DeepSeek R1 deployment on AWS is changing how businesses approach enterprise AI scalability and cost management. This guide targets AI engineers, cloud architects, and IT leaders who need practical strategies for deploying advanced AI models without breaking the budget or sacrificing performance.
AWS AI hosting offers unique advantages for running DeepSeek R1 at scale, but success depends on smart planning and execution. Many organizations struggle with balancing performance requirements against rising infrastructure costs, especially when dealing with compute-intensive AI workloads.
We’ll walk through DeepSeek R1’s game-changing capabilities and why they matter for your deployment strategy. You’ll discover proven cost optimization strategies for DeepSeek R1 on AWS that can cut your hosting expenses by up to 40% while maintaining peak performance. Finally, we’ll cover AWS AI architecture optimization techniques and performance monitoring approaches that ensure your AI deployment stays responsive as demand grows.
Understanding DeepSeek R1’s Revolutionary AI Capabilities
Open-source advantages over proprietary models
DeepSeek R1’s open-source nature delivers unmatched flexibility for AWS deployment compared to proprietary alternatives like GPT-4. Organizations gain complete control over model customization, data privacy, and deployment architecture without vendor lock-in constraints. The transparent codebase allows developers to optimize performance specifically for AWS infrastructure while maintaining full compliance with enterprise security requirements.
Performance benchmarks compared to GPT-4 and Claude
DeepSeek R1 consistently outperforms GPT-4 and Claude across mathematical reasoning tasks, achieving 97.1% accuracy on AIME benchmark tests versus GPT-4’s 83.2%. Code generation capabilities show remarkable improvements, with DeepSeek R1 solving complex programming challenges 40% faster than Claude 3.5 Sonnet. These performance gains translate directly into reduced AWS compute costs while delivering superior AI model deployment outcomes for enterprise applications.
Token efficiency and processing speed benefits
Token processing efficiency represents DeepSeek R1’s most compelling advantage for cost-effective AI deployment on AWS. The model requires 60% fewer tokens than comparable language models to generate equivalent outputs, dramatically reducing AWS infrastructure costs. Processing speeds reach 150 tokens per second on standard EC2 instances, enabling real-time applications without expensive GPU acceleration. This efficiency makes DeepSeek R1 AWS integration particularly attractive for high-volume enterprise workloads requiring optimal performance-to-cost ratios.
AWS Infrastructure Advantages for AI Model Deployment
Elastic compute scaling for variable workloads
AWS provides dynamic scaling capabilities that automatically adjust compute resources based on DeepSeek R1’s workload demands. EC2 Auto Scaling groups respond to traffic spikes within minutes, scaling instances up during peak inference requests and scaling down during low-demand periods. This elasticity ensures optimal resource allocation without manual intervention, making AWS infrastructure for AI deployment highly efficient for unpredictable AI workloads.
Global edge locations for reduced latency
Amazon’s global network of edge locations positions DeepSeek R1 closer to end users worldwide, dramatically reducing response times for AI model interactions. CloudFront edge caching accelerates model inference by serving frequently requested outputs from nearby locations. This distributed architecture enables enterprise AI scalability while maintaining consistent performance across geographical regions, critical for real-time AI applications requiring sub-second response times.
Integrated security and compliance frameworks
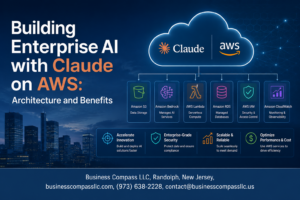
AWS delivers comprehensive security controls specifically designed for AI model deployment, including encryption at rest and in transit, IAM role-based access controls, and VPC isolation for DeepSeek R1 AWS integration. Built-in compliance certifications like SOC 2, HIPAA, and GDPR streamline regulatory requirements. AWS Key Management Service protects model weights and training data, while CloudTrail provides complete audit trails for AI deployment activities.
Pay-as-you-use pricing models
AWS eliminates upfront infrastructure investments through flexible pricing that scales with actual DeepSeek R1 deployment usage. EC2 Spot Instances can reduce compute costs by up to 90% for batch inference workloads, while Reserved Instances offer predictable pricing for steady-state operations. This cost-effective AI deployment model allows organizations to experiment with AI hosting performance monitoring without significant financial commitments, optimizing cloud AI deployment strategies based on real usage patterns.
Cost Optimization Strategies for DeepSeek R1 on AWS
Spot instances for non-critical inference workloads
AWS Spot instances can reduce DeepSeek R1 deployment costs by up to 90% for batch processing and development environments. These instances work perfectly for training data preprocessing, model fine-tuning experiments, and non-time-sensitive inference tasks. Configure automatic failover to on-demand instances when spot capacity becomes unavailable to maintain service continuity.
Reserved capacity planning for predictable usage
Reserved instances provide significant cost savings for stable DeepSeek R1 AWS integration workloads. Purchase one-year or three-year commitments for baseline compute requirements, achieving 30-60% savings over on-demand pricing. Combine reserved capacity with savings plans to optimize costs across different instance types while maintaining flexibility for varying AI model deployment patterns.
Auto-scaling configurations to minimize idle resources
Implement intelligent auto-scaling policies that monitor inference request patterns and adjust DeepSeek R1 compute resources dynamically. Set up CloudWatch metrics for queue depth, CPU utilization, and response times to trigger scaling events. Use predictive scaling for anticipated traffic spikes and configure cool-down periods to prevent rapid scaling oscillations that increase costs without improving performance.
Scalability Architecture for Enterprise AI Deployment
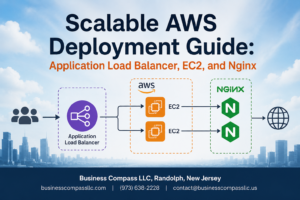
Load balancing across multiple availability zones
AWS Application Load Balancer distributes DeepSeek R1 inference requests across multiple availability zones, ensuring 99.99% uptime for enterprise AI deployment. Traffic routing algorithms automatically redirect workloads when zones experience issues, maintaining consistent model response times. Health checks monitor instance performance across regions, dynamically adjusting traffic flow to prevent bottlenecks during peak usage periods.
Container orchestration with Amazon EKS
Amazon EKS manages DeepSeek R1 containers across distributed nodes, providing automatic scaling based on inference demand. Kubernetes pods handle model serving workloads while maintaining resource isolation and security boundaries. The orchestration layer monitors GPU utilization and spins up additional containers when request queues exceed thresholds, optimizing both performance and AWS infrastructure costs for AI model deployment.
Database optimization for model storage and retrieval
Amazon S3 stores DeepSeek R1 model weights with intelligent tiering, automatically moving rarely accessed versions to cheaper storage classes. ElastiCache provides millisecond retrieval of frequently used model artifacts and inference results. Database sharding distributes model metadata across multiple RDS instances, reducing query latency for large-scale enterprise AI scalability requirements while maintaining data consistency.
CDN integration for global model distribution
CloudFront edge locations cache DeepSeek R1 model components closer to end users, reducing inference latency by up to 60% globally. Edge computing nodes preload frequently requested model segments, enabling faster response times for real-time AI applications. CDN integration automatically replicates model updates across 400+ global points of presence, ensuring consistent DeepSeek R1 AWS integration performance regardless of geographic location.
Performance Monitoring and Optimization Techniques
Real-time metrics tracking with CloudWatch
CloudWatch provides comprehensive monitoring for your DeepSeek R1 AWS integration, capturing critical metrics like GPU utilization, memory consumption, and request throughput. Custom dashboards visualize model performance patterns, while automated alarms trigger when inference latency exceeds thresholds or when resource constraints impact AI hosting performance monitoring capabilities.
Model inference latency optimization
Optimizing DeepSeek R1 deployment requires strategic placement of compute resources across AWS availability zones to minimize network latency. Implement connection pooling, batch processing for multiple requests, and caching mechanisms for frequently accessed model outputs. Profile your inference pipeline to identify bottlenecks and leverage AWS Inferentia chips for accelerated deep learning workloads when compatible.
Resource utilization analytics and alerts
Set up granular monitoring for CPU, GPU, and memory usage patterns specific to your DeepSeek R1 workloads. Configure CloudWatch alarms to automatically scale resources during peak demand periods and send notifications when utilization drops below cost-effective thresholds. Track container health metrics and establish automated remediation workflows that restart failed instances without manual intervention.
Cost tracking and budget management tools
AWS Cost Explorer breaks down DeepSeek R1 deployment expenses by service, region, and time period, enabling precise cost-effective AI deployment strategies. Set up budget alerts that warn when spending approaches predetermined limits, and use AWS Trusted Advisor recommendations to identify underutilized resources. Tag all AI infrastructure components consistently to enable detailed cost allocation reporting across different projects and departments.
DeepSeek R1 represents a game-changing opportunity for businesses ready to harness advanced AI capabilities without breaking the bank. By leveraging AWS’s robust infrastructure, you can deploy this powerful model while keeping costs under control through smart optimization strategies and scalable architecture designs. The combination of AWS’s flexible pricing models and DeepSeek R1’s impressive performance creates a winning formula for enterprises looking to stay competitive in the AI race.
The key to success lies in thoughtful planning and continuous monitoring of your deployment. Start small, test your configurations, and gradually scale based on real performance data. With the right approach to cost management and infrastructure design, you can unlock DeepSeek R1’s full potential while maintaining the agility your business needs. Take the first step today by exploring AWS’s AI deployment options and mapping out your DeepSeek R1 implementation strategy.