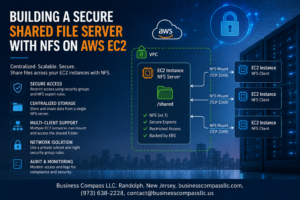
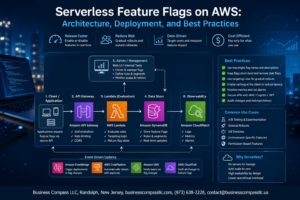
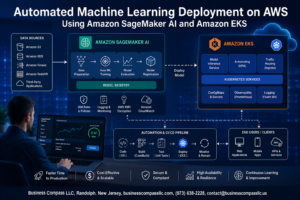
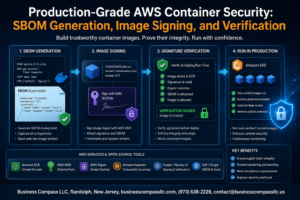
Modern software teams face relentless pressure to ship features faster while keeping production systems rock-solid. Test automation CI/CD pipelines offer the perfect solution, letting development teams release code confidently without sacrificing quality or speed.
This guide is designed for DevOps engineers, software developers, QA professionals, and technical leads who want to build bulletproof deployment processes. You’ll learn how automated testing strategies can catch bugs early, reduce manual testing overhead, and keep your production environment stable even during rapid release cycles.
We’ll dive into building robust automated test suites that integrate seamlessly with your continuous integration workflow. You’ll discover smart testing strategies that prevent production failures by catching issues at the right pipeline stages. Finally, we’ll explore CI/CD pipeline optimization techniques that boost both testing efficiency and developer productivity, so your team can move fast without breaking things.
Ready to transform your release process from a nail-biting experience into a smooth, predictable machine? Let’s explore how the right test automation approach can make frequent deployments feel effortless.
Understanding Test Automation’s Role in Modern CI/CD Workflows

Defining Automated Testing Within Continuous Integration Frameworks
Test automation CI/CD pipelines transform software delivery by embedding testing directly into the development workflow. Within continuous integration frameworks, automated testing means running predefined test scripts automatically whenever developers commit code changes. This creates an immediate feedback loop that catches bugs early, before they reach production environments.
The integration works through trigger-based execution where every code push initiates a series of automated tests. These tests validate functionality, performance, and security without human intervention. Continuous integration testing becomes the safety net that ensures each code change maintains system stability while enabling rapid development cycles.
Modern CI/CD frameworks like Jenkins, GitLab CI, and GitHub Actions orchestrate these automated tests across different environments. They manage test scheduling, resource allocation, and result reporting, creating a seamless testing experience that scales with development teams.
Key Differences Between Manual and Automated Testing Approaches
Manual testing requires human testers to execute test cases step-by-step, making it time-intensive and prone to human error. Automated testing eliminates these constraints by running tests at machine speed with consistent execution every time.
| Aspect | Manual Testing | Automated Testing |
|---|---|---|
| Speed | Hours to days | Minutes to hours |
| Consistency | Variable results | Identical execution |
| Cost Over Time | High labor costs | Low operational costs |
| Coverage | Limited scope | Extensive coverage |
| Regression Testing | Time-prohibitive | Effortless execution |
Automated testing strategies excel at repetitive tasks like regression testing, data validation, and performance monitoring. Manual testing remains valuable for exploratory testing, usability evaluation, and complex scenario validation that requires human judgment.
The hybrid approach combines both methods strategically. Automated tests handle the heavy lifting of continuous validation, while manual testing focuses on areas requiring creativity and critical thinking.
Critical Testing Stages That Benefit Most From Automation
Unit testing represents the foundation of CI/CD pipeline optimization, where individual code components get validated in isolation. These tests run fastest and provide immediate developer feedback, making them perfect for automation within continuous integration workflows.
Integration testing automated within CI/CD pipelines catches interface issues between system components. As applications grow complex with microservices and APIs, automated integration tests prevent communication breakdowns that manual testing might miss.
DevOps test automation particularly shines during regression testing phases. Every code change potentially breaks existing functionality, making comprehensive regression testing essential but impractical to perform manually with each deployment.
Performance testing automation monitors response times, throughput, and resource usage continuously. Automated performance tests catch degradation trends before they impact users, something impossible with sporadic manual testing.
Security testing automation scans for vulnerabilities, checks authentication flows, and validates data protection measures. Given the frequency of security threats, automated security testing provides consistent protection that manual processes can’t match.
How Test Automation Accelerates Deployment Cycles
Test automation best practices compress testing timeframes from weeks to hours, directly accelerating deployment cycles. Where manual testing creates bottlenecks that delay releases, automated tests run in parallel across multiple environments simultaneously.
The speed advantage compounds through continuous deployment testing practices. Automated tests enable multiple daily deployments by providing rapid validation at each pipeline stage. Development teams can release features as soon as they’re ready, rather than waiting for testing windows.
Automated test suites eliminate the coordination overhead of manual testing teams. No scheduling test resources, no waiting for human availability, no handoff delays between testing phases. The pipeline executes tests immediately when triggered, maintaining deployment momentum.
Early bug detection through automated testing prevents expensive fixes later in the development cycle. Catching issues during development costs significantly less than discovering them in production, where fixes require emergency deployments and potential rollbacks.
Parallel test execution multiplies testing capacity without linear cost increases. A single automated test suite can validate functionality across multiple browsers, operating systems, and device configurations simultaneously, achieving coverage levels impossible with manual testing approaches.
Building Robust Automated Test Suites for Continuous Integration

Selecting the Right Testing Frameworks and Tools for Your Stack
Choosing the proper testing frameworks forms the backbone of effective test automation CI/CD pipelines. Your tech stack dictates which tools will integrate smoothly into your continuous integration testing workflow. For JavaScript applications, Jest and Cypress offer excellent coverage for unit and end-to-end testing respectively. Python developers often gravitate toward pytest for its flexibility and extensive plugin ecosystem, while Java teams frequently rely on JUnit combined with TestNG for comprehensive test coverage.
Consider your team’s expertise when selecting frameworks. A tool that looks impressive on paper won’t deliver results if developers struggle with its learning curve. Open-source solutions like Selenium WebDriver provide cross-browser compatibility, while commercial tools like TestComplete offer enhanced reporting features. The key lies in balancing functionality with maintainability.
Your CI/CD testing frameworks should support parallel execution to avoid pipeline bottlenecks. Tools like TestNG and pytest-xdist excel at running tests concurrently, significantly reducing build times. Integration with your existing infrastructure matters too – ensure your chosen tools can generate reports in formats your CI system understands.
| Framework Type | Popular Options | Best For |
|---|---|---|
| Unit Testing | Jest, pytest, JUnit | Fast feedback loops |
| Integration | Postman, REST Assured | API validation |
| End-to-End | Cypress, Playwright | User journey testing |
| Performance | JMeter, k6 | Load validation |
Creating Comprehensive Unit Tests That Catch Bugs Early
Unit tests serve as your first line of defense in automated test suites, catching issues before they cascade through your system. These tests should focus on individual functions or methods, validating specific behaviors in isolation. The goal isn’t achieving 100% code coverage – it’s writing meaningful tests that verify critical business logic and edge cases.
Effective unit tests follow the Arrange-Act-Assert pattern. Set up your test data, execute the function under test, and verify the expected outcome. Mock external dependencies to keep tests fast and reliable. A well-designed unit test runs in milliseconds and provides clear failure messages when something breaks.
Test-driven development (TDD) naturally creates robust unit test coverage. Write failing tests first, implement just enough code to make them pass, then refactor. This approach ensures every line of production code has corresponding test coverage and prevents over-engineering.
Focus on testing behaviors rather than implementation details. Tests that verify internal method calls or private variables become brittle and break during refactoring. Instead, test the observable outcomes – what happens when you call a function with specific inputs.
Implementing Integration Tests That Verify System Interactions
Integration tests validate how different components work together, catching issues that unit tests miss. These tests verify database connections, API interactions, and service communications within your application. Unlike unit tests that use mocks, integration tests work with real or near-real dependencies.
Database integration tests should use test-specific databases or containers to avoid conflicts. Docker makes this straightforward – spin up a fresh database instance for each test run. Test your data access layer thoroughly, including edge cases like connection timeouts and constraint violations.
API integration tests verify that your services communicate correctly. Test both happy paths and error scenarios. Ensure proper handling of authentication, rate limiting, and network timeouts. Tools like WireMock can simulate external service responses, giving you control over test scenarios without depending on third-party availability.
Message queue integration requires special attention in distributed systems. Test message publishing, consumption, and dead letter queue handling. Verify that your system gracefully handles message failures and maintains data consistency across service boundaries.
Designing End-to-End Tests That Validate User Workflows
End-to-end tests simulate real user interactions with your application, validating complete workflows from start to finish. These tests catch integration issues between frontend and backend systems, ensuring that critical user journeys work as expected. While slower than unit tests, they provide confidence that your application delivers value to users.
Focus on core user workflows rather than comprehensive feature coverage. Test the most important paths through your application – user registration, checkout processes, or data submission flows. Avoid testing every possible combination; that’s what unit and integration tests handle.
Page Object Model (POM) design pattern keeps end-to-end tests maintainable. Create classes that encapsulate page interactions, reducing code duplication and making tests easier to update when UI changes occur. Each page object should expose methods that represent user actions rather than low-level element interactions.
Test data management becomes crucial for end-to-end tests. Use factories or builders to create consistent test data. Consider using database seeders or API calls to set up test scenarios rather than clicking through complex setup workflows. This approach makes tests faster and more reliable.
Establishing Performance Tests That Prevent Production Bottlenecks
Performance tests integrated into your DevOps test automation pipeline catch scalability issues before they reach users. These tests validate response times, throughput, and resource utilization under various load conditions. Early performance validation prevents costly production incidents and emergency scaling situations.
Load testing simulates normal user traffic patterns to establish baseline performance metrics. Create realistic test scenarios based on production usage patterns. Test with gradual load increases to identify when performance degrades and understand your application’s breaking point.
Stress testing pushes your system beyond normal capacity to identify failure modes. These tests reveal how your application behaves under extreme conditions and help plan capacity requirements. Monitor not just response times but also error rates and system resource consumption.
Performance test automation requires consistent environments and reliable test data. Use infrastructure as code to ensure test environments match production characteristics. Containerized testing environments provide consistency and make it easier to scale test execution.
Set clear performance criteria and fail builds when thresholds are exceeded. Define acceptable response times for different operation types and configure your CI/CD pipeline optimization to reject deployments that don’t meet standards. This approach prevents performance regressions from reaching production and maintains user experience quality.
Strategic Test Execution in CI/CD Pipeline Stages

Optimizing Test Execution Order for Maximum Efficiency
Smart test execution ordering can dramatically reduce your CI/CD pipeline duration while maintaining comprehensive coverage. The key lies in running the fastest, most critical tests first to catch obvious failures early and reserve slower integration tests for later stages.
Start with unit tests – they’re lightning-fast and catch the majority of basic code issues. These tests should complete within minutes and form your first line of defense. Follow up with component tests that validate individual services or modules without external dependencies.
Place API and integration tests in the middle tier, as they typically take longer but provide crucial validation of system interactions. Save end-to-end tests and UI automation for the final stage, since these are the slowest but most comprehensive.
Consider implementing risk-based ordering where tests covering recently changed code paths run first. This approach maximizes the probability of catching failures early in the pipeline, saving valuable time when developers are waiting for feedback.
| Test Type | Execution Order | Typical Duration | Purpose |
|---|---|---|---|
| Unit Tests | 1st | 30 seconds – 2 minutes | Code logic validation |
| Component Tests | 2nd | 2-5 minutes | Service-level validation |
| Integration Tests | 3rd | 5-15 minutes | System interaction testing |
| E2E Tests | 4th | 15-45 minutes | Full workflow validation |
Implementing Parallel Testing to Reduce Pipeline Duration
Parallel test execution transforms pipeline performance by running multiple test suites simultaneously across different environments or test categories. Modern CI/CD platforms like Jenkins, GitLab CI, and GitHub Actions support parallel job execution that can cut testing time by 60-80%.
Split your test suites logically across parallel runners. Distribute unit tests across multiple workers based on modules or packages. Run integration tests for different services simultaneously on separate environments. Execute browser-based tests across different browsers in parallel rather than sequentially.
Container orchestration makes parallel testing more efficient. Spin up multiple Docker containers running identical test environments, each handling a subset of your test suite. This approach scales naturally with your infrastructure and maintains consistency across test runs.
Database testing requires special consideration in parallel execution. Use separate test databases for each parallel runner or implement database seeding strategies that prevent conflicts. Consider using in-memory databases for faster unit tests while reserving full database instances for integration testing.
Monitor resource utilization carefully when implementing parallel testing. Too many concurrent tests can overwhelm your CI infrastructure, leading to flaky tests and inconsistent results. Find the sweet spot between speed and stability through gradual scaling and performance monitoring.
Setting Up Fail-Fast Mechanisms to Stop Broken Builds Quickly
Fail-fast mechanisms prevent wasted resources and provide rapid feedback when builds are destined to fail. Configure your pipeline to halt execution immediately when critical tests fail, rather than continuing through all stages.
Implement dependency chains where each pipeline stage depends on the success of the previous one. If unit tests fail, skip integration and deployment stages entirely. This saves compute resources and gives developers faster feedback about issues that need immediate attention.
Set up quality gates with specific thresholds for test coverage, code quality metrics, and performance benchmarks. When these thresholds aren’t met, automatically stop the pipeline and notify the development team. This prevents problematic code from advancing through your deployment stages.
Use conditional execution for different types of failures. Critical test failures should halt the entire pipeline, while less severe issues like minor performance degradations might allow the build to continue with warnings. Configure notification systems to alert different team members based on failure severity and affected components.
Implement timeout mechanisms for long-running tests to prevent pipelines from hanging indefinitely. Set reasonable time limits for each test stage and fail gracefully when tests exceed these boundaries. This keeps your CI/CD system responsive and prevents resource bottlenecks that can affect other teams’ work.
Preventing Production Failures Through Smart Testing Strategies

Creating staging environments that mirror production systems
Staging environments serve as your last line of defense before code reaches real users. The key to effective production failure prevention lies in making these environments as identical to production as possible. This means matching hardware specifications, network configurations, database schemas, and even load patterns that mirror your actual user traffic.
Building accurate staging environments requires careful attention to data management. Use production-like datasets that contain realistic volumes and complexity without exposing sensitive information. Anonymous production data or synthetic datasets that maintain statistical properties work well for this purpose. Your automated testing strategies should validate not just functionality but also performance characteristics under realistic conditions.
Infrastructure as Code (IaC) tools help maintain consistency between staging and production environments. Docker containers, Kubernetes manifests, and cloud formation templates ensure that your staging environment doesn’t drift from production configurations. This consistency dramatically reduces the “it works on my machine” syndrome that plagues many CI/CD pipelines.
Implementing blue-green deployment testing protocols
Blue-green deployments offer a powerful approach to test automation CI/CD pipelines by maintaining two identical production environments. Only one environment serves live traffic while the other remains idle, ready for the next deployment. This strategy allows comprehensive testing of new releases in a production-like environment without affecting users.
The testing protocol for blue-green deployments involves multiple validation stages. Start with automated smoke tests that verify basic functionality across critical user journeys. Follow with performance benchmarks that compare response times and resource usage against established baselines. Health checks should monitor application metrics, database connections, and external service integrations.
| Testing Phase | Validation Type | Success Criteria |
|---|---|---|
| Smoke Tests | Basic functionality | All critical paths working |
| Performance | Response times | Within 10% of baseline |
| Health Checks | System metrics | All services responding |
| User Acceptance | Real user validation | Sample traffic routing successful |
The beauty of blue-green testing lies in the safety net it provides. If any validation fails, traffic stays on the current environment while teams investigate issues. This approach eliminates the pressure of quick fixes in production and allows thorough problem resolution.
Setting up automated rollback triggers for failed deployments
Automated rollback mechanisms act as crucial safety valves in continuous deployment testing workflows. These triggers monitor key performance indicators and automatically revert deployments when predefined thresholds are breached. Setting up effective rollback triggers requires careful selection of metrics that accurately reflect application health and user experience.
Error rates, response times, and business metrics should all factor into rollback decisions. A sudden spike in 500 errors, database connection failures, or payment processing issues should trigger immediate rollbacks. The challenge lies in distinguishing between temporary fluctuations and genuine deployment problems.
Implement graduated rollback strategies that first reduce traffic to problematic deployments before complete rollback. This approach helps isolate issues while minimizing user impact. Automated rollback systems should also capture detailed logs and system state information to aid post-incident analysis.
Time-based rollback triggers add another layer of protection. If a deployment shows no obvious problems but fails to complete health checks within a specified timeframe, automatic rollback prevents prolonged outages. This approach works particularly well for database migrations or infrastructure changes that might have delayed effects.
Using feature flags to safely test new functionality
Feature flags revolutionize how teams approach production failure prevention by decoupling deployment from feature activation. This DevOps test automation technique allows code to reach production while keeping new functionality hidden behind toggles that can be activated for specific users or conditions.
The power of feature flags lies in their granular control over feature exposure. Start by enabling new features for internal users or a small percentage of your user base. Monitor key metrics like error rates, performance impact, and user engagement before gradually expanding access. This progressive rollout approach catches issues early when they affect fewer users.
Feature flags excel in A/B testing scenarios where you need to compare different implementations. Deploy multiple versions of a feature behind different flags and route traffic based on user segments. This approach provides real-world performance data while maintaining the ability to quickly disable problematic variants.
Circuit breaker patterns work exceptionally well with feature flags. When external service dependencies fail or performance degrades, automatically disable features that rely on those services. This prevents cascading failures while maintaining core functionality for users.
Emergency shutoff capabilities make feature flags invaluable for risk management. During incidents, teams can quickly disable problematic features without deploying new code or rolling back entire releases. This surgical approach to incident response minimizes user impact while buying time for proper fixes.
Maximizing Pipeline Performance and Developer Productivity
Balancing Test Coverage with Execution Speed
Finding the sweet spot between comprehensive test coverage and fast pipeline execution requires a strategic approach to test automation CI/CD pipelines. Speed matters because developers need quick feedback, but cutting corners on coverage can lead to production failures.
The key lies in test pyramid implementation. Unit tests should form the foundation – they’re fast, reliable, and catch most issues early. Integration tests occupy the middle layer, validating component interactions without the overhead of full system tests. End-to-end tests sit at the top, covering critical user journeys but running sparingly due to their execution time.
Consider implementing test categories based on execution speed and business impact:
| Test Type | Execution Time | Coverage Focus | Pipeline Stage |
|---|---|---|---|
| Unit Tests | < 10 minutes | Code logic | Every commit |
| Integration | 10-30 minutes | Component interaction | Feature branches |
| E2E Critical | 30-60 minutes | Core user flows | Pre-production |
| E2E Extended | 60+ minutes | Edge cases | Nightly builds |
Parallel execution across multiple environments dramatically reduces overall pipeline time. Modern CI/CD pipeline optimization tools can distribute tests across containers or virtual machines, turning a 2-hour test suite into a 20-minute parallel run.
Implementing Smart Test Selection Based on Code Changes
Smart test selection revolutionizes automated testing strategies by running only tests affected by recent code changes. This approach, known as test impact analysis, examines the relationship between code modifications and test dependencies.
Modern CI/CD testing frameworks can analyze git diffs and map changes to relevant test cases. When a developer modifies a payment processing module, the system automatically identifies and runs payment-related tests while skipping unrelated UI or reporting tests.
Several techniques enable intelligent test selection:
- Static code analysis: Maps code changes to test files through import statements and method calls
- Dynamic dependency tracking: Records actual code paths during test execution to build accurate dependency graphs
- Historical failure analysis: Prioritizes tests that frequently fail when specific code areas change
- Risk-based selection: Weights test selection based on business criticality and past defect patterns
Implementation starts with instrumenting your test suite to collect coverage data. Tools like Jest, pytest-cov, or JaCoCo generate detailed reports showing which code lines each test exercises. This data feeds machine learning algorithms that predict which tests need to run for any given change set.
The benefits compound over time. Teams report 60-80% reduction in test execution time while maintaining the same defect detection rate. Developers get faster feedback, and CI/CD resources are used more efficiently.
Creating Meaningful Test Reports and Failure Notifications
Effective test reporting transforms raw test results into actionable insights that drive developer productivity and code quality. Generic pass/fail notifications create noise; meaningful reports provide context and guidance for quick resolution.
Modern test reports should include:
- Failure categorization: Group failures by type (flaky tests, environment issues, genuine bugs)
- Historical trends: Show failure patterns over time to identify recurring issues
- Performance metrics: Track test execution times and resource usage
- Coverage deltas: Highlight coverage changes from the current commit
- Affected areas: Map failures to specific features or team ownership
Smart notification systems send different information to different stakeholders. Developers receive detailed stack traces and suggested fixes, while product managers get high-level summaries focusing on feature impact. Team leads see trends and resource allocation recommendations.
Failure notifications work best when they’re context-aware. Instead of “Test failed,” effective notifications say “Payment integration test failed due to API timeout – similar failures occurred 3 times this week in staging environment.” This context helps developers quickly understand whether they need to investigate their code or wait for infrastructure fixes.
Consider implementing notification channels based on severity:
- Critical failures (production blockers) trigger immediate Slack messages and phone alerts
- Standard failures create GitHub/JIRA tickets with detailed context
- Flaky test reports generate weekly summaries for maintenance planning
Establishing Maintenance Workflows for Test Suite Health
Test suite maintenance prevents the gradual degradation that turns valuable automated tests into productivity bottlenecks. Without regular care, test suites accumulate flaky tests, outdated assertions, and performance issues that slow down DevOps test automation initiatives.
Successful maintenance workflows include automated health monitoring. Track key metrics like test stability (pass rate over time), execution duration trends, and coverage gaps. Set up alerts when tests become flaky or when execution times exceed thresholds.
Regular maintenance tasks should be scheduled and assigned:
Weekly maintenance:
- Review flaky test reports and investigate root causes
- Update test data and environment configurations
- Remove or refactor slow-running tests
- Validate test coverage for new features
Monthly maintenance:
- Audit test suite architecture for redundancy
- Update testing frameworks and dependencies
- Review and retire obsolete test cases
- Analyze resource usage and optimize infrastructure
Quarterly maintenance:
- Conduct comprehensive test strategy review
- Update test automation best practices documentation
- Train team members on new tools and techniques
- Evaluate and potentially adopt new testing technologies
Create a rotation system where team members take turns being responsible for test suite health. This shared ownership ensures maintenance doesn’t fall on one person while building team-wide expertise in test automation tools and practices.
Implement automated cleanup processes that remove outdated test artifacts, archive old reports, and clean up test databases. These processes run on schedules, keeping your testing infrastructure lean and performant without manual intervention.

Test automation isn’t just a nice-to-have feature in modern development—it’s the backbone that makes continuous delivery actually work. When you build solid automated test suites and place them strategically throughout your CI/CD pipeline, you create a safety net that catches problems before they reach your users. Smart testing strategies give your team the confidence to push code faster while keeping production stable.
The real win comes when you balance speed with reliability. By focusing on the right tests at the right stages and keeping your pipeline performance optimized, your developers can ship features quickly without the constant fear of breaking something important. Start small with your test automation, focus on your most critical user paths, and gradually expand your coverage. Your future self (and your users) will thank you for taking the time to get this right.