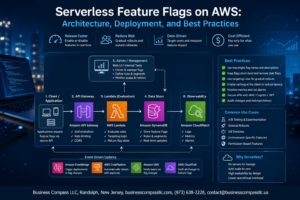
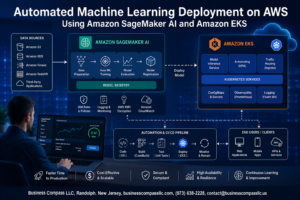
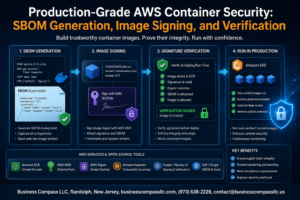
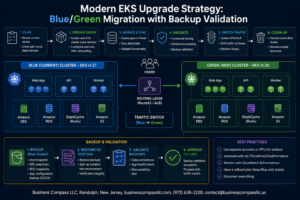
Most organizations connect their on-premises infrastructure to AWS and call it a hybrid cloud. But true hybrid AWS architecture performance goes far beyond establishing basic connectivity—it requires deliberate design choices that prioritize speed, efficiency, and seamless workload execution.
This guide is for cloud architects, DevOps engineers, and infrastructure teams who need to squeeze every ounce of performance from their hybrid environments. You already have the connections in place, but you’re hitting bottlenecks, experiencing unexpected latency, or struggling to get your distributed workloads running as fast as they should.
We’ll walk through strategic network design principles that maximize throughput while minimizing latency, including placement decisions that can make or break your performance goals. You’ll learn data flow optimization techniques that reduce unnecessary network hops and keep your hybrid workloads running smoothly. We’ll also cover compute resource orchestration strategies that help you place the right workloads in the right locations for optimal speed and efficiency.
Understanding Performance-Centric Hybrid Architecture Beyond Basic Connectivity
Identifying Performance Bottlenecks in Traditional Hybrid Setups
Traditional hybrid AWS architecture performance suffers from several predictable bottlenecks that go beyond simple connectivity issues. Most organizations focus heavily on establishing basic network links between on-premises infrastructure and AWS, missing critical performance optimization opportunities. Common bottlenecks include inadequate bandwidth allocation for peak workloads, improper load balancing configurations, and suboptimal data transfer protocols. Legacy applications often struggle with increased latency when communicating across hybrid boundaries, while poorly configured security groups and NACLs create unnecessary processing overhead. Storage performance typically degrades when applications attempt to access on-premises databases from cloud compute instances, creating I/O wait times that cascade through entire application stacks.
Measuring True Application Performance vs Network Connectivity
AWS hybrid cloud optimization requires distinguishing between raw network metrics and actual application performance indicators. While network connectivity tests might show acceptable ping times and bandwidth availability, real-world application performance depends on factors like database query response times, API call latency, and user transaction completion rates. End-to-end application monitoring reveals how network design low latency AWS configurations impact business-critical processes. Response time measurements should include database connection pooling efficiency, cache hit ratios across hybrid boundaries, and transaction rollback frequencies. Application-level metrics provide deeper insights than simple network throughput tests, exposing performance gaps that traditional monitoring tools often miss completely.
Defining Performance Success Metrics for Hybrid Environments
Establishing meaningful performance benchmarks for hybrid workload data flow optimization starts with business-aligned metrics rather than purely technical measurements. Key performance indicators should include application response times under various load conditions, data synchronization speeds between on-premises and AWS resources, and user experience metrics like page load times and transaction success rates. Resource utilization efficiency across both environments helps identify optimization opportunities, while cost-per-transaction metrics ensure performance improvements align with budget constraints. Availability and recovery time objectives must account for cross-environment dependencies, creating comprehensive performance monitoring hybrid cloud strategies that support continuous optimization hybrid architecture goals through data-driven decision making processes.
Strategic Network Design for Maximum Throughput and Low Latency
Optimizing Direct Connect Configurations for Performance Gains
AWS Direct Connect delivers raw performance potential, but configuration details make the difference between adequate connectivity and exceptional throughput. Choose dedicated connections over hosted options when bandwidth demands exceed 1 Gbps consistently. Bundle multiple Direct Connect links using LAG (Link Aggregation Groups) to create high-bandwidth pathways that automatically distribute traffic across available circuits. Configure BGP route priorities carefully to ensure traffic flows through your fastest connections first. Set up separate Virtual Interfaces (VIFs) for different traffic types – isolate production workloads from backup traffic to prevent bandwidth contention. Enable jumbo frames (9000 MTU) across your entire network path to reduce packet overhead and boost throughput for large data transfers.
Implementing Multi-Path Networking for Enhanced Bandwidth
Multi-path networking transforms single connection bottlenecks into high-capacity data highways. Deploy ECMP (Equal-Cost Multi-Path) routing to automatically spread traffic across multiple Direct Connect circuits or VPN tunnels. Create diverse network paths using different Internet Service Providers and AWS availability zones to maximize available bandwidth. Configure dynamic routing protocols like BGP to automatically adjust traffic distribution based on real-time path performance. Use AWS Transit Gateway to orchestrate complex multi-path scenarios across multiple VPCs and on-premises networks. Monitor bandwidth usage patterns and add additional paths before reaching capacity limits – reactive scaling creates performance gaps that proactive planning prevents.
Leveraging AWS Global Accelerator for Improved User Experience
AWS Global Accelerator reduces latency by routing traffic through Amazon’s global network backbone instead of unpredictable internet paths. Create accelerators that direct traffic to optimal AWS regions based on geographic proximity and real-time network conditions. Configure health checks that automatically route traffic away from degraded endpoints before users experience slowdowns. Use weighted routing to gradually shift traffic during deployments or maintenance windows without service interruptions. Enable client affinity when applications require sticky sessions, but balance this against optimal routing performance. Deploy accelerators in multiple regions for global applications – users connect to the closest AWS edge location, then benefit from Amazon’s high-performance internal network to reach your hybrid infrastructure.
Designing Redundant Pathways to Eliminate Single Points of Failure
Redundancy planning goes beyond simple backup connections – design active-active pathways that provide both resilience and performance benefits. Establish Direct Connect circuits through different AWS Direct Connect locations to avoid facility-level outages. Create geographically diverse network paths using separate telecom providers and physical routes. Deploy redundant customer gateways in different on-premises locations with automatic failover capabilities. Configure multiple VPN tunnels with different encryption endpoints to maintain secure connectivity during primary circuit failures. Test failover scenarios regularly under load conditions – network redundancy only works when it’s proven to handle real-world traffic volumes seamlessly.
Data Flow Optimization Strategies for Hybrid Workloads
Intelligent Data Placement for Reduced Transfer Times
Smart data placement forms the backbone of high-performing hybrid AWS architecture performance systems. Place frequently accessed data closer to compute resources by leveraging AWS Local Zones and edge locations strategically. Analyze access patterns to identify hot datasets that benefit from on-premises storage versus cold data suitable for S3 Glacier. Use AWS DataSync and Storage Gateway to automate data movement based on usage metrics. Consider data gravity principles – keep related datasets in the same availability zone to minimize cross-region transfers. Implement tiered storage strategies where mission-critical data resides on high-performance NVMe while archival data moves to cost-effective magnetic storage. Geographic proximity matters significantly for latency-sensitive applications, so replicate datasets across multiple regions based on user distribution patterns.
Implementing Caching Layers for Frequently Accessed Resources
Multi-tiered caching dramatically improves hybrid workload data flow optimization by reducing redundant data transfers. Deploy Amazon ElastiCache at the application layer for sub-millisecond response times on frequently queried data. Combine Redis clusters with on-premises cache solutions like Hazelcast to create seamless data availability across environments. Use CloudFront for static content delivery while implementing application-level caching for dynamic data. Configure cache hierarchies where edge caches serve regional traffic and central caches handle complex queries. Set intelligent cache eviction policies based on access frequency and data freshness requirements. Monitor cache hit ratios continuously and adjust cache sizes dynamically to maintain optimal performance ratios above 90%.
Optimizing Database Synchronization Across Environments
Database synchronization requires careful orchestration to maintain consistency without sacrificing performance in AWS hybrid cloud optimization scenarios. Implement asynchronous replication for non-critical data while reserving synchronous replication for transactional systems. Use AWS Database Migration Service for initial data loads and ongoing change data capture. Configure read replicas strategically across regions to distribute query loads and reduce primary database strain. Implement conflict resolution strategies for multi-master setups using timestamp-based or application-specific logic. Monitor replication lag metrics and set automated alerts when synchronization delays exceed acceptable thresholds. Consider eventual consistency models for applications that can tolerate brief data inconsistencies in exchange for better performance and availability.
Compute Resource Orchestration for Peak Performance
Right-Sizing EC2 Instances Based on Workload Demands
Effective AWS compute resource orchestration starts with matching instance types to actual workload characteristics rather than defaulting to general-purpose options. Performance-focused hybrid architectures require granular analysis of CPU, memory, network, and storage requirements across different application tiers. Memory-intensive databases benefit from R-series instances, while compute-heavy analytics workloads perform better on C-series configurations. Regular performance profiling helps identify when applications are over-provisioned or resource-starved. Dynamic workloads often need different instance families during peak versus off-peak periods. Smart instance selection reduces costs by 30-40% while improving application response times through better resource alignment.
Implementing Auto-Scaling Across Hybrid Infrastructure
Cross-environment auto-scaling bridges on-premises capacity limits with cloud elasticity for seamless performance scaling. Application Load Balancers distribute traffic between local and AWS resources based on real-time performance metrics and predefined thresholds. CloudWatch metrics trigger scaling events that can spin up EC2 instances when on-premises infrastructure reaches capacity limits. Predictive scaling uses machine learning to anticipate demand spikes before they impact performance. Custom scaling policies consider network latency, data locality, and compliance requirements when deciding where to provision new resources. This approach maintains consistent user experience while optimizing costs across hybrid infrastructure components.
Leveraging Spot Instances for Cost-Effective Performance Bursts
Spot instances provide up to 90% cost savings for fault-tolerant workloads that can handle interruptions gracefully. Batch processing, data analytics, and development environments are ideal candidates for spot capacity in hybrid AWS architecture performance optimization. Mixed instance type policies combine spot and on-demand instances to balance cost savings with availability requirements. Spot fleet requests automatically replace interrupted instances across multiple availability zones and instance types. Proper application design with checkpointing and state management makes workloads resilient to spot interruptions. This strategy enables burst capacity for performance-critical tasks without long-term infrastructure commitments or budget constraints.
Optimizing Container Orchestration with EKS and On-Premises Integration
Amazon EKS provides managed Kubernetes control plane that extends seamlessly to on-premises container environments through EKS Anywhere or self-managed clusters. Container workloads benefit from consistent orchestration policies, networking, and security controls across hybrid infrastructure. Cross-cluster service mesh technologies like Istio enable secure communication and traffic management between cloud and on-premises containers. GitOps deployment pipelines ensure consistent application delivery regardless of target infrastructure location. Resource requests and limits help Kubernetes scheduler make optimal placement decisions based on node capacity and workload requirements. This unified approach simplifies container management while maintaining performance optimization across distributed infrastructure components.
Performance Monitoring and Continuous Optimization
Implementing Real-Time Performance Monitoring Across All Environments
Real-time monitoring transforms hybrid AWS architecture performance by providing instant visibility into bottlenecks across on-premises and cloud resources. Deploy unified monitoring agents that capture metrics from compute instances, network connections, and storage systems simultaneously. CloudWatch combined with third-party tools like Datadog or New Relic creates comprehensive dashboards showing cross-environment performance patterns. Set up automated alerts that trigger when latency exceeds thresholds or throughput drops below acceptable levels. This approach catches issues before they impact users and enables rapid response to performance degradation in your hybrid workload data flow optimization strategy.
Using AWS Performance Insights for Database Optimization
Performance Insights delivers database-specific metrics that reveal query bottlenecks, connection issues, and resource contention in hybrid environments. The service automatically identifies top SQL statements consuming resources and provides recommendations for index optimization and query tuning. Enable Enhanced Monitoring alongside Performance Insights to correlate database performance with underlying EC2 instance metrics. Use the service’s machine learning capabilities to predict performance trends and identify anomalies before they cause outages. This granular visibility helps maintain consistent database performance whether your workloads run on RDS, Aurora, or on-premises databases connected through hybrid connectivity.
Automated Performance Tuning with Machine Learning
AWS Auto Scaling and predictive scaling leverage machine learning algorithms to automatically adjust resources based on historical usage patterns and real-time demand. Implement AWS Compute Optimizer recommendations that analyze your hybrid compute resource orchestration and suggest optimal instance types and sizes. Use Amazon DevOps Guru to detect performance anomalies and receive intelligent insights about potential issues across your hybrid infrastructure. Set up automated remediation workflows through AWS Systems Manager that respond to performance alerts by scaling resources, restarting services, or routing traffic to healthier endpoints without manual intervention.
Creating Performance Dashboards for Proactive Issue Resolution
Build custom CloudWatch dashboards that combine metrics from multiple AWS services with on-premises monitoring data through CloudWatch agent and custom metrics. Create heat maps showing performance hotspots across different regions and availability zones in your hybrid AWS architecture performance setup. Design role-based dashboards that surface relevant metrics for different teams – network engineers see latency and throughput, while application teams focus on response times and error rates. Integrate these dashboards with notification systems like Amazon SNS to send alerts through Slack, email, or mobile apps when performance thresholds are breached, enabling rapid response to issues.
Building a high-performing hybrid AWS architecture requires thinking beyond simple connectivity. The most successful implementations focus on strategic network design that prioritizes throughput and minimizes latency, smart data flow optimization that keeps workloads running smoothly across environments, and careful orchestration of compute resources to handle peak demands. These aren’t just technical checkboxes—they’re the foundation of a system that actually delivers results.
Performance doesn’t happen by accident, and it definitely doesn’t stay consistent without effort. Set up robust monitoring from day one and make continuous optimization part of your regular routine. Your hybrid architecture should evolve with your business needs, not hold them back. Start with these performance principles in mind, and you’ll build something that scales gracefully and performs reliably when it matters most.