AWS Machine Learning Visualized: Understand the Essentials Fast
AWS machine learning doesn’t have to be overwhelming. This visual guide breaks down complex concepts into digestible, actionable insights for developers, data scientists, and business professionals ready to harness cloud machine learning power.
You’ll discover the core AWS ML services that actually matter for your projects, from SageMaker’s end-to-end capabilities to specialized AWS AI services. We’ll walk through a practical visual learning framework that maps out machine learning architecture in ways that stick.
Plus, you’ll get hands-on implementation examples with step-by-step visual walkthroughs that turn theory into working solutions. By the end, you’ll know exactly which AWS ML services to choose and how to set them up for real business impact.
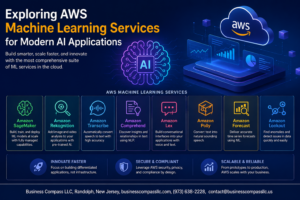
Core AWS Machine Learning Services That Drive Business Value
Amazon SageMaker for End-to-End ML Workflows
Amazon SageMaker transforms complex machine learning development into a streamlined process that handles everything from data preparation to model deployment. This comprehensive AWS ML service eliminates the infrastructure headaches that typically slow down data science teams, letting you focus on building and training models instead of managing servers. SageMaker’s visual interface makes it easy to track experiments, compare model performance, and collaborate with team members without writing extensive code. The platform automatically scales your training jobs and provides built-in algorithms for common use cases like recommendation systems and fraud detection. When you’re ready to deploy, SageMaker handles the heavy lifting of creating endpoints that can serve predictions to millions of users with just a few clicks.
Amazon Rekognition for Instant Image and Video Analysis
Amazon Rekognition brings computer vision capabilities to your applications without requiring deep learning expertise or custom model training. This powerful AWS AI service can identify objects, people, text, scenes, and activities in images and videos with remarkable accuracy. Businesses use Rekognition to automatically moderate content, verify user identities through facial recognition, and extract valuable insights from visual content at scale. The service integrates seamlessly with existing workflows through simple API calls, making it perfect for e-commerce platforms that need to categorize product images or security systems that require real-time monitoring. Rekognition also excels at detecting inappropriate content, helping companies maintain brand safety across user-generated content.
Amazon Comprehend for Automated Text Processing
Amazon Comprehend unlocks hidden insights from text data using natural language processing that understands context and meaning beyond simple keyword matching. This AWS ML service analyzes customer reviews, social media posts, support tickets, and documents to extract sentiment, key phrases, entities, and topics automatically. Companies leverage Comprehend to monitor brand reputation, route customer inquiries to appropriate departments, and discover trending topics in their industry. The service supports multiple languages and can identify personally identifiable information (PII) to help with compliance requirements. Comprehend’s custom classification features allow you to train models specific to your business domain, making text analysis more accurate and relevant to your unique needs.
Amazon Forecast for Accurate Business Predictions
Amazon Forecast combines time-series data with machine learning algorithms to generate highly accurate demand predictions that drive better business decisions. This AWS ML service goes beyond traditional forecasting methods by automatically incorporating external factors like weather patterns, holidays, and economic indicators that influence your business metrics. Retailers use Forecast to optimize inventory levels, while energy companies predict consumption patterns to manage resource allocation efficiently. The service handles missing data points and seasonal variations automatically, producing forecasts that account for complex patterns humans might miss. Forecast delivers predictions through easy-to-interpret visualizations and confidence intervals, helping stakeholders understand both the expected outcomes and potential risks in their planning decisions.
Visual Learning Framework for AWS ML Architecture
Data Pipeline Visualization from Raw to Processed
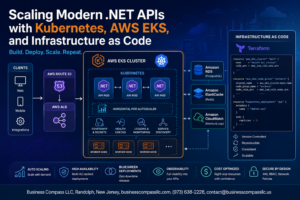
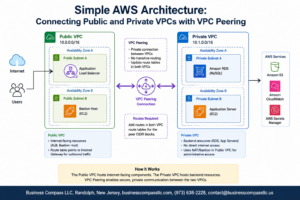
AWS machine learning data pipelines transform chaotic raw information into structured, analysis-ready datasets through a clear visual flow. Start with Amazon S3 as your data lake, where unprocessed files from various sources accumulate. AWS Glue crawlers automatically discover and catalog this data, creating a searchable metadata repository. The transformation stage uses AWS Glue ETL jobs or Amazon EMR to clean, normalize, and enrich your data. Amazon Kinesis handles real-time streaming data, while AWS Lambda functions trigger processing workflows based on specific events. The processed data flows into Amazon Redshift for analytics or back to S3 in optimized formats like Parquet. This visual pipeline shows how each AWS service connects, making data preparation transparent and manageable for your machine learning projects.
Model Training and Deployment Flow Charts
Amazon SageMaker provides the backbone for AWS ML visualization, orchestrating the complete model lifecycle from training to production deployment. The flow begins with data preparation in SageMaker Processing, where your clean datasets undergo feature engineering and splitting. Training jobs spin up managed compute instances that run your algorithms using built-in frameworks or custom containers. SageMaker Experiments tracks multiple training runs, comparing metrics and hyperparameters through intuitive dashboards. Model artifacts get stored in S3, then registered in the SageMaker Model Registry for version control. Deployment options branch into real-time endpoints for immediate predictions, batch transform jobs for large-scale inference, or multi-model endpoints for cost optimization. The visual workflow clearly demonstrates how SageMaker guide principles connect each stage, enabling rapid iteration and seamless transitions from development to production environments.
Real-Time Inference Architecture Diagrams
Real-time AWS machine learning architecture creates responsive prediction systems that handle incoming requests within milliseconds. Application traffic flows through Amazon API Gateway, which routes requests to Lambda functions or directly to SageMaker endpoints. Auto-scaling groups ensure your inference infrastructure adapts to demand fluctuations automatically. Amazon ElastiCache provides ultra-fast response times by caching frequently requested predictions. CloudWatch monitors performance metrics, triggering alerts when latency exceeds thresholds. Load balancers distribute traffic across multiple availability zones, ensuring high availability for critical applications. The architecture diagram reveals how these components work together, showing data paths from user requests through preprocessing, model inference, and response delivery. This visual representation helps you understand bottlenecks and optimization opportunities in your cloud machine learning deployment strategy.
Quick Setup Guide for Your First AWS ML Project
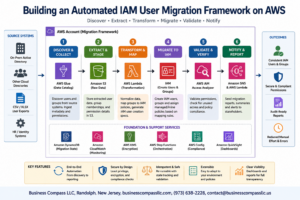
Essential IAM Roles and Permissions Configuration
Setting up your first AWS ML project starts with proper IAM configuration. Create a dedicated service role for SageMaker with AmazonSageMakerFullAccess policy attached. Add S3 bucket permissions for data access and CloudWatch logging capabilities. Configure user groups with restricted ML service permissions to maintain security while enabling development workflows.
Data Storage Strategy with S3 and Database Integration
Choose S3 as your primary data lake for training datasets, using intelligent tiering for cost optimization. Structure your buckets with clear prefixes like /raw-data/, /processed/, and /model-artifacts/. Connect RDS or DynamoDB for real-time inference data storage. Enable versioning on critical buckets to track data lineage and support model reproducibility across your AWS machine learning pipeline.
Cost-Effective Resource Selection and Management
Start with ml.t3.medium instances for initial experimentation and scale to ml.m5.large for production training jobs. Use Spot instances for non-critical batch processing to reduce costs by up to 70%. Implement automatic scaling policies and set CloudWatch billing alerts at $50 increments. Choose the right SageMaker pricing model – on-demand for development, reserved instances for predictable workloads, and serverless inference endpoints for sporadic usage patterns.
Hands-On Implementation Examples with Visual Walkthroughs
Building a Customer Sentiment Analysis Pipeline
Start by setting up Amazon Comprehend to process customer feedback from multiple channels. Connect your data sources through AWS Lambda functions that automatically trigger sentiment analysis on incoming reviews, emails, and support tickets. Use SageMaker to build custom models when standard sentiment analysis needs refinement for industry-specific language. Create CloudWatch dashboards to visualize sentiment trends in real-time, helping teams respond quickly to negative feedback patterns. The pipeline processes thousands of customer interactions daily, providing actionable insights for product improvements.
Creating an Image Classification Model
Launch SageMaker Studio and select the built-in image classification algorithm for your computer vision project. Upload training images to S3 buckets with proper folder structures representing different categories. Configure hyperparameters including learning rate, batch size, and number of epochs through the SageMaker interface. Monitor training progress through visual metrics and validation accuracy graphs. Deploy your trained model to a real-time endpoint using SageMaker’s one-click deployment feature, enabling instant image predictions through API calls.
Deploying Automated Chatbot Solutions
Build intelligent chatbots using Amazon Lex combined with Lambda functions for complex business logic. Design conversation flows through the Lex console’s visual interface, defining intents, utterances, and slot types. Integrate with Amazon Connect for voice capabilities and DynamoDB for storing conversation context. Add natural language understanding through Amazon Comprehend to handle customer queries more effectively. Test your chatbot thoroughly using the built-in simulator before deploying to production channels like websites, mobile apps, or messaging platforms.
Setting Up Fraud Detection Systems
Implement Amazon Fraud Detector to analyze transaction patterns and identify suspicious activities in real-time. Upload historical transaction data including both legitimate and fraudulent examples to train machine learning models. Configure detection rules that combine ML predictions with business logic for comprehensive fraud prevention. Set up automated responses through Lambda functions that can block transactions, require additional verification, or alert security teams. Monitor detection accuracy through CloudWatch metrics and adjust thresholds based on false positive rates and business requirements.
Performance Optimization and Monitoring Made Simple
CloudWatch Metrics for ML Model Health Tracking
Monitor your AWS machine learning models effectively using CloudWatch’s comprehensive metrics dashboard. Track key performance indicators like inference latency, error rates, and model accuracy in real-time. Set up custom alarms for anomaly detection and receive instant notifications when your SageMaker endpoints experience performance degradation. CloudWatch provides detailed insights into endpoint utilization, helping you identify bottlenecks before they impact your applications. Create visual dashboards that display model health metrics alongside business KPIs for complete visibility into your machine learning operations.
Cost Optimization Strategies for ML Workloads
Control AWS ML costs through strategic resource management and intelligent instance selection. Use SageMaker’s spot instances for training jobs to reduce expenses by up to 90% without compromising model quality. Implement automatic model pruning and quantization techniques to decrease inference costs while maintaining accuracy. Schedule training jobs during off-peak hours and leverage reserved capacity for predictable workloads. Monitor data transfer costs between regions and optimize your data pipeline architecture to minimize unnecessary charges across your machine learning infrastructure.
Automated Scaling and Resource Management
Configure auto-scaling policies for your SageMaker endpoints to handle traffic spikes automatically while maintaining cost efficiency. Set up Application Auto Scaling to adjust instance counts based on real-time metrics like CPU utilization and request volume. Implement blue-green deployments for seamless model updates without service interruption. Use AWS Lambda functions to trigger scaling events based on custom business logic and seasonal patterns. Design your AWS ML architecture with elastic infrastructure that scales resources up during peak demand and scales down during quiet periods.
AWS machine learning doesn’t have to feel overwhelming when you break it down into digestible pieces. The core services like SageMaker, Comprehend, and Rekognition each solve specific business problems, and understanding their visual architecture helps you see exactly how data flows through your ML pipeline. With the right setup approach and monitoring tools in place, you can launch your first project faster than you might think.
Start small with one of the hands-on examples we covered, then gradually expand your ML capabilities as you get comfortable with the platform. The visual frameworks and optimization strategies we discussed will save you countless hours of trial and error. Pick a simple use case from your current workflow, spin up a basic model, and watch how quickly you can turn raw data into actionable insights that move your business forward.