plus ongoing ML model monitoring techniques that keep your systems running smoothly after launch.
Define Your Business Problem and Success Metrics

Identify the specific business challenge requiring ML solutions
Before jumping into any machine learning project, you need to clearly understand what business problem you’re trying to solve. This isn’t about finding cool ways to use AI—it’s about identifying genuine pain points where machine learning can make a real difference.
Start by asking the right questions: What specific challenges is your organization facing? Are customers churning at high rates? Is manual data processing eating up too much time? Are fraud detection methods missing too many cases? The key is pinpointing problems where patterns in data could provide actionable insights.
Consider whether the problem actually needs machine learning or if simpler solutions might work better. Sometimes a basic rule-based system or improved business processes can solve the issue more efficiently. Machine learning works best when you have:
- Large volumes of data with hidden patterns
- Complex relationships that traditional analysis can’t capture
- Repetitive decision-making processes that could benefit from automation
- Time-sensitive scenarios where quick predictions add value
Document your problem statement clearly. Write it down in plain language that any stakeholder can understand. This becomes your north star throughout the entire machine learning lifecycle.
Establish measurable success criteria and KPIs
Success metrics turn vague goals into concrete targets. Without clear measurements, you’ll never know if your ML project actually delivered value or just created an expensive technical experiment.
Define both technical and business metrics. Technical metrics might include accuracy, precision, recall, or F1-scores, but these mean nothing if they don’t translate to business impact. Your business metrics should directly tie to organizational goals—things like:
- Revenue increase from better recommendations
- Cost reduction through process automation
- Customer satisfaction improvements
- Time savings in manual tasks
- Risk reduction in fraud detection
Set realistic baselines by measuring current performance without machine learning. If your current fraud detection catches 70% of cases, beating that benchmark becomes your minimum success threshold. Establish both minimum viable performance and stretch goals.
Create a measurement timeline. Some benefits appear immediately after deployment, while others take months to materialize. Customer lifetime value improvements, for example, need longer observation periods than click-through rate optimizations.
Assess feasibility and resource requirements
Honest feasibility assessment prevents costly project failures down the road. This means taking a hard look at what you actually have versus what you need to succeed.
Evaluate your data landscape first. Do you have enough relevant data? Is it clean and accessible? Poor data quality kills more ML projects than any other factor. If your data lives in scattered systems with inconsistent formats, factor in significant preparation time.
Assess your team’s capabilities. Machine learning projects need diverse skills—data engineering, modeling expertise, domain knowledge, and deployment capabilities. Identify gaps early and plan for training or hiring.
Consider timeline constraints. Machine learning development isn’t linear. Data preparation often takes 70-80% of project time, not the exciting model building phase. Add buffer time for unexpected data issues, model iterations, and deployment challenges.
Budget for ongoing costs, not just development. Production ML systems need infrastructure, monitoring tools, and maintenance resources. A model that costs $10,000 to build might require $50,000 annually to run and maintain.
Align stakeholders on project objectives
Getting everyone on the same page prevents scope creep and unrealistic expectations that derail projects later. Different stakeholders often have completely different ideas about what success looks like.
Map out your stakeholder ecosystem. Business leaders want revenue impact, technical teams focus on performance metrics, end users care about usability, and legal teams worry about compliance. Each group brings valid concerns that need addressing.
Hold alignment workshops where stakeholders can voice expectations, concerns, and constraints. Use these sessions to identify potential conflicts early. The sales team might want personalization features while the privacy team has data usage restrictions.
Create shared documentation that everyone signs off on. This includes problem definitions, success metrics, timelines, resource commitments, and key assumptions. When project scope inevitably gets questioned later, this document becomes your reference point.
Establish clear communication protocols. Regular check-ins keep stakeholders informed and engaged without overwhelming the technical team with constant requests for updates. Define when and how decisions get made, especially for trade-offs between competing priorities.
Plan for change management. Even successful ML projects often require users to adapt their workflows. Early stakeholder buy-in makes adoption much smoother than trying to convince people after the system is built.
Gather and Explore Your Data Sources
Identify and collect relevant datasets from multiple sources
Data collection forms the foundation of your machine learning lifecycle, and smart teams know that quality trumps quantity every time. Start by mapping out all potential data sources that align with your business problem. Internal databases often hold the most valuable insights—customer transaction records, operational logs, sensor data, and historical performance metrics. These datasets typically offer the richest context because they reflect your specific business environment.
External data sources can significantly enhance your model’s predictive power. Public datasets, industry benchmarks, weather data, economic indicators, and demographic information can provide crucial context your internal data lacks. APIs from social media platforms, financial markets, or government databases offer real-time information streams that keep your models current.
Consider unconventional data sources too. Web scraping can capture competitor pricing, customer sentiment from review sites, or market trends from news articles. Partnership data exchanges with complementary businesses can unlock valuable cross-industry insights without compromising sensitive information.
When collecting data, establish clear data ingestion pipelines early in your data science workflow. Automated collection reduces manual errors and ensures consistency across your end-to-end ML pipeline. Document each source’s refresh frequency, data format, and access requirements. This preparation saves countless hours during later stages of your machine learning process steps.
Perform exploratory data analysis to understand patterns
Exploratory data analysis (EDA) transforms raw datasets into actionable insights that guide your entire ML project management strategy. Start with basic statistical summaries—mean, median, standard deviation, and quartiles—to understand your data’s central tendencies and spread. These fundamental metrics reveal outliers, skewed distributions, and potential data quality issues before they derail your model training efforts.
Visualization tools become your best friend during EDA. Histograms show distribution shapes, box plots highlight outliers, and correlation matrices reveal relationships between variables. Time series plots uncover seasonal patterns or trends that could significantly impact your model’s performance. Scatter plots help identify non-linear relationships that simple correlation coefficients might miss.
Pay special attention to missing data patterns. Random missing values require different treatment than systematic gaps that might indicate business process changes or data collection failures. Understanding these patterns helps you choose appropriate imputation strategies or feature engineering approaches.
Statistical tests can validate your visual observations. Chi-square tests for categorical relationships, t-tests for group comparisons, and ANOVA for multiple group analysis provide quantitative backing for your exploratory findings. These insights directly inform your data preparation for machine learning and model selection decisions.
Evaluate data quality and completeness
Data quality assessment prevents the classic “garbage in, garbage out” scenario that plagues many machine learning projects. Create comprehensive data quality metrics that cover accuracy, completeness, consistency, and timeliness dimensions. Accuracy checks verify that data values fall within expected ranges and follow business rules. Age validation for customer records, geographic coordinate boundaries, and product category consistency are practical examples.
Completeness analysis goes beyond simple null value counts. Examine missing data patterns across different time periods, customer segments, or geographic regions. Sometimes missing data tells a story—seasonal businesses naturally have gaps, and customer behavior changes might create systematic missing patterns that your models should account for.
Consistency checks ensure data harmonization across multiple sources. Date formats, categorical value spellings, and measurement units need standardization before feeding into your machine learning lifecycle. Cross-reference related fields to catch logical inconsistencies—birthdates that imply impossible ages or transaction amounts that exceed account balances.
Timeliness evaluation confirms your data reflects current business conditions. Stale data can mislead models, especially in rapidly changing markets. Establish data freshness thresholds based on your use case requirements and build monitoring systems that alert you when data falls behind schedule.
Document data lineage and governance requirements
Data lineage documentation creates a roadmap that traces every dataset from its origin through all transformations to its final use in your production ML systems. This documentation becomes invaluable when models behave unexpectedly or when stakeholders question your results. Map each data source, transformation step, aggregation rule, and filtering criterion that shapes your final training datasets.
Version control for datasets parallels code versioning in software development. Tag each data snapshot with collection timestamps, processing version numbers, and quality assessment results. This practice enables reproducible model training and helps debug performance issues that emerge after deployment.
Governance requirements vary by industry and geography, but common elements include data retention policies, access control specifications, and audit trail requirements. Healthcare data requires HIPAA compliance tracking, financial data needs SOX documentation, and international projects must address GDPR implications. Build these requirements into your data pipeline architecture rather than retrofitting compliance later.
Create clear data ownership assignments and approval workflows for data usage. Define who can access which datasets, how long data can be retained, and what approval processes govern sharing data across teams or external partners. These governance frameworks protect your organization while enabling productive collaboration.
Assess data privacy and compliance considerations
Privacy assessment should start during data collection rather than becoming an afterthought before deployment. Identify personally identifiable information (PII), sensitive attributes, and protected class variables within your datasets. Even seemingly anonymous data can reveal individual identities when combined with external sources, so comprehensive privacy impact assessments are essential.
Anonymization techniques range from simple identifier removal to sophisticated differential privacy implementations. K-anonymity ensures each record is indistinguishable from at least k-1 other records, while l-diversity adds variability requirements for sensitive attributes. Synthetic data generation can preserve statistical properties while eliminating individual privacy risks entirely.
Regulatory compliance requirements shape every aspect of your machine learning process steps. GDPR’s “right to explanation” demands interpretable models for European customers, while CCPA requires transparent data usage disclosure. Financial services face additional constraints from fair lending regulations that prohibit discriminatory algorithmic decisions.
Build privacy-preserving techniques into your end-to-end ML pipeline architecture. Federated learning enables model training without centralizing sensitive data, homomorphic encryption allows computation on encrypted datasets, and secure multi-party computation enables collaborative analysis without data sharing. These advanced techniques require specialized expertise but offer powerful solutions for privacy-sensitive applications.
Regular compliance audits and privacy impact assessments keep your ML systems aligned with evolving regulations. Establish clear processes for handling data subject requests, monitoring algorithmic bias, and documenting compliance efforts. These proactive measures protect both your organization and the individuals whose data powers your machine learning models.
Prepare and Transform Your Data for Modeling

Clean and handle missing or inconsistent data
Raw data rarely comes in perfect condition. You’ll encounter missing values, duplicate records, outliers, and formatting inconsistencies that can derail your machine learning pipeline if left unaddressed. Start by conducting a thorough audit of your dataset to identify patterns in missing data – are they random, or do they follow specific trends that might introduce bias?
For handling missing values, you have several strategies at your disposal:
- Remove rows or columns with excessive missing data (typically >30% missing)
- Impute values using statistical methods like mean, median, or mode for numerical data
- Forward-fill or backward-fill for time series data
- Use advanced imputation techniques like KNN or regression-based methods
Duplicate records need immediate attention since they can artificially inflate model performance during training. Use unique identifiers or combination of key fields to detect and remove duplicates. For outliers, apply statistical methods like the IQR rule or Z-score to identify extreme values, then decide whether to remove, cap, or transform them based on domain knowledge.
Data validation rules should check for logical consistency – dates in proper ranges, categorical values matching expected categories, and numerical values within reasonable bounds. Document all cleaning decisions to ensure reproducibility in your data science workflow.
Engineer meaningful features from raw data
Feature engineering transforms raw data into meaningful inputs that help machine learning models understand patterns more effectively. This creative process often determines the success of your ML project more than the algorithm choice itself.
Start with domain knowledge to create features that make business sense. For time-based data, extract components like day of week, month, hour, or create lag features. For text data, consider TF-IDF scores, sentiment analysis, or n-grams. Numerical features can be combined through ratios, differences, or polynomial combinations.
Common feature engineering techniques include:
- Binning continuous variables into categorical groups
- Creating interaction terms between existing features
- Aggregating data across different time windows or groups
- Encoding categorical variables using one-hot, label, or target encoding
- Extracting features from text using NLP techniques
Always validate new features by checking their correlation with the target variable and ensuring they don’t introduce data leakage. Features that use future information to predict past events will give misleadingly good results during training but fail in production.
Split data into training, validation, and test sets
Proper data splitting prevents overfitting and gives you realistic estimates of model performance. The standard approach uses three distinct sets: training (60-70%), validation (15-20%), and test (15-20%) sets, though these proportions can vary based on dataset size.
For time series data, use temporal splits where training data comes before validation and test data chronologically. This mimics real-world scenarios where you predict future events based on past observations. Random splitting would create data leakage by allowing the model to learn from future information.
When dealing with imbalanced datasets, use stratified sampling to maintain the same class distribution across all splits. This ensures each set represents the overall population properly. For grouped data (like multiple records per customer), split at the group level to prevent data leakage.
Consider creating multiple validation folds for cross-validation, especially with smaller datasets. This approach provides more robust performance estimates and helps identify models that perform consistently across different data subsets.
Apply scaling and normalization techniques
Machine learning algorithms often struggle with features at different scales. Distance-based algorithms like KNN and SVM are particularly sensitive to feature magnitudes, while neural networks benefit from normalized inputs for faster convergence.
Choose scaling methods based on your data distribution:
- StandardScaler (z-score normalization) works well for normally distributed data
- MinMaxScaler scales features to a fixed range (0-1) and preserves relationships
- RobustScaler uses median and IQR, making it less sensitive to outliers
- Quantile transformers map features to uniform or normal distributions
Apply scaling after data splitting to prevent data leakage. Fit the scaler only on training data, then transform all sets using those parameters. This simulates real-world conditions where you won’t have access to future data statistics.
Some algorithms like tree-based models (Random Forest, XGBoost) are scale-invariant and don’t require preprocessing. However, if you plan to ensemble different algorithm types, consistent scaling across features becomes essential for your end-to-end ML pipeline success.
Select and Train Your Machine Learning Models

Choose appropriate algorithms based on problem type
Your problem type drives everything when selecting machine learning algorithms. For supervised learning tasks like predicting house prices or customer churn, you’ll want regression or classification algorithms respectively. Linear regression works beautifully for continuous outcomes with linear relationships, while decision trees handle non-linear patterns and categorical features naturally.
Classification problems offer rich algorithm choices. Logistic regression provides interpretable results perfect for business stakeholders who need to understand decision factors. Random forests excel with mixed data types and automatically handle feature interactions. Support vector machines shine with high-dimensional data, while neural networks capture complex patterns in large datasets.
Unsupervised learning scenarios require different approaches. K-means clustering groups similar data points effectively, while hierarchical clustering reveals data structure at multiple levels. Principal component analysis reduces dimensionality while preserving important information.
Consider your data characteristics too. Small datasets favor simpler algorithms like naive Bayes or k-nearest neighbors that don’t require extensive training. Large datasets can support complex models like gradient boosting or deep learning networks. Text data works well with algorithms designed for sparse, high-dimensional features.
Implement baseline models for performance comparison
Baseline models establish performance benchmarks that guide your machine learning process throughout the project lifecycle. Start with the simplest possible approach – for classification, this might mean predicting the most common class, while regression baselines often use mean or median predictions.
Domain-specific baselines provide more meaningful comparisons. In customer segmentation, random assignment creates a realistic lower bound. For time series forecasting, naive methods like using the previous period’s value or simple moving averages work well. These simple approaches often surprise people with their effectiveness.
Implement multiple baseline levels. Level one uses business rules or heuristics that currently solve the problem. Level two applies simple statistical methods like linear regression or decision trees with default parameters. Level three introduces slightly more sophisticated approaches with minimal tuning.
Document baseline performance across all relevant metrics. Accuracy alone doesn’t tell the full story – track precision, recall, F1-score, and business-specific metrics. This comprehensive view helps you understand whether complex models justify their additional overhead.
Keep baselines running throughout model development. They serve as reality checks when fancy algorithms produce unexpected results and help identify when you’re overfitting to validation data.
Tune hyperparameters for optimal performance
Hyperparameter tuning transforms good models into great ones, but it requires systematic approaches rather than random experimentation. Grid search explores all combinations of specified parameter values, making it thorough but computationally expensive. Random search often finds better solutions faster by sampling from parameter distributions.
Bayesian optimization represents the smart approach to hyperparameter tuning. It builds a probabilistic model of the objective function and uses this knowledge to suggest promising parameter combinations. Tools like Optuna or Hyperopt implement these sophisticated strategies with minimal code changes.
Start with the most impactful parameters. For random forests, focus on the number of trees, maximum depth, and minimum samples per leaf. Neural networks benefit from learning rate, batch size, and architecture choices. Don’t tune everything simultaneously – begin with 2-3 key parameters before expanding your search.
Use nested cross-validation to get unbiased performance estimates. The outer loop provides honest performance evaluation while the inner loop handles hyperparameter selection. This prevents the common mistake of overfitting to your validation set during the tuning process.
Set reasonable parameter ranges based on dataset size and computational constraints. Extremely deep trees might overfit small datasets, while too few trees won’t capture complex patterns. Time-box your tuning efforts and track performance improvements to identify diminishing returns.
Apply cross-validation techniques to prevent overfitting
Cross-validation provides robust model evaluation that goes beyond simple train-test splits. K-fold cross-validation divides your data into k equal parts, training on k-1 folds and testing on the remaining fold. This process repeats k times, giving you k performance estimates that reveal model stability.
Stratified cross-validation maintains class distributions across folds, preventing situations where one fold lacks certain classes entirely. This becomes critical with imbalanced datasets where random splits might create training sets missing minority classes.
Time series data requires special handling through temporal cross-validation. Forward chaining respects time dependencies by training on historical data and testing on future periods. This mimics real-world deployment conditions where models predict future events based on past observations.
Leave-one-out cross-validation uses each data point as a separate test set, providing maximum training data for each model. While computationally expensive, it works well with small datasets where every data point matters.
Monitor cross-validation results for concerning patterns. High variance across folds suggests overfitting or data quality issues. Consistently poor performance across all folds indicates underfitting or fundamental model-data mismatches. Use these insights to adjust your modeling approach before investing time in complex solutions.
Combine cross-validation with hyperparameter tuning carefully to avoid data leakage. The validation set used for hyperparameter selection should remain separate from the cross-validation folds used for final model evaluation.
Evaluate and Validate Model Performance
Test models on unseen data using relevant metrics
Your machine learning model might perform brilliantly on training data, but the real test comes when it faces completely new information. This validation phase separates good models from great ones in the machine learning lifecycle. Start by setting aside a holdout test set that your model has never seen during training or hyperparameter tuning – typically 15-20% of your original dataset.
Choose metrics that align with your business objectives and problem type. For classification tasks, accuracy might seem obvious, but precision, recall, and F1-score often tell a more complete story. Regression problems benefit from metrics like Mean Absolute Error (MAE), Root Mean Square Error (RMSE), and R-squared values. Don’t rely on a single metric – create a comprehensive scorecard that captures different aspects of model performance.
Cross-validation techniques add another layer of confidence to your evaluation. K-fold cross-validation splits your data into multiple segments, training and testing the model repeatedly to give you a more robust performance estimate. Time series data requires special attention with techniques like walk-forward validation to respect temporal dependencies.
Conduct bias and fairness assessments
Machine learning models can inadvertently perpetuate or amplify existing biases in your data, leading to unfair outcomes for certain groups. This step has become critical in the data science workflow as organizations face increasing scrutiny around algorithmic fairness.
Start by examining your model’s performance across different demographic groups, geographic regions, or other relevant segments. Look for disparate impact where certain groups experience significantly different outcomes. Statistical parity, equalized odds, and demographic parity are common fairness metrics that help quantify these differences.
Bias can creep in through historical data, sampling methods, or feature selection. Protected attributes like race, gender, or age might not be directly used in your model, but proxy variables could still introduce bias. Techniques like adversarial debiasing, fairness-aware machine learning algorithms, and post-processing adjustments can help mitigate these issues.
Document your findings thoroughly. Stakeholders need clear explanations of potential biases and the steps taken to address them. This documentation becomes valuable for compliance, audits, and future model iterations.
Perform error analysis and identify improvement opportunities
Error analysis transforms raw performance metrics into actionable insights for your end-to-end ML pipeline. Start by examining where your model fails most frequently. Create confusion matrices for classification problems or residual plots for regression tasks to visualize error patterns.
Slice your errors by different dimensions – data sources, time periods, feature ranges, or business segments. You might discover that your model struggles with specific customer types, particular product categories, or certain seasonal patterns. These insights guide targeted improvements in data collection, feature engineering, or model architecture.
Misclassification analysis reveals common failure modes. Perhaps your image classifier consistently confuses certain breeds of dogs, or your fraud detection system flags legitimate transactions from specific regions. Understanding these patterns helps you decide whether to collect more training data, engineer better features, or adjust your modeling approach.
Error severity matters too. Some mistakes cost more than others from a business perspective. Weight your error analysis by impact – a false negative in medical diagnosis carries different consequences than in email spam detection. This business-oriented view of errors helps prioritize improvement efforts.
Compare multiple model approaches and select the best performer
Smart practitioners in production ML systems never put all their eggs in one algorithmic basket. Train multiple models using different approaches – linear models, tree-based methods, neural networks, and ensemble techniques. Each algorithm brings unique strengths and weaknesses to your specific problem.
Create a standardized comparison framework that evaluates all models using the same test data and metrics. Consider computational requirements alongside performance metrics. A model that’s 2% more accurate but takes 10x longer to train or predict might not be worth the trade-off in production environments.
Ensemble methods often outperform individual models by combining their strengths. Voting classifiers, stacking, and boosting techniques can squeeze extra performance from your model training and validation process. However, balance complexity against interpretability requirements – some business contexts demand explainable models over black-box solutions.
Don’t forget practical considerations like model size, inference speed, and memory requirements. The “best” model on paper might not be feasible for your deployment constraints. Consider creating a shortlist of top performers and evaluate them against your specific production requirements before making the final selection.
Deploy Your Model to Production Environment

Package models for scalable deployment infrastructure
Packaging your ML model deployment correctly sets the foundation for a reliable production ML system. Start by containerizing your models using Docker, which ensures consistency across different environments and simplifies the deployment process. Your container should include the trained model artifacts, all necessary dependencies, preprocessing code, and prediction logic in a single, portable package.
Consider using model serving frameworks like TensorFlow Serving, MLflow, or Seldon Core that provide standardized APIs and built-in scaling capabilities. These platforms handle common deployment challenges like model versioning, A/B testing, and automatic scaling based on traffic patterns.
Create deployment configurations that specify resource requirements, environment variables, and scaling policies. Use infrastructure-as-code tools like Terraform or AWS CloudFormation to maintain consistent deployment environments across development, staging, and production.
Implement real-time or batch prediction pipelines
Choose between real-time and batch prediction pipelines based on your business requirements and latency needs. Real-time pipelines serve predictions instantly through REST APIs or streaming platforms, perfect for applications requiring immediate responses like fraud detection or recommendation systems.
For real-time deployment, implement load balancers and auto-scaling groups to handle varying traffic loads. Use caching strategies to reduce prediction latency for frequently requested inputs. Consider implementing circuit breakers and timeout mechanisms to prevent cascading failures.
Batch prediction pipelines process large volumes of data at scheduled intervals, ideal for scenarios like daily customer segmentation or weekly demand forecasting. Design these pipelines using workflow orchestration tools like Apache Airflow or AWS Step Functions. Implement data partitioning and parallel processing to handle large datasets efficiently.
Build robust error handling mechanisms for both pipeline types. Include retry logic for transient failures and dead letter queues for problematic requests that require manual intervention.
Set up monitoring and logging systems
Comprehensive monitoring transforms your ML model deployment from a black box into a transparent, observable system. Track key performance metrics including prediction latency, throughput, error rates, and resource utilization. Monitor model-specific metrics like prediction confidence scores and feature drift to detect when model performance degrades.
Implement structured logging that captures request details, prediction outputs, and execution times. Use correlation IDs to trace requests through your entire ML pipeline, making debugging much easier when issues arise. Store logs in centralized systems like Elasticsearch or cloud-native solutions for easy searching and analysis.
Set up alerting rules for critical thresholds like high error rates, unusual prediction distributions, or infrastructure failures. Configure different alert severities to avoid alarm fatigue while ensuring urgent issues get immediate attention.
Create dashboards that visualize model performance trends, system health, and business metrics. These visual tools help stakeholders understand how your ML system impacts business outcomes and identify optimization opportunities.
Establish rollback procedures for production issues
Production ML systems need bulletproof rollback procedures because model failures can directly impact business operations and customer experience. Design your deployment architecture to support blue-green deployments, where you maintain two identical production environments and can instantly switch between them.
Implement canary releases that gradually route traffic to new model versions while monitoring performance metrics. Start with a small percentage of traffic and increase gradually based on predefined success criteria. This approach catches issues before they affect your entire user base.
Create automated rollback triggers based on key performance indicators like prediction accuracy drops, increased error rates, or significant changes in prediction distributions. Your system should automatically revert to the previous stable model version when these thresholds are exceeded.
Document clear escalation procedures that define who gets notified during different types of incidents and their specific responsibilities. Include step-by-step rollback instructions that team members can follow under pressure. Practice these procedures regularly through chaos engineering exercises to ensure they work when needed.
Maintain model version history with the ability to quickly redeploy any previous version. Store not just the model artifacts but also the exact code, dependencies, and configuration used for each deployment to ensure reproducible rollbacks.
Monitor and Maintain Your ML System

Track model performance degradation over time
Your production ML systems won’t maintain their accuracy forever. Real-world data changes, user behavior shifts, and business environments evolve—all of which can slowly erode your model’s performance. Setting up proper monitoring means keeping tabs on key metrics like precision, recall, and accuracy against live data streams.
Create dashboards that show performance trends over weeks and months, not just daily snapshots. Watch for gradual declines that might signal deeper issues. Most teams set up automated alerts when performance drops below predetermined thresholds, giving you time to investigate before customers notice problems.
Track both statistical metrics and business KPIs. A model might technically perform well but fail to deliver expected business value due to changing market conditions or user preferences.
Implement automated retraining workflows
Manual model updates don’t scale in production ML systems. Automated retraining pipelines keep your models fresh without constant human intervention. These workflows should trigger based on performance degradation, data volume thresholds, or scheduled intervals.
Build pipelines that can:
- Pull fresh training data automatically
- Validate data quality before training begins
- Train multiple model candidates in parallel
- Run comprehensive testing against holdout datasets
- Deploy winning models only after passing all checks
Consider A/B testing frameworks that gradually roll out retrained models to subsets of users. This approach lets you validate improvements in real-world conditions before full deployment.
Monitor data drift and distribution changes
Data drift happens when incoming data differs from your original training set. This shift can break model assumptions and hurt performance, even if your code runs perfectly. Production ML systems need continuous monitoring to catch these changes early.
Statistical tests can detect distribution shifts in numerical features, while categorical features need different approaches. Many teams use techniques like:
- Kolmogorov-Smirnov tests for numerical data
- Chi-square tests for categorical variables
- Population Stability Index (PSI) calculations
- Feature importance tracking over time
Set up alerts for significant drift events and create processes to investigate root causes. Sometimes drift indicates real-world changes you need to adapt to, while other times it signals data collection problems.
Update models based on new data and business requirements
Business needs change faster than most ML model lifecycles. Your production systems should accommodate evolving requirements without major architectural overhauls. This means building flexibility into your ML model monitoring and deployment processes.
Maintain version control for both models and their associated business logic. When requirements shift, you can quickly compare how different model versions perform against new success criteria. Document decision-making processes so future team members understand why certain choices were made.
Regular model audits help ensure your ML systems stay aligned with business goals. Schedule quarterly reviews to assess whether current models still serve their intended purpose and identify opportunities for improvement based on new data sources or advanced techniques.

Machine learning projects succeed when you follow a structured approach from start to finish. Each stage of the ML lifecycle builds on the previous one, creating a solid foundation for your project. Starting with a clear business problem and well-defined success metrics gives your entire project direction. The data gathering, preparation, and modeling phases require patience and attention to detail, but they set you up for better results down the line.
The real work doesn’t stop once your model goes live. Monitoring and maintaining your ML system is just as important as building it in the first place. Models can drift over time, data patterns change, and business needs evolve. Start your next machine learning project by mapping out each stage of this lifecycle. Having a clear roadmap will save you time, reduce headaches, and increase your chances of delivering real business value.









