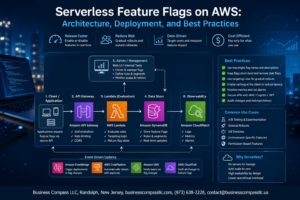
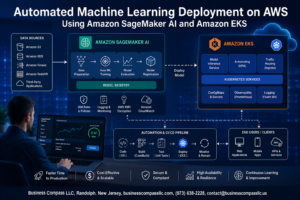
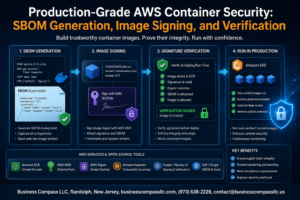
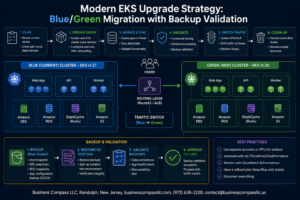
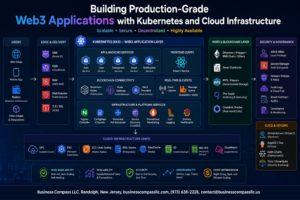
Building an Apache Kafka production cluster on EC2 requires careful planning and the right configuration choices to handle real-world data streaming workloads. This guide walks DevOps engineers, platform architects, and data engineers through creating a robust Kafka cluster design AWS infrastructure that can scale with your business needs.
Getting your production ready Kafka setup right from the start saves you from costly redesigns and performance headaches down the road. Many teams rush into Kafka deployments without proper planning, only to discover their cluster can’t handle peak traffic or lacks the reliability their applications demand.
We’ll cover three critical areas: planning your EC2 Kafka infrastructure to match your throughput and storage requirements, implementing high availability configuration with proper replication and fault tolerance, and establishing monitoring strategies to track cluster health and optimize performance before issues impact your users.
By the end, you’ll have a production-grade Kafka deployment that’s secure, scalable, and ready to power your data streaming applications.
Planning Your Kafka Infrastructure Requirements
Determining Message Throughput and Storage Needs
Start by analyzing your expected message volume and payload size to calculate daily throughput requirements. Production Kafka clusters typically handle thousands to millions of messages per second, so measure peak traffic patterns and plan for 2-3x growth capacity. Storage needs depend on retention policies – streaming applications might need hours of data while analytics workloads require weeks. Calculate total storage by multiplying average message size by throughput and retention period, then add 20% buffer for operational overhead.
Calculating Partition and Replica Distribution
Design partition counts based on consumer parallelism and target throughput per partition (typically 10-20 MB/sec). More partitions enable better parallelism but increase overhead – aim for 100-1000 partitions per broker maximum. Set replication factor to 3 for production workloads to ensure data durability and availability during broker failures. Distribute partition leaders evenly across brokers to avoid hotspots and ensure balanced load distribution throughout your Apache Kafka production cluster.
Selecting Optimal EC2 Instance Types for Brokers
Choose compute-optimized instances like c5.2xlarge or c5.4xlarge for CPU-intensive workloads with high message rates. For storage-heavy scenarios with longer retention, select storage-optimized instances like d3.2xlarge with local NVMe SSDs. Memory requirements typically need 6-8GB heap space plus OS overhead – avoid exceeding 32GB heap to prevent garbage collection issues. Network performance becomes critical at scale, so select instances with enhanced networking and sufficient bandwidth for your throughput requirements in your Kafka EC2 setup.
Estimating Network Bandwidth Requirements
Calculate network bandwidth by considering producer traffic, consumer traffic, and replication overhead between brokers. Replication typically doubles your inbound traffic, while multiple consumer groups multiply outbound bandwidth. Include inter-broker communication for partition reassignment and leader election processes. Plan for sustained bandwidth rather than burst capacity – a cluster handling 100MB/sec might need 300-400MB/sec network capacity accounting for replication and consumer groups. Monitor network utilization closely as it often becomes the bottleneck in scalable Kafka deployment scenarios.
Setting Up EC2 Infrastructure for Maximum Performance
Configuring Virtual Private Cloud with Proper Subnets
Creating a robust VPC architecture forms the backbone of your Kafka EC2 setup. Design your VPC with at least three availability zones to ensure maximum fault tolerance for your Apache Kafka production cluster. Place Kafka brokers in private subnets across different AZs, while positioning ZooKeeper nodes in separate subnets for isolation. Configure public subnets for NAT gateways and bastion hosts, enabling secure external access without exposing your Kafka infrastructure directly to the internet. Use CIDR blocks that provide sufficient IP address space for future scaling – typically /16 for the VPC and /24 for individual subnets works well for most production Kafka deployments.
Implementing Security Groups for Cluster Communication
Security groups act as virtual firewalls that control traffic flow between Kafka cluster components. Create dedicated security groups for different roles: one for Kafka brokers allowing port 9092-9094 for client connections and inter-broker communication, another for ZooKeeper permitting ports 2181, 2888, and 3888. Your producer and consumer applications need specific ingress rules targeting only the Kafka broker security group. Avoid using 0.0.0.0/0 source ranges; instead reference security group IDs for internal communication. This approach creates a secure, scalable Kafka deployment where components can communicate freely while blocking unauthorized access from external sources.
Optimizing EBS Storage for Low Latency Operations
Storage performance directly impacts Kafka throughput and latency in your production environment. Choose gp3 volumes for most Kafka workloads, providing up to 16,000 IOPS and 1,000 MiB/s throughput per volume. For high-throughput scenarios, consider io2 Block Express volumes delivering up to 256,000 IOPS. Mount separate EBS volumes for Kafka logs and ZooKeeper data directories to prevent I/O contention. Configure XFS filesystem with noatime mount option to reduce unnecessary disk writes. Size your volumes based on retention policies – plan for 3x your expected data size to accommodate replication and log compaction. Enable EBS optimization on your EC2 instances to guarantee dedicated bandwidth between compute and storage layers.
Installing and Configuring Kafka for Production Workloads
Deploying Java Runtime Environment Across All Nodes
Start by installing OpenJDK 11 or 17 on each EC2 instance, as these versions provide the best stability for production Kafka deployments. Configure the JAVA_HOME environment variable consistently across all nodes and verify the installation with java -version. Download the same Java distribution for all brokers to prevent compatibility issues. Set up proper PATH variables and ensure Java security policies allow Kafka’s network operations.
Installing Apache Kafka with Production-Ready Settings
Download Apache Kafka from the official website and extract it to /opt/kafka on each broker node for standardized deployment. Create a dedicated kafka user with appropriate permissions and ownership of the Kafka directory structure. Configure the server.properties file with unique broker IDs for each node and set appropriate log directories on high-performance storage volumes. Enable auto-creation of topics only if required by your specific use case.
Configuring Broker Properties for High Availability
Set num.network.threads to 8-16 and num.io.threads to 8-24 based on your EC2 instance CPU cores for optimal network and disk I/O performance. Configure default.replication.factor=3 and min.insync.replicas=2 to ensure data durability across multiple availability zones. Set unclean.leader.election.enable=false to prevent data loss during leader elections. Configure log.retention.hours and log.segment.bytes based on your data retention requirements and available storage capacity.
Setting Up JVM Heap Memory for Optimal Performance
Allocate 6-8GB heap memory for production Kafka brokers on instances with 16GB+ RAM, leaving sufficient memory for OS page cache operations. Configure -Xms and -Xmx to identical values to prevent heap expansion overhead during runtime operations. Set -XX:+UseG1GC for garbage collection and -XX:MaxGCPauseMillis=20 to minimize latency impact on message processing. Add -XX:+HeapDumpOnOutOfMemoryError and -XX:HeapDumpPath=/var/log/kafka for debugging memory issues in production environments.
Implementing High Availability and Fault Tolerance
Establishing Multi-AZ Deployment Strategy
Distributing your Kafka cluster across multiple Availability Zones creates a resilient foundation that survives data center failures. Place brokers evenly across at least three AZs to ensure your Apache Kafka production cluster maintains operations when one zone goes offline. Configure your broker placement strategy to spread partitions across zones, keeping replica sets distributed. Your EC2 Kafka infrastructure should include cross-AZ networking with sufficient bandwidth between zones to handle replication traffic without performance degradation.
Configuring Automatic Leader Election Mechanisms
Kafka’s built-in controller manages partition leadership elections automatically when brokers fail. Set unclean.leader.election.enable=false to prevent data loss during leadership changes, even if it means temporary unavailability. Configure min.insync.replicas to at least 2 for critical topics, ensuring writes require acknowledgment from multiple replicas before committing. Monitor controller election metrics closely since frequent controller changes indicate network or resource issues that need immediate attention for maintaining Kafka high availability configuration.
Setting Up Cross-Rack Awareness for Data Distribution
Enable rack awareness by setting the broker.rack property to identify each broker’s physical location or availability zone. This configuration ensures Kafka distributes partition replicas across different racks or zones, preventing simultaneous data loss from infrastructure failures. Your scalable Kafka deployment should leverage this feature to optimize replica placement automatically. Configure your brokers with meaningful rack identifiers that reflect your actual infrastructure topology, allowing Kafka’s intelligent placement algorithms to work effectively.
Implementing Backup and Disaster Recovery Procedures
Create automated snapshots of your Kafka data directories and ZooKeeper state using EBS snapshots scheduled during low-traffic periods. Implement cross-region replication using MirrorMaker 2.0 for critical topics that require geographic redundancy. Test your recovery procedures regularly by spinning up clusters from backups in isolated environments. Document your recovery time objectives and ensure your team knows the exact steps for restoring service, including broker configuration restoration and consumer group offset recovery procedures.
Monitoring and Performance Optimization Strategies
Installing JMX Metrics Collection Tools
Deploy Prometheus with JMX Exporter to capture comprehensive Apache Kafka performance tuning metrics from your production cluster. Install the JMX Exporter JAR on each Kafka broker by adding -javaagent:/path/to/jmx_prometheus_javaagent.jar=7071:/path/to/kafka-2_0_0.yml to your Kafka startup script. Configure the YAML file to expose essential JMX beans including kafka.server:type=BrokerTopicMetrics, kafka.network:type=RequestMetrics, and kafka.controller:type=KafkaController. Set up Grafana dashboards to visualize broker CPU usage, disk I/O patterns, network throughput, and partition leadership distribution across your EC2 Kafka infrastructure.
Setting Up Alerts for Critical Performance Indicators
Create alerting rules in Prometheus AlertManager for critical thresholds that impact your production ready Kafka cluster stability. Monitor under-replicated partitions with alerts triggering when the count exceeds zero for more than five minutes. Set up CPU utilization alerts at 80% threshold and memory usage warnings at 85% to prevent broker performance degradation. Configure disk space monitoring with alerts at 85% capacity to avoid log retention issues. Track consumer lag metrics and alert when lag exceeds your defined SLA thresholds. Monitor network request queue size and connection counts to detect potential bottlenecks before they impact message throughput on your scalable Kafka deployment.
Implementing Log Aggregation for Troubleshooting
Configure centralized logging using ELK stack (Elasticsearch, Logstash, Kibana) to aggregate Kafka server logs, controller logs, and state-change logs from all EC2 instances. Install Filebeat on each Kafka broker to ship logs to your Logstash pipeline for parsing and enrichment. Create custom log parsing rules to extract relevant fields like broker ID, partition information, and error codes. Set up log retention policies matching your compliance requirements while balancing storage costs. Build Kibana dashboards showing error patterns, rebalancing events, and leader election activities. Configure log-based alerts for ERROR and FATAL level messages to enable proactive troubleshooting of your Apache Kafka production cluster infrastructure.
Security Hardening and Access Control Implementation
Enabling SSL Encryption for Client-Broker Communication
Configure SSL certificates for your Kafka EC2 instances by generating keystores and truststores for each broker. Update server.properties with SSL listener configurations, setting security.inter.broker.protocol to SSL and listeners to include SSL ports. Enable client SSL authentication by distributing client certificates and configuring ssl.client.auth=required for production-ready Kafka security hardening.
Implementing SASL Authentication Mechanisms
Set up SASL/PLAIN or SASL/SCRAM authentication by creating a JAAS configuration file on each broker. Configure sasl.enabled.mechanisms and security.protocol in server.properties, then create user credentials using kafka-configs.sh scripts. SASL/SCRAM provides stronger security than PLAIN by storing hashed passwords in ZooKeeper, making your Apache Kafka production cluster more resilient against credential attacks.
Configuring Access Control Lists for Topic Permissions
Enable Kafka’s built-in authorizer by setting authorizer.class.name to kafka.security.authorizer.AclAuthorizer in broker configurations. Create granular ACLs using kafka-acls.sh to control user access to specific topics, consumer groups, and cluster operations. Define read, write, and admin permissions per user or service account, ensuring your Kafka security best practices align with organizational requirements and compliance standards.
Setting Up Network-Level Security Policies
Implement AWS Security Groups to restrict inbound traffic to Kafka ports (9092, 9093) from authorized IP ranges only. Configure VPC network ACLs for additional layer protection and enable VPC Flow Logs for traffic monitoring. Use private subnets for broker placement and bastion hosts for administrative access, creating a secure network perimeter around your EC2 Kafka infrastructure deployment.
Building a rock-solid Kafka cluster on EC2 takes careful planning and attention to detail. From sizing your infrastructure properly to implementing robust security measures, each step plays a crucial role in creating a system that can handle real-world production demands. The key is getting the basics right – proper instance sizing, strategic placement across availability zones, and thorough configuration tuning.
Don’t skip the monitoring and security steps, even if you’re eager to get your cluster running. These aren’t just nice-to-have features; they’re essential for maintaining a stable, secure system that won’t keep you up at night. Start with a solid foundation, test everything thoroughly, and remember that a well-designed Kafka cluster is an investment that will pay dividends as your data needs grow.