








Database indexing transforms slow, table-scanning queries into lightning-fast data retrieval operations. This comprehensive guide targets database administrators, backend developers, and data engineers who need to optimize query performance across different use cases and storage systems.
You’ll discover how B-tree indexes serve as the reliable foundation for most relational databases, while hash index performance excels at exact-match lookups. We’ll explore specialized solutions like inverted index search engines that power Google and Elasticsearch, plus geospatial database queries that make location-based apps possible.
The guide covers write-heavy scenarios with LSM-tree storage, analytical workloads using columnar database indexing, and text-heavy applications requiring full-text search optimization. You’ll also learn when bitmap index efficiency shines for categorical data and how trie data structure enables autocomplete features.
Each index type includes practical implementation examples, performance trade-offs, and real-world scenarios where they deliver maximum impact.
Understanding Database Index Fundamentals

Why Proper Indexing Accelerates Query Performance
Database indexing transforms how your system retrieves data by creating shortcuts to specific information. Think of an index like a library’s card catalog – instead of scanning every book to find what you need, you check the organized reference system that points directly to the right shelf.
When you execute a query without proper indexing, the database engine performs a full table scan, examining every single row to find matching records. This brute-force approach becomes exponentially slower as your dataset grows. A table with millions of records might take seconds or minutes to return results that an indexed query delivers in milliseconds.
Indexes work by maintaining sorted data structures that store column values alongside pointers to their corresponding rows. B-tree index structures, for example, organize data hierarchically, allowing the database to eliminate large portions of irrelevant data with each comparison step. This logarithmic search pattern means that doubling your data size only adds one additional step to the search process.
The performance gains become dramatic with complex queries involving multiple conditions, joins, or sorting operations. Hash index performance excels for exact-match lookups, while specialized structures like inverted index search mechanisms power lightning-fast text retrieval in search engines.
Common Performance Bottlenecks Without Strategic Indexing
Missing or poorly designed indexes create several critical performance issues that compound as your application scales. The most obvious problem is slow SELECT queries that force full table scans across massive datasets.
JOIN operations suffer significantly without proper indexing on foreign key columns. When the database can’t efficiently match records between tables, it resorts to nested loop joins that examine every combination of rows – a process that scales quadratically with table size. A simple two-table join might execute in seconds instead of milliseconds.
Sorting operations become major bottlenecks when ORDER BY clauses can’t leverage existing indexes. The database must load entire result sets into memory, sort them, and then return the ordered results. Large datasets can exhaust available memory, forcing the system to use slower disk-based sorting algorithms.
GROUP BY and aggregate functions face similar challenges without supporting indexes. Statistical queries that should complete instantly instead trigger expensive full table scans followed by in-memory grouping operations.
WHERE clause conditions on unindexed columns create the worst performance scenarios. Range queries, pattern matching, and complex filtering operations degrade severely, often timing out entirely on production datasets.
Write operations can also suffer from missing indexes on frequently queried columns, as the database struggles to maintain referential integrity and execute cascading updates efficiently.
Index Selection Criteria for Different Data Types
Choosing the right index type depends on your data characteristics, query patterns, and performance requirements. Different data types and access patterns benefit from specialized indexing strategies that optimize for specific use cases.
For numeric and date columns with range queries, B-tree indexes provide excellent performance for both equality and range lookups. These structures handle ORDER BY operations efficiently and support partial key searches effectively.
Text data requires more nuanced approaches depending on search requirements. Short strings with exact-match patterns work well with hash indexes, while longer text fields benefit from full-text search optimization using specialized text indexes that handle stemming, ranking, and phrase searches.
Low-cardinality data with few distinct values – like status fields, boolean flags, or category codes – often perform better with bitmap index efficiency techniques. These structures compress well and excel at complex boolean combinations across multiple columns.
High-cardinality text data, especially fields requiring prefix searches like usernames or product codes, benefit from trie data structure implementations that optimize for partial string matching.
Columnar database indexing becomes critical for analytical workloads involving aggregations across large datasets. These specialized indexes optimize for read-heavy operations by storing data column-wise rather than row-wise.
Geospatial database queries require spatial indexes that understand coordinate systems and geometric relationships. Standard B-tree structures can’t efficiently handle location-based range searches or proximity calculations.
Time-series data with heavy write loads often benefit from LSM-tree storage approaches that optimize for sequential writes while maintaining reasonable read performance for recent data access patterns.
B-Tree Indexes: The Backbone of Relational Databases
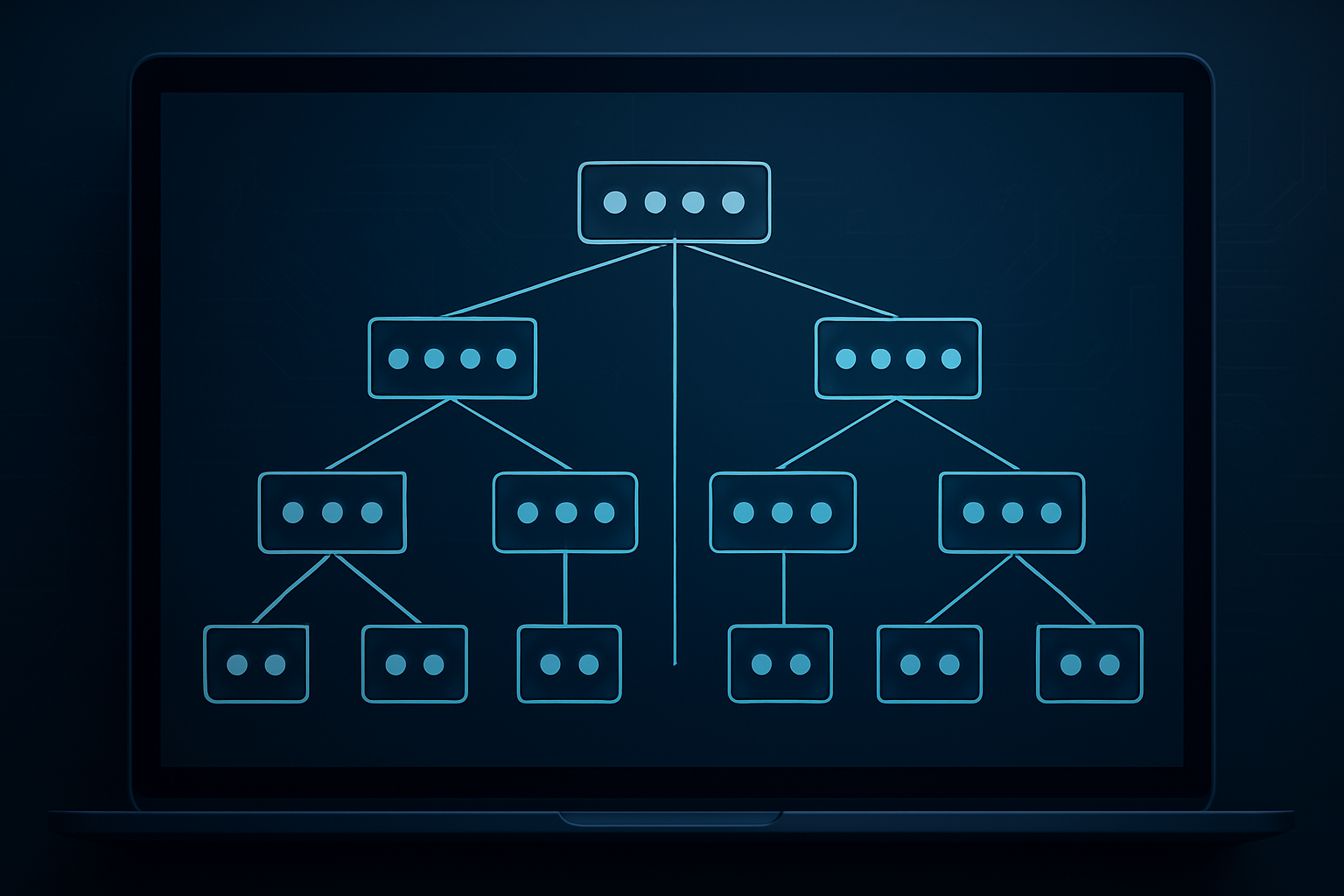
How B-Tree Structure Enables Lightning-Fast Range Queries
The magic of B-tree indexes lies in their perfectly balanced, multi-level structure that keeps data sorted and accessible. Picture a library where books are organized not just alphabetically on shelves, but with a sophisticated card catalog system that guides you directly to any section. That’s exactly how a B-tree index works – each internal node acts as a roadmap, containing key values and pointers that direct the database engine to the right path.
When you execute a range query like “SELECT * FROM orders WHERE order_date BETWEEN ‘2024-01-01’ AND ‘2024-03-31′”, the B-tree index shines. The database engine starts at the root node, compares your search criteria with the stored key values, and follows the appropriate pointer down to the next level. This process continues until it reaches the leaf nodes where actual data pointers reside.
The real power emerges during range scans. Once the engine locates the starting point of your range, it can efficiently traverse the linked leaf nodes horizontally to collect all matching records. Since leaf nodes are connected like a chain, scanning from the start to the end of a range becomes a simple sequential operation. This sequential access pattern at the leaf level, combined with the logarithmic search time to find the starting point, makes range queries incredibly efficient.
B-tree indexes maintain their balanced height automatically through splits and merges, ensuring that the path from root to any leaf remains consistent. This balanced structure guarantees O(log n) performance for both point lookups and range query initiation, making database indexing with B-trees predictably fast regardless of table size.
Optimal Use Cases for Primary and Secondary Key Lookups
B-tree indexes excel as the go-to choice for primary key constraints because they enforce uniqueness while providing lightning-fast access patterns. Every table needs efficient primary key lookups, and B-trees deliver consistent performance whether you’re finding a single customer record or processing thousands of transactions per second. The sorted nature of B-tree storage means primary key searches complete in just a few disk reads, even in tables containing millions of rows.
Secondary indexes benefit tremendously from B-tree structure when queries involve:
- Equality searches on indexed columns: Finding all customers in a specific city
- Range queries: Retrieving orders within date ranges or sales within price brackets
- Sorting operations: ORDER BY clauses leverage existing B-tree sort order
- Prefix matching: Searching for names starting with specific letters
- Join operations: Foreign key lookups become incredibly efficient
B-trees work exceptionally well for columns with high cardinality – think customer IDs, email addresses, or timestamps. These columns have many unique values, allowing the B-tree structure to effectively narrow down search spaces at each level. The index becomes less effective on low-cardinality columns like gender or status flags, where other indexing strategies might prove more suitable.
Composite scenarios also favor B-trees. When your application frequently queries on multiple columns together (like searching by both customer_id and order_date), B-tree indexes can handle these multi-column lookups efficiently, especially when query patterns align with the index column order.
Performance Trade-offs Between Insert Speed and Query Efficiency
Every database administrator faces the classic dilemma: B-tree indexes dramatically speed up queries but slow down write operations. When you insert new records, the database must update not only the table but also maintain the sorted order within the B-tree index structure. This maintenance overhead becomes more pronounced as your index count grows.
Insert performance suffers because:
- Page splits occur: When a leaf node fills up, the database splits it into two nodes, potentially triggering cascading splits up the tree
- Rebalancing operations: The tree must maintain its balanced structure, sometimes requiring multiple node reorganizations
- Lock contention: Multiple transactions inserting similar key ranges can compete for the same index pages
- Increased I/O operations: Each insert might require reading index pages, modifying them, and writing them back to disk
The trade-off becomes more complex with bulk inserts. Loading large datasets into indexed tables can be painfully slow if done record by record. Smart database administrators often drop indexes before bulk loads, then rebuild them afterward – a strategy that can reduce loading time by 80% or more.
Update and delete operations face similar challenges. Updating an indexed column might require moving index entries to maintain sort order. Deletes can create fragmented index pages that gradually degrade performance until maintenance operations clean them up.
However, the query performance gains usually justify these write penalties. A well-designed B-tree index can transform a full table scan taking minutes into a precise lookup completing in milliseconds. Most applications read data far more frequently than they write it, making this trade-off worthwhile for typical workloads.
Best Practices for Composite B-Tree Index Design
Creating effective composite B-tree indexes requires understanding how column order affects query performance. The golden rule is simple: place the most selective columns first, followed by columns used in range conditions, with equality columns taking priority over range columns.
Consider a composite index on (customer_id, order_date, status). This design works perfectly for queries filtering on customer_id first, then optionally narrowing by date ranges or status. However, queries filtering only on order_date or status cannot efficiently use this index because B-trees require left-to-right column usage.
Column selectivity matters enormously. Place highly selective columns (those with many unique values) at the beginning of composite indexes. A column like customer_id with thousands of unique values should come before a status column with only three possible values. This ordering maximizes the index’s ability to eliminate irrelevant data early in the search process.
Query pattern analysis drives optimal design:
- Equality + Range patterns: Structure indexes as (equality_cols, range_col) for queries like “WHERE customer_id = 123 AND order_date BETWEEN …”
- Multiple equality filters: Order columns by selectivity when all conditions use equality operators
- Sorting requirements: Include ORDER BY columns at the end of composite indexes to eliminate separate sort operations
Watch out for index redundancy. Creating indexes on (customer_id) and (customer_id, order_date) provides overlapping functionality – the composite index can handle single-column customer_id queries effectively. However, separate indexes might be necessary when query patterns vary significantly.
Monitor index usage statistics regularly. Modern database systems track how often each index gets used, helping identify candidates for removal or redesign. Unused indexes waste storage space and slow down write operations without providing any query benefits.
Hash Indexes: Ultra-Fast Equality Searches

When Hash Indexes Outperform All Other Index Types
Hash index performance reaches its peak when you need lightning-fast equality searches on unique or high-cardinality data. Picture a user authentication system where you’re constantly looking up users by their unique email addresses – a hash index can locate any record in O(1) time, making it dramatically faster than B-tree indexes for these specific queries.
The sweet spot for hash indexes lies in scenarios with:
- Primary key lookups where you know the exact value
- Session management systems requiring instant user session retrieval
- Cache implementations in high-throughput applications
- Real-time analytics dashboards needing immediate metric calculations
- API rate limiting where you track requests per user or IP address
Hash indexes absolutely dominate when your workload consists primarily of SELECT * WHERE column = 'exact_value' queries. They become less effective when you need range queries, sorting, or partial matches – scenarios where B-tree indexes would be more appropriate.
Memory vs Disk-Based Hash Index Implementation
Memory-based hash indexes store the entire hash table in RAM, providing the fastest possible access times but limiting capacity to available memory. These work exceptionally well for frequently accessed data that fits comfortably in memory, like user sessions or configuration lookups.
Key characteristics of memory-based implementations:
- Sub-millisecond response times for hash table operations
- Limited by RAM capacity – typically suitable for datasets under several gigabytes
- Volatile storage requiring reconstruction after system restarts
- Perfect for hot data that applications access repeatedly
Disk-based hash indexes extend capacity beyond memory limitations but introduce I/O overhead. Modern implementations use sophisticated buffering strategies to minimize disk access while maintaining reasonable performance for larger datasets.
Disk-based implementations feature:
- Larger capacity handling datasets exceeding available RAM
- Persistent storage surviving system restarts without rebuilding
- Higher latency due to disk I/O operations
- Complex buffering strategies to optimize frequently accessed buckets
Collision Handling Strategies That Maintain Performance
Collision handling makes or breaks hash index efficiency. When different keys produce identical hash values, the index needs smart strategies to maintain fast access while preserving data integrity.
Chaining with Linked Lists
The most straightforward approach links colliding entries together. Each hash bucket contains a pointer to the first entry, which then points to subsequent collisions. This method handles any number of collisions gracefully but can degrade to linear search performance in worst-case scenarios.
Open Addressing with Linear Probing
When a collision occurs, the system searches for the next available slot in the hash table. This approach keeps all data in the main table structure, improving cache performance and reducing memory overhead. However, clustering can develop around popular hash values, creating performance hotspots.
Robin Hood Hashing
An advanced open addressing technique that minimizes variance in search times. When inserting a new key, if it would have to probe fewer times than an existing key to reach its preferred position, they swap places. This “stealing from the rich” approach creates more uniform performance across all operations.
Cuckoo Hashing
Provides guaranteed O(1) worst-case lookup time by maintaining two hash tables with different hash functions. If both positions are occupied during insertion, existing elements get moved to their alternate positions in a cascading fashion. While insertions can be more complex, lookups remain consistently fast.
Modern database systems often combine multiple strategies, starting with chaining for simplicity and switching to open addressing when bucket sizes exceed certain thresholds, ensuring optimal performance across varying data distributions.
Inverted Indexes: Power Behind Search Engines

Building Efficient Document-to-Term Mapping Structures
Inverted index search systems work by flipping the traditional document structure on its head. Instead of storing documents that contain terms, they create a master list where each term points to all documents containing it. Picture a massive dictionary where every word shows you exactly which pages mention it across your entire library.
The core architecture revolves around two primary components: the term dictionary and the postings lists. The term dictionary acts as your vocabulary index, storing every unique word from your document collection. Each entry connects to a postings list containing document IDs, term frequencies, and positional information.
Modern implementations use sophisticated data structures to handle this mapping efficiently:
- Hash tables provide O(1) term lookups for exact matches
- Trie structures enable prefix searching and fuzzy matching capabilities
- Sorted arrays optimize range queries and alphabetical browsing
- B+ trees balance memory usage with query performance
Memory management becomes critical when dealing with millions of terms. Smart implementations partition the index across multiple segments, keeping frequently accessed terms in memory while storing less common ones on disk. This tiered approach maintains sub-millisecond response times even with massive vocabularies.
Term normalization plays a crucial role in building effective mappings. Stemming reduces “running,” “runs,” and “ran” to their root form “run,” while case folding ensures “Database” and “database” map to the same entry. These preprocessing steps dramatically improve search recall without sacrificing precision.
Compression Techniques That Reduce Storage Overhead
Raw inverted indexes can consume enormous amounts of storage space, especially when tracking positional information for phrase queries. Smart compression strategies reduce this overhead by 70-90% without sacrificing query performance.
Delta compression transforms absolute document IDs into relative offsets. Instead of storing [1247, 1251, 1289, 1301], the system stores [1247, +4, +38, +12]. Since documents often cluster together for popular terms, these deltas stay small and compress beautifully with variable-byte encoding.
Variable-byte encoding represents another powerful technique. Common document gaps fit into single bytes, while larger gaps use multiple bytes with continuation bits. This approach adapts perfectly to real-world data distributions where some terms appear frequently in clustered documents.
Block-based compression groups postings into fixed-size chunks before applying compression algorithms:
- PFor (Patched Frame of Reference) handles most values with small bit widths, patching exceptions separately
- Simple9 packs multiple integers into 32-bit words using different configurations
- SIMD-optimized codecs leverage modern CPU instructions for parallel decompression
Position information receives special treatment through gap encoding. Instead of storing absolute word positions [5, 7, 12, 18], systems store [5, +2, +5, +6]. Combined with variable-byte encoding, this reduces positional data by 60-80%.
Advanced systems employ dictionary compression for terms themselves. Frequent prefixes and suffixes get factored out, while rare terms might share storage through string interning techniques.
Real-World Applications in Full-Text Search Systems
Search engines represent the most visible application of inverted index search technology, but their usage extends far beyond web crawling. Modern applications leverage these structures across diverse domains requiring fast text retrieval capabilities.
Enterprise search platforms use inverted indexes to power document management systems, enabling employees to locate contracts, reports, and communications instantly. Legal discovery platforms process millions of emails and documents, relying on optimized inverted indexes to support complex boolean queries and proximity searches within tight deadlines.
E-commerce sites depend heavily on product search functionality. When customers search for “wireless bluetooth headphones,” the inverted index quickly identifies matching products by intersecting postings lists for each term. Advanced implementations support faceted search, allowing users to filter by brand, price range, and features simultaneously.
Code search platforms like GitHub’s search functionality demonstrate inverted indexes handling structured text. These systems index variable names, function signatures, and comments while preserving code syntax relationships. Developers can search across millions of repositories using natural language queries or specific programming constructs.
Log analysis systems process massive volumes of server logs, error messages, and application traces. Inverted indexes enable rapid filtering and correlation of events across distributed systems. Security teams use these capabilities to detect patterns and investigate incidents across petabytes of log data.
Social media platforms apply inverted indexes to hashtag searches, user-generated content, and real-time trend detection. The challenge lies in maintaining index freshness while handling millions of new posts per minute.
Optimizing Inverted Indexes for High-Volume Updates
Traditional inverted indexes excel at read-heavy workloads but struggle with frequent updates. Adding new documents requires rebuilding postings lists, while deletions create fragmentation issues. Modern systems employ several strategies to handle high-volume updates gracefully.
Merge-based approaches maintain multiple index segments, each optimized for different update patterns. New documents go into small, frequently-updated segments stored in memory or fast storage. Background processes periodically merge these segments with larger, read-optimized segments on disk. This design separates write optimization from read performance.
Log-structured updates treat index changes as append-only operations. Instead of modifying existing postings lists, systems write new entries to a log structure. Query processors merge results from multiple log segments during search time. This approach works particularly well for time-series data where recent documents receive more query traffic.
Delta indexing maintains a compact representation of recent changes separate from the main index. Updates go into the delta structure, which gets merged with query results at search time. Periodic consolidation processes fold delta changes into the main index during low-traffic periods.
Distributed indexing spreads the update load across multiple machines. Sharding strategies partition documents by hash, time range, or content type. Each shard maintains its own inverted index, allowing parallel updates while query coordinators merge results from relevant shards.
Real-time systems often employ hybrid architectures combining multiple approaches:
- Hot tier handles recent updates with fast, memory-based structures
- Warm tier stores moderately active data with balanced read-write performance
- Cold tier optimizes for storage efficiency and read performance
Background optimization processes continuously rewrite index segments to maintain query performance. These operations run during off-peak hours, ensuring user-facing search latency remains consistent despite heavy update activity.
Full-Text Indexes: Advanced Text Search Capabilities

Stemming and Tokenization for Improved Search Accuracy
Full-text search optimization begins with preprocessing text data through tokenization and stemming. Tokenization breaks down text into individual words or meaningful units, handling punctuation, whitespace, and special characters. Modern full-text indexes employ sophisticated tokenizers that recognize different data types, from standard words to URLs, email addresses, and numeric values.
Stemming reduces words to their root forms, allowing searches for “running” to match documents containing “run,” “runs,” or “runner.” This process dramatically improves search recall by normalizing variations of the same concept. Advanced systems use lemmatization, which considers word context and part-of-speech tagging for more accurate root word identification.
Key tokenization features include:
- Case normalization for consistent matching
- Stop word filtering to remove common words like “the” and “and”
- Custom delimiters for domain-specific content
- N-gram generation for partial word matching
Database systems like PostgreSQL and MySQL implement configurable text parsers that handle these preprocessing steps automatically, creating inverted indexes that map each processed term to documents containing it.
Ranking Algorithms That Deliver Relevant Results
Effective full-text indexes don’t just find matching documents—they rank results by relevance. The TF-IDF (Term Frequency-Inverse Document Frequency) algorithm forms the foundation of most ranking systems, weighing how often terms appear in documents against their rarity across the entire collection.
TF-IDF calculation considers:
- Term frequency: How often a word appears in a document
- Document frequency: How many documents contain the term
- Document length normalization: Preventing longer documents from dominating results
Modern databases extend basic TF-IDF with additional ranking factors:
BM25 (Best Matching 25) improves upon TF-IDF by adding term saturation, preventing diminishing returns as term frequency increases. This algorithm handles repeated keywords more naturally, avoiding spam-like keyword stuffing effects.
Proximity scoring rewards documents where search terms appear close together, recognizing that nearby terms often indicate stronger semantic relationships. Field weighting allows different document sections (titles, headings, body text) to contribute differently to relevance scores.
Many database systems integrate machine learning models that learn from user behavior, adjusting rankings based on click-through rates and user satisfaction metrics.
Multi-Language Support and Character Set Considerations
Global applications require full-text indexes that handle diverse languages and character encodings. Unicode support is essential, but proper multi-language indexing goes far beyond basic character storage.
Language-specific challenges include:
- Character normalization for languages with multiple representations (like Japanese hiragana/katakana)
- Script direction handling for right-to-left languages like Arabic and Hebrew
- Compound word segmentation for languages like German that create long composite words
- Ideographic tokenization for Chinese, Japanese, and Korean text that lacks clear word boundaries
Database systems implement pluggable analyzers for different languages. These analyzers understand language-specific rules for word boundaries, stemming algorithms, and stop words. For example, English stemmers handle irregular verbs differently than German stemmers manage compound nouns.
Collation rules affect sorting and matching behavior, determining whether searches are case-sensitive and how accented characters compare. UTF-8 encoding provides broad character support, but proper collation ensures culturally appropriate search behavior.
Advanced implementations support:
- Mixed-language documents with automatic language detection
- Transliteration for cross-script searching
- Phonetic matching for names and proper nouns
- Cultural sorting preferences that vary by region
Modern full-text indexes leverage these capabilities to provide seamless search experiences across global user bases, automatically adapting to user language preferences and content characteristics.
Geospatial Indexes: Location-Based Query Optimization
Spatial Data Structures for Geographic Information Systems
Geospatial database queries rely on specialized data structures that handle multi-dimensional spatial relationships efficiently. Traditional indexing methods fall short when dealing with location-based data, which requires understanding concepts like distance, containment, and spatial overlap.
The foundation of geospatial indexing lies in partitioning space into manageable segments. Quad-trees divide two-dimensional space into four quadrants recursively, creating a hierarchical structure perfect for point-based location data. Grid-based indexing systems overlay a uniform grid pattern across geographic regions, assigning spatial objects to specific grid cells for rapid retrieval.
Space-filling curves like Z-order (Morton) curves transform multi-dimensional spatial data into single-dimensional sequences while preserving spatial locality. This approach enables standard B-tree indexes to handle geographic data by converting latitude-longitude coordinates into linear values that maintain spatial relationships.
Bounding rectangles (MBRs) represent complex geographic shapes using simple rectangular boundaries, dramatically reducing computational complexity during spatial queries. These rectangles serve as initial filters, allowing databases to quickly eliminate irrelevant data before performing detailed geometric calculations on remaining candidates.
R-Tree Implementation for Efficient Proximity Searches
R-trees represent the gold standard for geospatial database indexing, specifically designed to handle rectangular regions in multi-dimensional space. Unlike traditional indexes that work with single values, R-trees organize spatial data using minimum bounding rectangles that encompass geographic objects.
The tree structure groups nearby objects together at each level, creating a hierarchy where parent nodes contain bounding rectangles that encompass all child rectangles. This design enables efficient range queries, nearest neighbor searches, and spatial joins that would be computationally expensive with traditional indexing methods.
R-tree variants address specific use cases and performance requirements:
- R+ trees eliminate overlapping rectangles by duplicating objects across multiple nodes, reducing search ambiguity
- R trees* optimize node splitting algorithms to minimize overlap and coverage area
- Hilbert R-trees use space-filling curves to improve clustering and reduce storage requirements
Query processing in R-trees follows a systematic approach. Range queries traverse the tree by checking each node’s bounding rectangle against the query region, recursively exploring only branches that intersect the target area. Nearest neighbor searches employ priority queues to explore promising branches first, pruning distant subtrees based on current best distance estimates.
Performance Tuning for Large-Scale Mapping Applications
Large-scale mapping applications demand aggressive optimization strategies to handle millions of geographic objects while maintaining sub-second query response times. Memory management becomes critical as R-tree nodes must remain accessible for rapid traversal during complex spatial operations.
Buffer pool configuration directly impacts performance, with optimal settings allocating 60-70% of available memory to index caches. Spatial data exhibits strong locality patterns, making LRU replacement policies particularly effective for maintaining hot index pages in memory.
Node capacity tuning balances tree height against node utilization. Larger node capacities reduce tree depth but increase memory requirements per node access. Most production systems achieve optimal performance with node capacities between 50-100 entries, depending on average object complexity and query patterns.
Bulk loading techniques dramatically improve index creation times for large datasets. Rather than inserting objects individually, bulk loading algorithms sort spatial objects using space-filling curves, then construct R-tree levels bottom-up. This approach reduces index creation time from hours to minutes for million-record datasets while producing more balanced tree structures.
Partitioning strategies distribute geospatial data across multiple index structures based on geographic regions or zoom levels. Tile-based partitioning aligns with web mapping standards, allowing applications to load only relevant geographic areas. Level-of-detail indexing maintains separate indexes for different resolution levels, serving appropriate detail based on map zoom factors.
Integration with Popular GIS Frameworks
Modern GIS frameworks provide robust geospatial database indexing capabilities through standardized interfaces and optimized implementations. PostGIS extends PostgreSQL with comprehensive spatial indexing using GiST (Generalized Search Tree) indexes that support R-tree operations alongside other spatial access methods.
PostGIS spatial indexes handle diverse geometry types including points, linestrings, polygons, and multi-part geometries. The framework automatically selects appropriate indexing strategies based on data characteristics and query patterns. Spatial operator classes enable specialized indexing for specific use cases like network analysis or raster data processing.
MongoDB’s geospatial features support both 2D and 2dsphere indexes for location-based queries. The 2D index works with flat coordinate systems, while 2dsphere handles spherical geometry calculations required for earth-surface coordinates. These indexes integrate seamlessly with aggregation pipelines, enabling complex analytical queries combining spatial and non-spatial criteria.
Elasticsearch provides geo-point and geo-shape data types with corresponding spatial indexes. The platform’s distributed architecture automatically partitions geospatial data across cluster nodes while maintaining query performance. Geohash-based indexing enables efficient proximity searches and supports real-time applications like location tracking and geofencing.
Oracle Spatial and Graph delivers enterprise-grade geospatial indexing through R-tree implementations optimized for high-volume transactional systems. The platform supports complex spatial operations including topology validation, spatial joins, and geometric transformations while maintaining ACID compliance across spatial transactions.
LSM-Tree Indexes: Write-Optimized Storage Solutions

How Log-Structured Merge Trees Handle High Write Volumes
LSM-tree storage systems excel at managing massive write workloads by fundamentally changing how data gets written and organized. Unlike traditional B-tree indexes that update data in place, LSM-trees append all new data to a sequential log structure, creating an immutable record of changes.
When applications need to write data, LSM-trees first store it in an in-memory component called a memtable. This memory-resident structure can handle thousands of writes per second because it doesn’t require disk I/O for each operation. Once the memtable reaches capacity, the system flushes it to disk as an immutable SSTable (Sorted String Table).
The magic happens through this multi-level architecture:
- Level 0: Recently flushed SSTables from memory
- Level 1+: Larger, merged SSTables with overlapping key ranges minimized
- Bloom filters: Probabilistic data structures that quickly eliminate unnecessary disk reads
This design transforms random write patterns into sequential writes, dramatically reducing write amplification. Traditional databases might perform multiple disk seeks for a single update, while LSM-tree storage writes data once sequentially and handles organization later through background processes.
The append-only nature means writes never block on disk seeks or lock contention. Multiple threads can write simultaneously to different memtables, scaling write throughput linearly with available memory and CPU cores.
Compaction Strategies That Balance Performance and Storage
Compaction represents the heart of LSM-tree performance optimization. This background process merges smaller SSTables into larger ones, removing duplicate entries and maintaining query efficiency. Different compaction strategies offer distinct trade-offs between read performance, write amplification, and space overhead.
Size-tiered compaction triggers when several SSTables of similar size accumulate at a level. The system merges them into a single larger table at the next level. This approach works well for write-heavy workloads but can create temporary space overhead during merges.
Leveled compaction maintains strict size limits at each level, with each level being roughly 10x larger than the previous. When a level exceeds its threshold, the system selects one SSTable and merges it with overlapping tables at the next level. This strategy provides more predictable read performance but generates higher write amplification.
Hybrid approaches combine both strategies, using size-tiered for the first few levels and switching to leveled compaction for larger levels. This balances the benefits of both approaches while minimizing their drawbacks.
Key compaction considerations include:
- Tombstone handling: Efficiently removing deleted data during merges
- Bloom filter regeneration: Updating probabilistic filters for merged data
- Throttling mechanisms: Preventing compaction from overwhelming system resources
- Parallel compaction: Running multiple merge operations simultaneously
Smart compaction scheduling prevents read performance degradation while maintaining write throughput during peak loads.
Ideal Scenarios for Time-Series and Analytics Workloads
LSM-tree storage shines brightest in scenarios where write volume significantly exceeds read frequency. Time-series databases represent the perfect use case, handling millions of sensor readings, log entries, or metric data points per second.
Time-series applications benefit from LSM-trees because:
- Data arrives chronologically, matching the append-only write pattern
- Queries typically focus on recent time ranges, leveraging temporal locality
- Historical data rarely gets updated, eliminating write amplification from modifications
- Compression works exceptionally well on sorted, time-ordered data
Analytics workloads also see substantial benefits:
- ETL processes can stream large data volumes without write bottlenecks
- Column families allow efficient storage of different data types
- Range queries perform well due to sorted SSTable organization
- Batch processing frameworks integrate seamlessly with LSM-tree architectures
IoT and monitoring systems leverage LSM-tree advantages for:
- High-frequency sensor data ingestion
- Log aggregation from distributed systems
- Real-time alerting based on recent data patterns
- Long-term trend analysis with historical data retention
The key success factor lies in understanding access patterns. Applications with heavy writes, infrequent updates, and time-based query patterns will see dramatic performance improvements. However, workloads requiring frequent random updates or complex transactional consistency might benefit more from traditional B-tree indexes.
Modern distributed systems like Apache Cassandra, HBase, and RocksDB have proven LSM-tree effectiveness at scale, handling petabytes of data across thousands of nodes while maintaining consistent write performance.
Bitmap Indexes: Efficient Low-Cardinality Data Processing

When Bitmap Compression Delivers Maximum Space Savings
Bitmap indexes shine brightest when dealing with low-cardinality columns where the number of distinct values stays relatively small. Think gender, marital status, product categories, or order statuses—columns that might have anywhere from two to a few hundred unique values. Database indexing becomes incredibly space-efficient in these scenarios because bitmap compression algorithms work their magic.
The compression happens through run-length encoding (RLE), which identifies consecutive sequences of identical bits and stores them as a count rather than individual bits. For example, if you have 10,000 male customers followed by 5,000 female customers, instead of storing 15,000 individual bits, the system stores just two values: “10,000 ones” and “5,000 zeros.”
Oracle’s bitmap index efficiency really stands out when dealing with columns where most values cluster together. Sales regions, product lines, or employee departments create natural groupings that compress beautifully. The space savings can reach 90% or more compared to traditional B-tree indexes, especially when the data gets sorted by the indexed column.
However, bitmap indexes become storage nightmares with high-cardinality data like customer IDs or timestamps. Each unique value requires its own bitmap, and with millions of distinct values, you end up with sparse bitmaps that compress poorly and consume massive storage.
Boolean Operations That Accelerate Complex Queries
Bitmap indexes excel at handling complex WHERE clauses with multiple conditions because they use bitwise operations that computers process at lightning speed. When you need customers who are male AND live in California AND have premium status, the database performs simple AND operations between three bitmaps rather than scanning through multiple separate indexes.
The magic happens at the bit level. Each bitmap represents one value of a column, and combining them requires basic Boolean algebra:
- AND operations find intersections (customers meeting ALL criteria)
- OR operations find unions (customers meeting ANY criteria)
- NOT operations find exclusions (customers NOT meeting specific criteria)
- XOR operations find exclusive conditions
These bitwise operations run incredibly fast because modern CPUs handle them in parallel across multiple bits simultaneously. A query checking five different conditions might complete in milliseconds rather than seconds, making bitmap indexes perfect for analytical workloads with complex filtering requirements.
Data warehouses love this approach because business analysts frequently write queries like “Show me sales for premium customers in the West region who bought electronics last quarter.” Each condition translates to a bitmap, and the final result emerges from combining them with Boolean operations.
OLAP and Data Warehouse Performance Optimization
OLAP systems and data warehouses represent the sweet spot for bitmap index efficiency because they handle massive datasets with predictable query patterns. Unlike transactional systems where users insert and update records constantly, analytical systems focus on reading data and generating reports.
Bitmap indexes accelerate star schema queries where fact tables connect to dimension tables through foreign keys. Product categories, time periods, geographic regions, and customer segments all become perfect candidates for bitmap indexing. When analysts slice and dice data across multiple dimensions, bitmap indexes deliver the performance boost that makes interactive analysis possible.
The read-heavy nature of OLAP workloads aligns perfectly with bitmap indexes’ strengths. These indexes struggle with frequent updates because changing a single row might require updating multiple bitmaps, but analytical systems typically load data in batches during off-hours, then serve read-only queries during business hours.
Columnar database indexing often combines with bitmap techniques to create powerhouse analytical engines. Systems like Amazon Redshift and Google BigQuery use bitmap-style indexing alongside columnar storage to scan billions of rows in seconds. The combination works because analytical queries typically touch many rows but only a few columns, making both storage formats complementary.
Query response times that once took minutes now complete in seconds, transforming how business users interact with their data and enabling real-time decision making across organizations.
Trie Indexes: Prefix-Based Search Excellence

Auto-Complete and Suggestion System Implementation
Trie data structure indexes excel at powering auto-complete and suggestion systems that users encounter daily. When you type in a search box and see instant suggestions, there’s likely a trie index working behind the scenes. These indexes store strings in a tree-like structure where each node represents a character, creating efficient paths to complete words.
The magic happens through prefix matching. As users type each character, the trie index quickly traverses down the appropriate path, gathering all possible completions from that point. Modern implementations use compressed tries (also called radix trees) that merge single-child nodes, dramatically reducing memory usage while maintaining lightning-fast lookups.
Popular applications include:
- Search engine query suggestions
- Email address auto-completion
- Product search on e-commerce sites
- IDE code completion features
- Social media username suggestions
The key advantage lies in the O(k) time complexity for insertions and searches, where k represents the length of the string rather than the total number of stored strings. This means performance stays consistent even with millions of entries.
Memory-Efficient Storage for Large Vocabulary Sets
Trie indexes shine when handling massive vocabulary sets while keeping memory usage reasonable. Traditional hash-based approaches might store each complete string separately, leading to significant memory overhead from duplicate prefixes. Trie indexes eliminate this redundancy by sharing common prefixes across multiple entries.
Consider a dictionary with words like “car,” “card,” “care,” and “careful.” Instead of storing these four complete strings, a trie index stores the shared prefix “car” once, then branches out for the unique suffixes. This prefix compression becomes more powerful with larger datasets.
Advanced memory optimization techniques include:
- Minimal perfect hashing for leaf nodes
- Suffix linking to reduce traversal overhead
- Alphabet reduction for specialized character sets
- Node compression using bit manipulation
Modern implementations can achieve 40-60% memory savings compared to traditional string storage methods. Database systems leverage these savings when indexing large text columns, making trie indexes particularly valuable for applications dealing with genetic sequences, log files, or multilingual content.
String Matching Performance in Real-Time Applications
Real-time applications demand consistent, predictable performance for string matching operations. Trie indexes deliver exactly this through their balanced tree structure and deterministic traversal patterns. Unlike hash indexes that might encounter collision chains, trie indexes provide guaranteed performance bounds.
The performance characteristics make them ideal for:
- Real-time fraud detection systems matching transaction patterns
- Network security applications filtering malicious URLs
- Gaming platforms validating usernames and chat messages
- IoT device management matching device identifiers
- Log analysis systems parsing structured text data
Trie indexes handle concurrent read operations exceptionally well, making them perfect for high-throughput scenarios. The tree structure allows multiple threads to traverse different branches simultaneously without conflicts. This parallelization capability becomes crucial when processing thousands of string matching requests per second.
Performance optimization strategies include maintaining hot paths in cache, using memory pooling for node allocation, and implementing lock-free traversal algorithms. These optimizations help trie indexes maintain sub-millisecond response times even under heavy load conditions.
The predictable memory access patterns also play well with modern CPU caching systems, providing additional performance benefits that compound with scale.
Column Indexes: Analytical Query Performance Boosters

Columnar Storage Benefits for Aggregation Operations
Columnar database indexing transforms how analytical workloads process large datasets by organizing data column-wise rather than row-wise. This storage approach excels at aggregation operations like SUM, COUNT, AVG, and GROUP BY queries because it only reads the specific columns needed for the calculation. When running a query to find average sales by region, traditional row-based systems must scan entire rows even though only two columns are relevant. Column indexes eliminate this waste by storing each column as a separate data structure.
The magic happens when databases perform vector operations on columns. Modern CPUs can process multiple values simultaneously through SIMD (Single Instruction, Multiple Data) operations, dramatically accelerating calculations across thousands or millions of records. Column indexes also reduce I/O bottlenecks since queries access only necessary data, minimizing disk reads and memory usage.
Analytical queries typically scan large portions of tables, making column indexes perfect for data warehousing scenarios. Star schema designs particularly benefit from columnar indexing because fact table aggregations frequently involve only a subset of available dimensions and measures.
Compression Techniques Specific to Column-Oriented Data
Column-oriented storage unlocks powerful compression opportunities unavailable in row-based systems. Since columns contain homogeneous data types with similar patterns, compression algorithms achieve much higher ratios. Run-length encoding compresses sequences of identical values into count-value pairs, particularly effective for sorted columns or low-cardinality data.
Dictionary compression maps repeating values to smaller numeric identifiers, storing the mapping separately. A column containing millions of city names might compress to integers referencing a dictionary of unique cities. This technique often achieves 10:1 or better compression ratios while maintaining query performance.
Delta encoding stores differences between consecutive values rather than absolute values, working exceptionally well with timestamps, sequential IDs, or sorted numeric data. Bit-packing optimizes storage for integers that don’t require full word sizes, automatically selecting the minimum bits needed to represent column values.
Modern columnar systems combine multiple compression techniques. Parquet files might use dictionary encoding for strings, delta encoding for timestamps, and bit-packing for integers – all within the same dataset. These compressed columns remain query-ready without full decompression, enabling direct operations on compressed data.
When Column Indexes Outperform Traditional Row-Based Approaches
Column indexes deliver superior performance when queries exhibit specific patterns common in analytical workloads. Wide tables with many columns see dramatic improvements when queries only access a few columns. OLAP (Online Analytical Processing) systems routinely query 5-10 columns from tables containing 50-200 columns, making columnar storage ideal.
Aggregation-heavy workloads benefit immensely from column indexes. Business intelligence dashboards, reporting systems, and data analytics platforms frequently execute queries that sum sales figures, count transactions, or calculate averages across filtered datasets. These operations process millions of rows but only need specific columns, perfectly matching columnar strengths.
Range queries on sorted columns perform exceptionally well with column indexes. Finding all transactions between specific dates becomes lightning-fast when timestamp columns are stored separately and potentially pre-sorted. Similarly, filtering operations (WHERE clauses) that evaluate single columns see major performance gains.
However, column indexes struggle with transactional workloads requiring full row retrieval. OLTP (Online Transaction Processing) systems that frequently INSERT, UPDATE, or SELECT complete rows perform better with traditional row-based storage. Mixed workloads often adopt hybrid approaches, maintaining both storage formats for optimal performance across use cases.
Implementation Considerations for Hybrid Storage Systems
Hybrid storage systems combine row-based and columnar indexing to support diverse workload patterns. These architectures require careful planning to balance performance, storage costs, and maintenance complexity. Hot data frequently accessed for transactions might remain in row-based storage, while historical data transitions to columnar format for analytical processing.
Data partitioning strategies become critical in hybrid systems. Time-based partitioning works well for many business scenarios – recent data stays row-oriented for operational queries while older data moves to columnar storage for reporting. Geographic or categorical partitioning might suit other use cases, with different storage formats optimized for regional access patterns.
Synchronization mechanisms ensure data consistency between storage formats. Change data capture (CDC) processes can replicate transactional updates to columnar replicas, though this introduces latency. Some systems maintain near real-time synchronization while others accept periodic batch updates based on business requirements.
Query optimizers in hybrid systems must intelligently route queries to appropriate storage formats. Cost-based optimizers evaluate query patterns, data freshness requirements, and storage characteristics to select optimal execution paths. Advanced systems might split single queries across both storage types, joining results transparently.
Memory management becomes more complex with hybrid approaches. Column stores often require different buffer pool strategies compared to row stores, and systems must balance memory allocation between competing storage formats while maintaining overall performance targets.

Database indexing might seem complex at first, but each type serves a specific purpose that can dramatically improve your application’s performance. B-Tree indexes handle most general queries efficiently, while hash indexes excel at exact matches. When you need text search capabilities, full-text and inverted indexes become your best friends. For location-based apps, geospatial indexes are essential, and if you’re dealing with heavy write workloads, LSM-Tree indexes can save the day.
The key is matching the right index type to your specific use case. Don’t just stick with the default options your database offers. Take time to analyze your query patterns and data characteristics. Whether you’re building a search engine that needs inverted indexes, an analytics platform that benefits from column indexes, or a mapping application requiring geospatial indexes, choosing the right indexing strategy will make the difference between a slow, frustrating user experience and a lightning-fast application that users love.









