







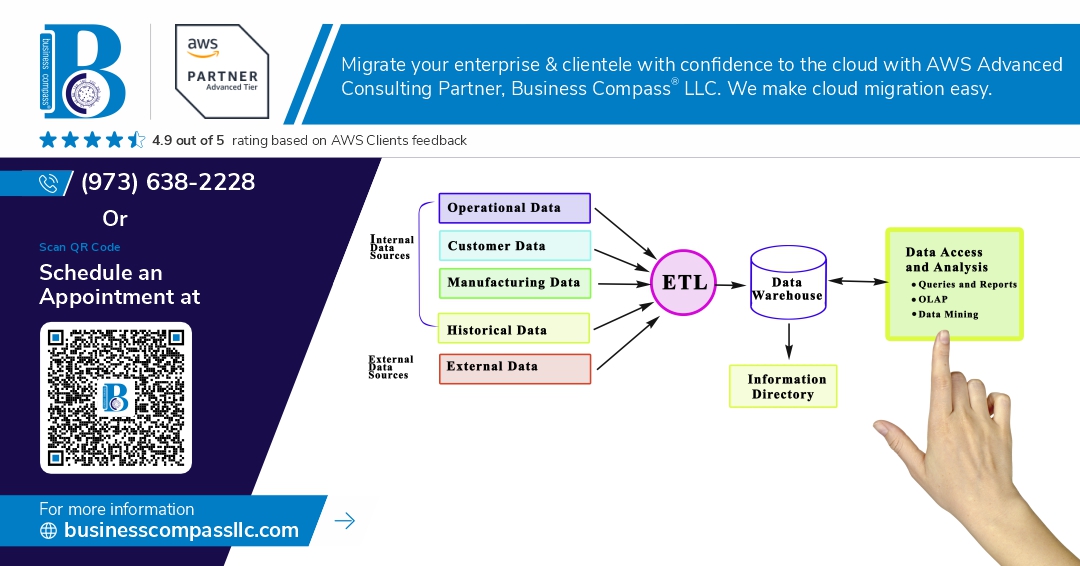
Building robust AWS Glue ETL pipeline systems that can handle enterprise-scale data processing requires more than just basic setup knowledge. This guide targets data engineers, DevOps professionals, and technical architects who need to create production grade ETL AWS solutions that won’t break under pressure.
You’ll learn how to design scalable ETL job architecture that grows with your data volume, set up AWS data catalog management systems that keep your metadata organized, and implement comprehensive ETL pipeline monitoring AWS strategies that catch issues before they impact your business.
We’ll also dive deep into AWS Glue security compliance requirements and show you proven troubleshooting techniques that seasoned engineers use to keep their production ETL troubleshooting workflows running smoothly, even when dealing with terabytes of data daily.
Understanding AWS Glue for Enterprise Data Processing
Core components and architecture overview
AWS Glue operates as a fully managed extract, transform, and load (ETL) service built on Apache Spark’s distributed computing framework. The architecture centers around four essential components: the Data Catalog that serves as a centralized metadata repository, ETL Jobs that execute your data transformation logic, Crawlers that automatically discover and catalog data schemas, and Development Endpoints for interactive development. The Data Catalog acts as the brain of your AWS Glue ETL pipeline, storing table definitions, schema information, and partition details across your data lake. ETL Jobs run as serverless Spark applications, automatically provisioning the compute resources needed for your workloads. Crawlers scan your data stores and populate the catalog with discovered schemas, while Development Endpoints provide Jupyter notebook environments for testing and refining transformation logic before production deployment.
Key advantages over traditional ETL tools
Traditional ETL tools require significant infrastructure investment and ongoing maintenance overhead that AWS Glue eliminates through its serverless architecture. Unlike legacy solutions that demand dedicated servers, licensing costs, and manual scaling configurations, AWS Glue automatically provisions resources based on workload demands. The service removes the complexity of managing Spark clusters, handling software updates, and configuring high availability setups. Development cycles accelerate dramatically since teams can focus on business logic rather than infrastructure management. The visual ETL editor allows analysts without deep programming skills to build sophisticated data pipelines, democratizing data engineering across organizations. Built-in job bookmarking prevents duplicate processing during incremental loads, while automatic schema evolution adapts to changing data structures without manual intervention. These capabilities transform months-long traditional ETL implementations into week-long AWS Glue deployments.
Cost-effectiveness and scalability benefits
The pay-per-use pricing model of AWS Glue delivers substantial cost savings compared to traditional ETL infrastructure investments. Organizations only pay for the Data Processing Units (DPUs) consumed during job execution, eliminating idle resource costs that plague on-premises solutions. Automatic scaling adjusts compute capacity based on data volume fluctuations, ensuring optimal resource allocation during peak and off-peak periods. The service scales horizontally across hundreds of nodes when processing large datasets, then scales down to zero when jobs complete. This elasticity proves particularly valuable for organizations with seasonal data processing patterns or unpredictable workload spikes. Development endpoints support cost-conscious experimentation since teams can spin up interactive environments only when needed. The absence of upfront licensing fees and hardware investments allows companies to redirect capital toward revenue-generating initiatives rather than infrastructure maintenance.
Integration capabilities with AWS ecosystem
AWS Glue seamlessly connects with over 70 AWS data services, creating a comprehensive production-grade ETL AWS environment. Native integration with Amazon S3, Redshift, RDS, and DynamoDB eliminates complex connector configurations required by third-party tools. The service automatically discovers data in Amazon S3 data lakes and relational databases, populating the Data Catalog with schema information. Integration with AWS Lake Formation enables fine-grained access controls and data governance policies across your entire data ecosystem. CloudWatch integration provides comprehensive monitoring and alerting capabilities for production ETL troubleshooting scenarios. AWS Step Functions orchestrate complex multi-step workflows that combine Glue jobs with other AWS services. The service works natively with Amazon EMR for advanced analytics workloads and integrates with SageMaker for machine learning pipelines, creating end-to-end data processing solutions within the AWS ecosystem.
Setting Up Your Production Environment
IAM Roles and Security Configurations
Configure IAM roles with minimum required permissions for AWS Glue ETL pipeline operations. Create service roles with access to S3 buckets, data catalog metadata, and CloudWatch logging. Implement cross-account access patterns using role assumptions. Enable resource-based policies for granular data access control. Use IAM conditions to restrict operations by time, source IP, or encryption status. Attach managed policies like AWSGlueServiceRole and customize inline policies for specific data sources.
VPC and Network Setup Requirements
Deploy production grade ETL AWS infrastructure within private VPC subnets to isolate data processing workloads. Configure NAT gateways for secure internet access and VPC endpoints for AWS services like S3 and DynamoDB. Establish dedicated network connections using AWS Direct Connect or VPN for hybrid cloud architectures. Set security groups with restrictive inbound rules and controlled outbound traffic. Enable VPC Flow Logs for network monitoring and compliance auditing.
Resource Allocation and Performance Optimization
Right-size Glue job configurations based on data volume and processing complexity. Start with 10 DPU (Data Processing Units) for standard workloads and scale up for large datasets. Enable auto-scaling for variable workloads and set maximum capacity limits to control costs. Configure job bookmarks to prevent duplicate processing and optimize incremental data loads. Use columnar formats like Parquet with compression algorithms. Partition data strategically by date or business dimensions. Monitor CloudWatch metrics for job duration, DPU utilization, and data shuffle operations to identify bottlenecks.
Building Robust Data Catalogs and Schemas
Automated Data Discovery and Cataloging
AWS Glue crawlers automatically scan your data sources to build a comprehensive data catalog, eliminating manual schema definition. Configure crawlers to run on schedules or trigger them based on S3 events for real-time catalog updates. Use classifier rules to handle complex file formats and partition structures. Enable incremental crawling to process only new or changed data, reducing processing time and costs. Set up multiple crawlers for different data sources with appropriate IAM roles to maintain security boundaries.
Schema Evolution and Version Management
Schema evolution in production AWS Glue ETL pipelines requires careful planning to handle changing data structures without breaking downstream processes. Implement backward-compatible schema changes using Glue’s schema registry integration with Amazon MSK or Kinesis Data Streams. Create schema versioning strategies that support both schema-on-read and schema-on-write approaches. Use Glue’s DynamicFrame transformations to handle schema drift gracefully, allowing your ETL jobs to adapt to new fields or data types automatically.
Data Quality Validation Frameworks
Build comprehensive data quality checks directly into your AWS Glue enterprise data processing workflows using DeeQu integration or custom validation logic. Implement row-level and aggregate-level validations to catch data anomalies early in the pipeline. Create configurable quality rules that can be adjusted without code changes, storing validation results in CloudWatch metrics for monitoring. Set up automated alerts when quality thresholds are breached, enabling rapid response to data issues before they impact downstream analytics.
Metadata Management Best Practices
Establish consistent naming conventions and tagging strategies across your AWS data catalog management infrastructure. Use Glue’s table properties and column comments to document business context and data lineage information. Implement automated metadata enrichment processes that add classification tags, sensitivity labels, and data owner information. Create governance workflows that require approval for schema changes in production environments. Maintain metadata version history to support audit requirements and enable rollback capabilities when needed.
Designing Scalable ETL Job Architectures
Job scheduling and dependency management
Orchestrating complex AWS Glue ETL pipeline workflows requires robust scheduling frameworks that handle intricate job dependencies. AWS Step Functions integrates seamlessly with Glue jobs, creating visual workflows that automatically trigger downstream processes based on completion status. Amazon EventBridge enables event-driven architectures where data arrival events kick off processing chains. Native Glue workflows provide built-in dependency management, allowing jobs to wait for specific conditions before execution. Apache Airflow on Amazon MWAA offers advanced scheduling capabilities with rich dependency graphs, backfill operations, and conditional logic. Smart scheduling strategies include time-based triggers for batch processing, file-based triggers for real-time data ingestion, and cross-region coordination for global data pipelines.
Error handling and retry mechanisms
Production-grade ETL systems demand sophisticated error recovery strategies that prevent data loss and maintain pipeline reliability. Implementing exponential backoff retry policies helps manage transient failures in distributed environments. Dead letter queues capture failed records for manual inspection and reprocessing. Circuit breaker patterns prevent cascading failures by temporarily halting problematic job segments. Graceful degradation strategies allow pipelines to continue processing valid data while quarantining corrupted records. Custom exception handling in PySpark and Scala jobs enables granular error classification and recovery actions. Checkpoint mechanisms save intermediate processing states, enabling jobs to resume from failure points rather than restarting completely. Alert systems notify operations teams of critical failures requiring immediate attention.
Resource allocation strategies for large datasets
Optimizing AWS Glue resource allocation directly impacts both performance and cost efficiency for enterprise-scale data processing. Dynamic scaling adjusts worker instances based on input data volume and processing complexity. Memory-optimized instances handle wide datasets with numerous columns, while compute-optimized instances accelerate CPU-intensive transformations. Partitioning strategies distribute processing loads evenly across workers, preventing bottlenecks on specific nodes. Connection limits and database pooling prevent overwhelming source systems during extraction phases. Storage optimization techniques include columnar formats like Parquet for analytical workloads and appropriate compression algorithms for network transfer efficiency. Resource tagging enables cost allocation and chargeback mechanisms across different business units and projects.
Monitoring and logging implementation
Comprehensive observability ensures production ETL pipelines maintain high availability and performance standards. CloudWatch metrics track job duration, data volume processed, error rates, and resource utilization patterns. Custom metrics provide business-specific insights like data quality scores and processing latencies. Structured logging using JSON formats enables efficient log analysis and troubleshooting. Distributed tracing follows data lineage across multiple processing stages and external system interactions. Real-time dashboards display pipeline health status and performance trends. Automated alerting rules trigger notifications when jobs exceed expected runtime or fail repeatedly. Log aggregation services centralize logs from multiple Glue jobs for correlation analysis and root cause investigation.
Performance tuning techniques
Achieving optimal performance in scalable ETL job architecture requires systematic optimization across multiple dimensions. Broadcast joins eliminate expensive shuffle operations when joining large datasets with smaller lookup tables. Predicate pushdown filters data at source systems, reducing network transfer and processing overhead. Column pruning removes unnecessary fields early in transformation pipelines. Adaptive query execution automatically adjusts join strategies and partition counts based on runtime statistics. Caching intermediate results prevents redundant computations in complex transformation chains. Bucketing strategies pre-sort data for efficient joins and aggregations. Connection pooling reduces establishment overhead for database connections. Memory tuning balances executor memory allocation between storage and computation needs.
Implementing Data Security and Compliance
Encryption at Rest and in Transit
AWS Glue automatically encrypts data using server-side encryption with AWS KMS keys. Configure custom KMS keys for enhanced control over encryption policies. Enable SSL/TLS for data in transit between Glue jobs and data sources. Set up CloudTrail encryption for comprehensive audit logging. Use AWS Secrets Manager integration to protect database credentials and API keys within your ETL workflows.
Access Control and Audit Trails
Implement granular IAM policies to restrict Glue job execution and data catalog access based on user roles. Create service-linked roles with minimal required permissions for production ETL operations. CloudTrail captures all Glue API calls, providing detailed audit trails for compliance reporting. Set up VPC endpoints to keep data traffic within your private network and prevent unauthorized external access to sensitive datasets.
GDPR and Regulatory Compliance Features
AWS Glue supports data classification tags and metadata management for GDPR compliance tracking. Use built-in data profiling to identify personally identifiable information across datasets. Configure data retention policies through Glue catalog metadata to automate compliance workflows. Implement data masking and anonymization techniques within Glue transformations. Lake Formation integration provides fine-grained access controls and data governance capabilities required for regulatory audits and compliance reporting frameworks.
Advanced Features for Production Workloads
Custom transformations with PySpark and Scala
AWS Glue jobs support custom PySpark and Scala transformations that go beyond built-in functions. You can import external libraries, write user-defined functions (UDFs), and implement complex business logic directly in your ETL scripts. This flexibility lets you handle unique data transformation requirements while maintaining the scalability of AWS Glue’s serverless architecture.
Real-time streaming data processing
AWS Glue streaming jobs process real-time data from sources like Kinesis Data Streams and Amazon MSK. These jobs use micro-batching to handle continuous data flows with low latency. You can set up streaming ETL pipelines that automatically scale based on incoming data volume, making them perfect for production workloads that need immediate data processing and near real-time analytics.
Machine learning integration capabilities
Glue integrates seamlessly with SageMaker and other AWS ML services to embed machine learning models directly into your ETL pipeline. You can perform feature engineering, data preprocessing, and model inference as part of your data transformation process. This integration enables ML-powered data quality checks, anomaly detection, and predictive transformations within your production ETL workflows.
Cross-region data replication strategies
Production-grade ETL AWS Glue pipelines often require cross-region data replication for disaster recovery and compliance. You can configure Glue jobs to replicate processed data across multiple AWS regions using S3 cross-region replication or custom replication logic. This approach ensures data availability and meets regulatory requirements while maintaining consistent data processing across geographic locations.
Monitoring and Troubleshooting Production Pipelines
CloudWatch Metrics and Alerting Setup
Setting up comprehensive monitoring for your AWS Glue ETL pipeline starts with CloudWatch metrics integration. Configure custom metrics to track job success rates, data processing volumes, and execution times across all your production workflows. Create automated alerts for critical thresholds like job failures, memory utilization spikes, and unexpected data volume changes. Set up SNS notifications to immediately alert your team when pipelines encounter issues, enabling rapid response to production incidents.
Job Performance Analysis and Optimization
Performance optimization requires deep analysis of Glue job execution patterns and resource consumption. Monitor DPU (Data Processing Unit) utilization to identify over-provisioned or under-provisioned jobs that impact cost efficiency. Analyze job duration trends to spot gradually degrading performance before it affects downstream systems. Use CloudWatch Insights to query execution logs and identify bottlenecks in data transformations. Optimize partition strategies and file sizes based on processing patterns to improve overall pipeline throughput and reduce execution costs.
Common Failure Scenarios and Resolution Strategies
Production ETL troubleshooting focuses on systematic identification and resolution of recurring failure patterns. Schema evolution mismatches cause frequent job failures when source data structures change unexpectedly. Implement schema validation checks and flexible parsing logic to handle these variations gracefully. Memory errors typically occur during large dataset processing – resolve by adjusting worker configurations or implementing data chunking strategies. Connection timeouts with data sources require retry mechanisms and connection pooling optimization. Duplicate data processing issues need idempotent job designs with proper checkpointing and state management to ensure data consistency across pipeline restarts.
Building production-grade ETL pipelines with AWS Glue requires careful attention to architecture, security, and monitoring. From setting up a robust data catalog to implementing proper schema management, each component plays a crucial role in creating reliable data processing workflows. The key lies in designing scalable job architectures that can handle enterprise-level workloads while maintaining data quality and compliance standards.
Ready to transform your data processing capabilities? Start by establishing a solid foundation with proper environment configuration and security protocols. Then gradually implement advanced monitoring and troubleshooting practices to ensure your pipelines run smoothly in production. Remember, successful ETL implementation isn’t just about moving data—it’s about creating a reliable, secure, and scalable system that your entire organization can depend on for critical business insights.









