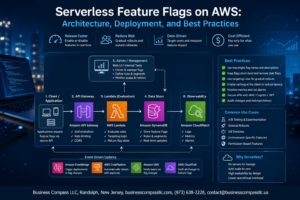
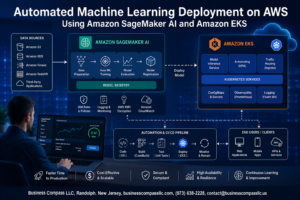
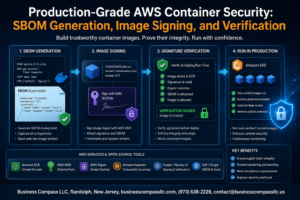
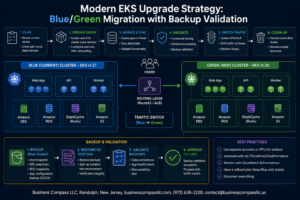
Managing AWS observability doesn’t have to feel like solving a puzzle with missing pieces. This guide helps DevOps engineers, cloud architects, and platform teams cut through the complexity of monitoring distributed AWS environments.
You’ll discover how to build a solid AWS observability strategy that actually works for your team. We’ll walk through setting up native observability tools AWS provides, show you how to create dashboards that surface real problems (not just pretty charts), and share practical ways to keep your observability cost optimization under control.
By the end, you’ll have a clear roadmap for AWS environment monitoring that scales with your infrastructure and gives your team the insights they need to keep services running smoothly.
Understanding the Observability Challenge in AWS
Identifying blind spots in complex cloud infrastructures
AWS environments create visibility gaps that catch teams off guard. Microservices architectures spread across multiple regions generate data silos that traditional monitoring approaches miss. Cross-service dependencies become invisible until failures cascade through your entire system. Auto-scaling groups launch and terminate instances faster than manual tracking can follow, leaving gaps in your observability coverage. Container workloads in EKS clusters create ephemeral endpoints that disappear before you can establish monitoring baselines. Serverless functions execute without leaving traces in your standard logging infrastructure. These blind spots grow exponentially as your AWS footprint expands, making it nearly impossible to maintain complete visibility using scattered monitoring tools.
Recognizing the cost of poor visibility on business operations
Poor AWS observability costs businesses far more than monitoring tools ever could. When production incidents occur without clear visibility, your teams waste hours manually correlating logs across CloudWatch, X-Ray, and third-party systems. Mean time to resolution stretches from minutes to hours while customer-facing services remain degraded. Revenue loss compounds during outages that could have been prevented with proper alerting on key performance indicators. Your engineering teams burn through expensive developer hours troubleshooting issues that comprehensive observability would have surfaced immediately. Compliance violations slip through when audit trails remain incomplete across your distributed AWS services. These operational inefficiencies create technical debt that slows future development cycles and increases infrastructure costs through over-provisioning safety nets.
Mapping the three pillars of observability to AWS services
AWS provides native services that align perfectly with observability’s three foundational pillars. Metrics flow through CloudWatch, collecting performance data from EC2 instances, RDS databases, Lambda functions, and custom application counters that reveal system health patterns. Logs centralize in CloudWatch Logs, aggregating application output, VPC flow logs, API Gateway access patterns, and container stdout streams for comprehensive debugging capabilities. Traces connect through X-Ray, mapping request journeys across microservices, identifying bottlenecks in distributed architectures, and correlating errors with specific code paths. These AWS observability tools work together to create complete visibility into your cloud environment. CloudTrail adds an audit dimension by tracking API calls and configuration changes. When properly configured, this native AWS observability strategy provides the foundation for proactive monitoring and rapid incident response.
Native AWS Observability Tools That Drive Results
Leveraging CloudWatch for comprehensive monitoring and alerting
CloudWatch serves as the central nervous system for AWS observability, collecting metrics from over 80 AWS services automatically. Set up custom dashboards to visualize key performance indicators across EC2 instances, Lambda functions, and RDS databases. Create intelligent alarms that trigger when thresholds are breached, enabling proactive issue resolution. Use CloudWatch Logs to centralize application and system logs, making troubleshooting faster and more effective.
Utilizing AWS X-Ray for distributed tracing insights
X-Ray provides end-to-end visibility into request flows across microservices architectures, helping identify performance bottlenecks and errors. Trace requests as they move through Lambda functions, API Gateway, and downstream services to pinpoint slow components. The service map visualization shows dependencies and latency patterns, making complex distributed systems easier to understand. Enable X-Ray tracing with minimal code changes to start gathering actionable insights immediately.
Implementing CloudTrail for security and compliance tracking
CloudTrail captures every API call made within your AWS environment, creating an audit trail for security analysis and compliance reporting. Monitor who accessed what resources and when, helping detect unauthorized activities or configuration changes. Set up multi-region trails to ensure comprehensive coverage across all AWS regions you’re using. Integrate CloudTrail logs with CloudWatch for real-time alerting on suspicious activities.
Maximizing AWS Config for configuration management visibility
AWS Config continuously monitors and records configuration changes across your infrastructure, providing a complete inventory of AWS resources. Track compliance against organizational policies and industry standards automatically. Use Config Rules to evaluate resource configurations against best practices, triggering alerts when deviations occur. The timeline feature shows how resources have changed over time, making it easier to correlate configuration changes with performance issues or security incidents.
Streamlining Data Collection Across Your AWS Environment
Configuring Automated Log Aggregation from Multiple Sources
Centralized log collection transforms chaotic AWS environments into manageable monitoring ecosystems. AWS CloudWatch Logs automatically captures application, system, and infrastructure logs from EC2 instances, Lambda functions, and container services through unified agents. The CloudWatch Agent streams logs in real-time while custom log groups organize data by service, environment, or application tier. Cross-account log destinations enable enterprise-wide visibility, allowing security teams and developers to access relevant logs without duplicating infrastructure. VPC Flow Logs, CloudTrail events, and application logs merge into searchable streams that power both operational troubleshooting and compliance reporting across your entire AWS environment.
Setting Up Custom Metrics for Business-Critical Applications
Application-specific metrics reveal performance patterns that standard infrastructure monitoring misses completely. CloudWatch custom metrics capture business KPIs like transaction completion rates, user session duration, and revenue per API call through simple SDK integration. StatsD-compatible agents collect application metrics from containerized workloads while Lambda functions publish custom metrics directly to CloudWatch endpoints. Metric filters transform log data into quantitative measurements, converting error patterns and user behavior into actionable dashboard visualizations. High-resolution metrics provide sub-minute granularity for critical services, enabling rapid response to performance degradation before customers notice impact.
Implementing Distributed Tracing Without Performance Overhead
AWS X-Ray maps request flows through complex microservice architectures while maintaining minimal application impact. Automatic instrumentation libraries for popular frameworks capture trace data without code modifications, while sampling rules control overhead by tracing representative request subsets. Service maps visualize dependencies and bottlenecks across Lambda functions, API Gateway, and downstream databases with response time distributions. Custom annotations and metadata add business context to technical traces, helping developers correlate user actions with system behavior. Integration with CloudWatch and third-party APM tools creates comprehensive observability pipelines that scale automatically with application growth patterns.
Creating Actionable Dashboards and Alerts
Designing Executive-Level Dashboards for Business Stakeholders
Executive dashboards need to translate technical AWS observability data into business impact metrics. Focus on application uptime percentages, customer experience scores, revenue-affecting incidents, and cost trends. Use visual elements like traffic light indicators and trend lines that communicate health status at a glance. Include business-critical KPIs such as transaction success rates, user session metrics, and service availability across different geographic regions. These dashboards should update in real-time and provide drill-down capabilities when executives need deeper context about performance issues affecting business operations.
Building Technical Dashboards for Development Teams
Development teams require granular AWS monitoring and logging visibility into application performance, infrastructure health, and deployment success rates. Create role-specific views showing error rates, response times, database performance, and resource utilization across your AWS environment monitoring setup. Include code deployment pipelines, API endpoint performance, and dependency mapping to help developers quickly identify bottlenecks. Technical dashboards should integrate with development workflows, displaying recent commits, feature flag status, and A/B testing results alongside traditional infrastructure metrics for comprehensive observability.
Establishing Intelligent Alerting to Reduce Noise and False Positives
Smart alerting strategies prevent alert fatigue by implementing dynamic thresholds based on historical patterns and business context. Use AWS CloudWatch setup with machine learning-based anomaly detection to distinguish between normal variance and genuine issues. Implement alert correlation to group related incidents and reduce duplicate notifications. Configure different severity levels with appropriate notification channels – critical alerts for immediate response, warnings for trend monitoring. Establish quiet hours for non-critical alerts and use alert suppression during planned maintenance windows to maintain focus on genuine emergencies.
Implementing Escalation Procedures for Critical Incidents
Effective escalation procedures ensure critical AWS observability incidents reach the right people at the right time. Design tiered response protocols starting with on-call engineers, escalating to team leads, then management based on incident duration and business impact. Automate initial response actions like scaling resources or failing over to backup systems while human responders are contacted. Document clear escalation timelines, contact methods, and decision-making authority at each level. Include communication templates for stakeholder updates and post-incident review processes to continuously improve your observability best practices and response effectiveness.
Optimizing Observability Costs While Maximizing Value
Right-sizing log retention policies for compliance and budget
Smart log retention policies balance regulatory requirements with cost control. Most compliance frameworks require specific retention periods, but storing logs beyond necessary timeframes creates unnecessary expenses. CloudWatch Logs charges for storage duration, so configure automatic deletion after compliance periods end. Business-critical applications might need 90-day retention, while development environments could use 7-14 days. Archive older logs to S3 Glacier for long-term compliance at significantly lower costs.
Implementing sampling strategies for high-volume applications
High-traffic applications generate massive amounts of telemetry data that can overwhelm budgets. AWS X-Ray sampling rules help capture representative traces without storing every request. Start with 1% sampling for normal operations and increase to 10% during errors. CloudWatch supports metric filters to reduce log ingestion volume while maintaining visibility into critical events. Focus sampling on user-facing transactions and error conditions rather than internal health checks or automated processes.
Leveraging reserved capacity and committed use discounts
AWS observability cost optimization benefits from predictable usage patterns through reserved capacity options. CloudWatch committed use pricing offers up to 51% savings for consistent log ingestion volumes. X-Ray reserved capacity provides 20% discounts for predictable tracing workloads. Analyze your monthly usage patterns across observability services and commit to baseline capacity levels. Combine these with AWS Savings Plans for additional discounts on compute resources running monitoring agents and collectors.
Automating cost monitoring for observability services
Proactive cost monitoring prevents observability budget surprises through automated alerts and optimization recommendations. Set up CloudWatch billing alarms for each observability service with progressive thresholds at 50%, 80%, and 100% of monthly budgets. AWS Cost Explorer provides detailed breakdowns of CloudWatch, X-Ray, and other monitoring service expenses. Create Lambda functions that analyze usage patterns and automatically adjust retention policies or sampling rates when costs exceed targets, ensuring continuous optimization without manual intervention.
Scaling Observability Practices Across Teams
Establishing observability standards and best practices
Creating consistent AWS observability standards across your organization starts with defining clear metrics, naming conventions, and alerting thresholds. Document which AWS CloudWatch metrics matter most for each service type, establish standardized log formats, and create shared dashboards that teams can easily replicate. Build a centralized knowledge base that captures your AWS observability best practices, including which native tools to use for specific scenarios and how to structure monitoring hierarchies that scale with your infrastructure growth.
Training development teams on self-service monitoring
Empower your development teams to own their observability by providing hands-on training with AWS monitoring and logging tools. Set up workshops that walk through real scenarios using CloudWatch, X-Ray, and CloudTrail, showing developers how to instrument their applications and create meaningful alerts. Build internal documentation with step-by-step guides for common tasks like setting up custom metrics, creating log insights queries, and configuring auto-scaling based on observability data. The goal is making teams self-sufficient rather than dependent on central operations.
Creating reusable templates and automation scripts
Develop Infrastructure as Code templates that automatically provision observability resources alongside your applications. Use AWS CloudFormation or CDK to create standardized monitoring stacks that include dashboards, alarms, and log groups configured with proper retention policies. Build automation scripts that set up observability for new services using your established patterns, and create a template library that teams can quickly deploy for common use cases. This approach ensures consistent AWS observability implementation while reducing manual setup time and potential configuration drift across your environment.
Monitoring your AWS environment doesn’t have to feel like solving a puzzle with missing pieces. The key is building a solid foundation with native AWS tools like CloudWatch, X-Ray, and CloudTrail, then organizing your data collection to actually make sense of what’s happening across your infrastructure. When you create dashboards that show what matters and set up alerts that don’t cry wolf, you’ll spend less time firefighting and more time building.
The real win comes from finding that sweet spot between comprehensive monitoring and reasonable costs. Start small with the most critical services, get your team comfortable with the tools, and then expand from there. Remember, the best observability strategy is one that your entire team can use effectively – not just the person who set it up. Focus on making your monitoring simple enough that everyone can jump in when things go sideways.